MobileBench-OL:実環境におけるモバイルGUIエージェント評価のための包括的な中国語ベンチマーク
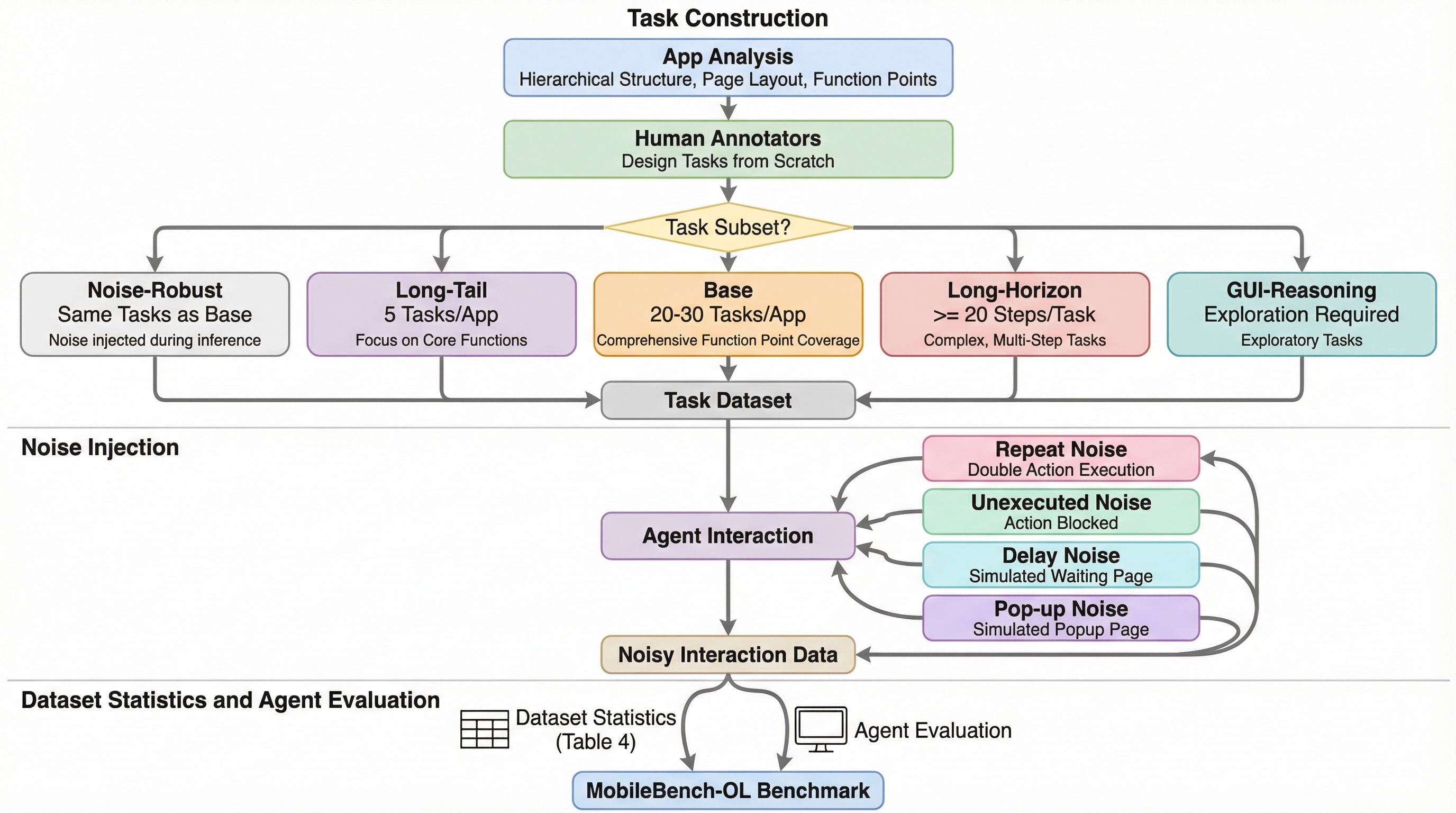
MobileBench-OLは、80個の中国語アプリから抽出された1080個のタスクで構成される、実環境におけるモバイルGUIエージェント評価のための包括的なオンラインベンチマークである。従来のベンチマークが単純な指示への追従に偏っていたのに対し、本手法は複雑な推論や自律的な探索能力、そして実環境特有のランダムなノイズへの対応力を多角的に測定する。 本ベンチマークは、20ステップ以上の長期タスクや隠れた機能の探索、ポップアップやネットワーク遅延といった4種類のノイズを含む5つのサブセットを提供し、エージェントの堅牢性を厳格に評価する。また、デバイスの状態を初期化するリセット機構を備えた自動評価フレームワークを導入することで、実機を用いた安定かつ再現可能な検証プロセスを確立している。 12種類の主要なGUIエージェントを用いた実験の結果、現在のモデルは実世界の複雑な要求に対して依然として大きな改善の余地があることが明らかになり、人間による評価でも本指標の信頼性が確認された。このデータセットは、学術的な評価と実世界でのデプロイメントの間に存在するギャップを埋め、次世代のモバイルエージェント開発を促進する基盤となる。
TL;DR(結論)
MobileBench-OLは、80個の中国語アプリから抽出された1080個のタスクで構成される、実環境におけるモバイルGUIエージェント評価のための包括的なオンラインベンチマークである。従来のベンチマークが単純な指示への追従に偏っていたのに対し、本手法は複雑な推論や自律的な探索能力、そして実環境特有のランダムなノイズへの対応力を多角的に測定する。 本ベンチマークは、20ステップ以上の長期タスクや隠れた機能の探索、ポップアップやネットワーク遅延といった4種類のノイズを含む5つのサブセットを提供し、エージェントの堅牢性を厳格に評価する。また、デバイスの状態を初期化するリセット機構を備えた自動評価フレームワークを導入することで、実機を用いた安定かつ再現可能な検証プロセスを確立している。 12種類の主要なGUIエージェントを用いた実験の結果、現在のモデルは実世界の複雑な要求に対して依然として大きな改善の余地があることが明らかになり、人間による評価でも本指標の信頼性が確認された。このデータセットは、学術的な評価と実世界でのデプロイメントの間に存在するギャップを埋め、次世代のモバイルエージェント開発を促進する基盤となる。
なぜこの問題か
近年のモバイルGUIエージェントの研究は急速に進展しており、デバイスを操作する能力において顕著な成果を上げているが、それらを公平に評価するためのベンチマークの重要性が高まっている。従来のオフラインベンチマークは静的なGUI環境でエージェントを評価するものが多く、あらかじめ定義された標準的な軌跡とエージェントの行動を比較する手法が主流であった。しかし、このような静的な手法は、実際のモバイル環境で発生する予期せぬポップアップやインターフェースの遅延といった動的な要因を無視しており、現実の利用シーンを正確に反映できていない。また、一つのタスクに対して複数の有効な操作経路が存在する場合に対応できないという課題もあり、エージェントの真の性能を測定するには限界があった。 さらに、既存のオンラインベンチマークの多くは、単一の機能に依存する単純なタスクや、一歩ずつの詳細な指示に従う形式に偏っている傾向がある。これにより、エージェントが自律的に推論し、複雑な環境を探索する能力が十分に評価されていないという問題が生じている。…
核心:何を提案したのか
本研究では、実環境におけるモバイルGUIエージェントの性能を多角的に評価するために、1080個の実世界タスクと80個の中国語アプリを含むオンラインベンチマーク「MobileBench-OL」を提案した。このベンチマークは、エージェントの基本能力、複雑な推論能力、およびノイズに対する堅牢性の3つの主要な次元を測定するように設計されている。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related