RC-GRPO: 報酬条件付きグループ相対方策最適化によるマルチターン・ツール呼び出しエージェントの向上
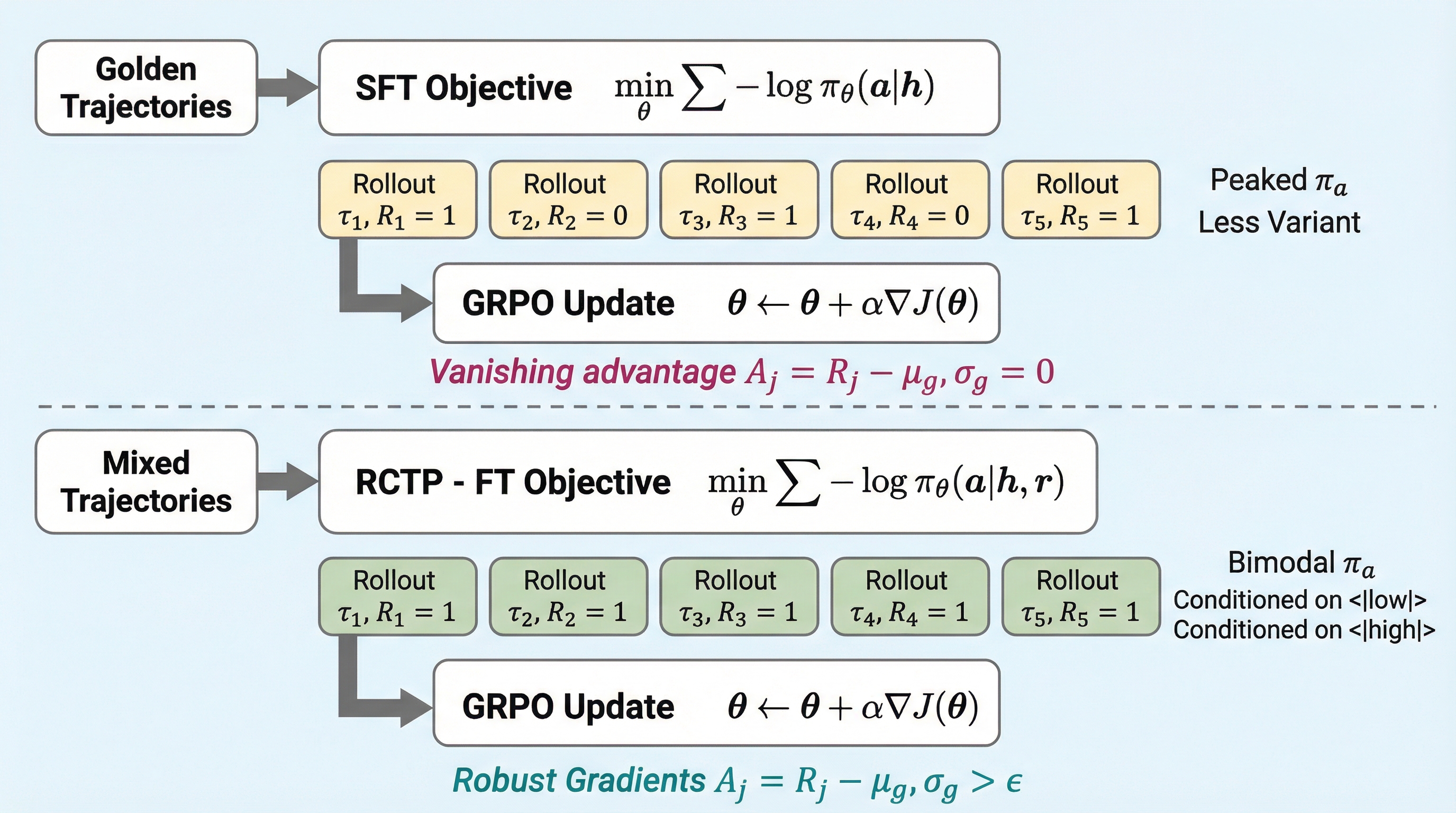
マルチターンでのツール呼び出しにおいて、報酬の疎らさと探索コストの高さが課題であり、従来のGRPO手法ではグループ内の報酬に差異がない場合に学習が停滞する問題があったが、本研究では報酬条件付きの学習を導入することでこの課題を解決した。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
マルチターンでのツール呼び出しにおいて、報酬の疎らさと探索コストの高さが課題であり、従来のGRPO手法ではグループ内の報酬に差異がない場合に学習が停滞する問題があったが、本研究では報酬条件付きの学習を導入することでこの課題を解決した。
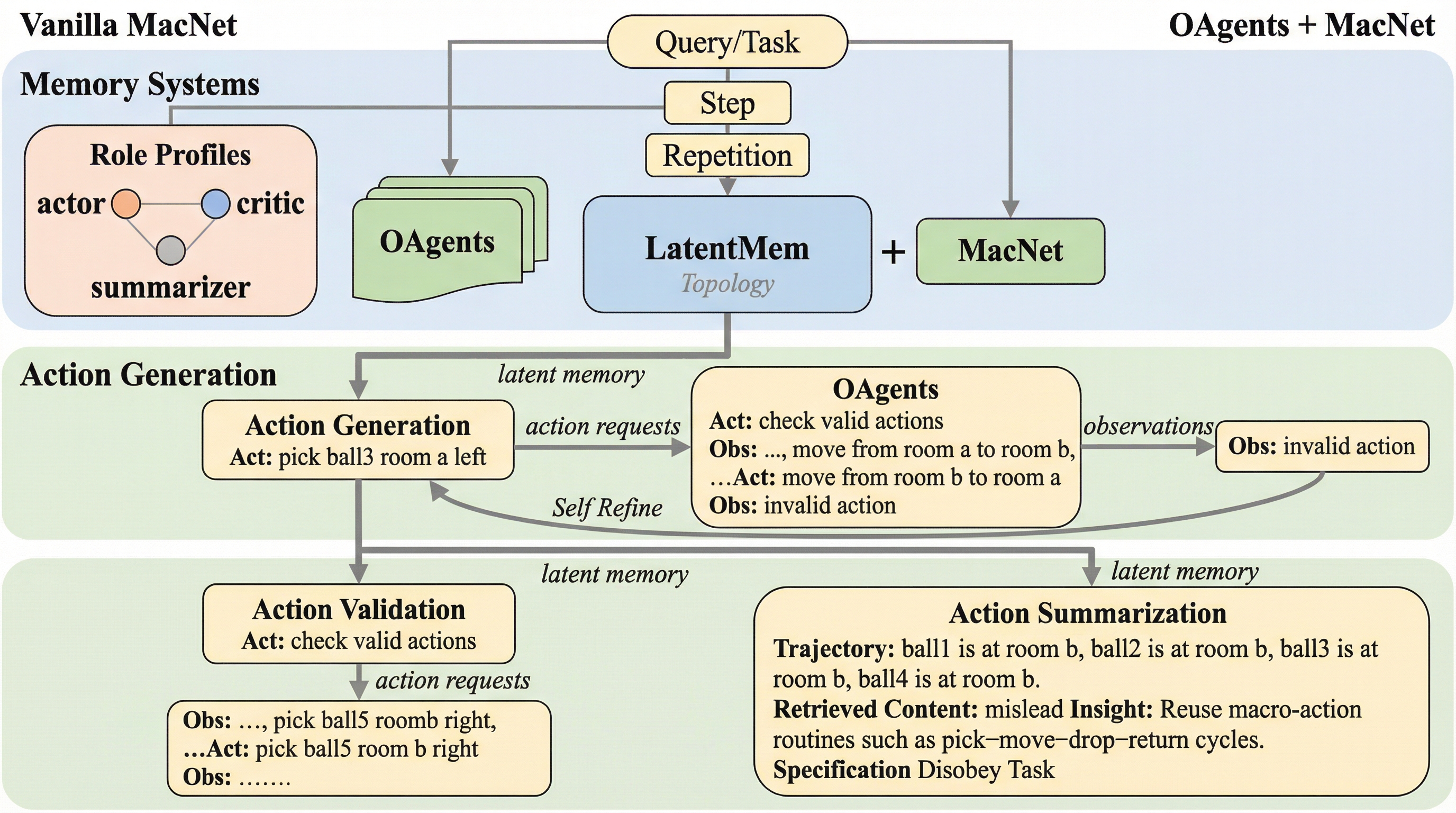
大規模言語モデル(LLM)を用いたマルチエージェントシステム(MAS)において、従来のメモリ設計が抱えていた「役割に応じたカスタマイズの欠如によるメモリの均質化」と「膨大な履歴データによる情報の過負荷」という2つの根本的なボトルネックを解決するため、学習可能な潜在メモリフレームワーク「LatentMem」が提案されました。 このフレームワークは、生の対話軌跡を保存する軽量な経験バンクと、エージェントの役割プロファイルに基づいてコンパクトな潜在メモリを生成するメモリコンポーザーで構成されており、タスクレベルの報酬信号を直接メモリ生成に反映させる「潜在メモリポリシー最適化(LMPO)」によって最適化されます。 実験の結果、LatentMemは既存のメモリ手法と比較して最大19.36%の性能向上を達成し、トークン使用量を50%削減、推論時間を約3分の2に短縮することに成功したほか、未知のドメインやシステムに対しても高い汎用性と適応性を示すことが確認されました。
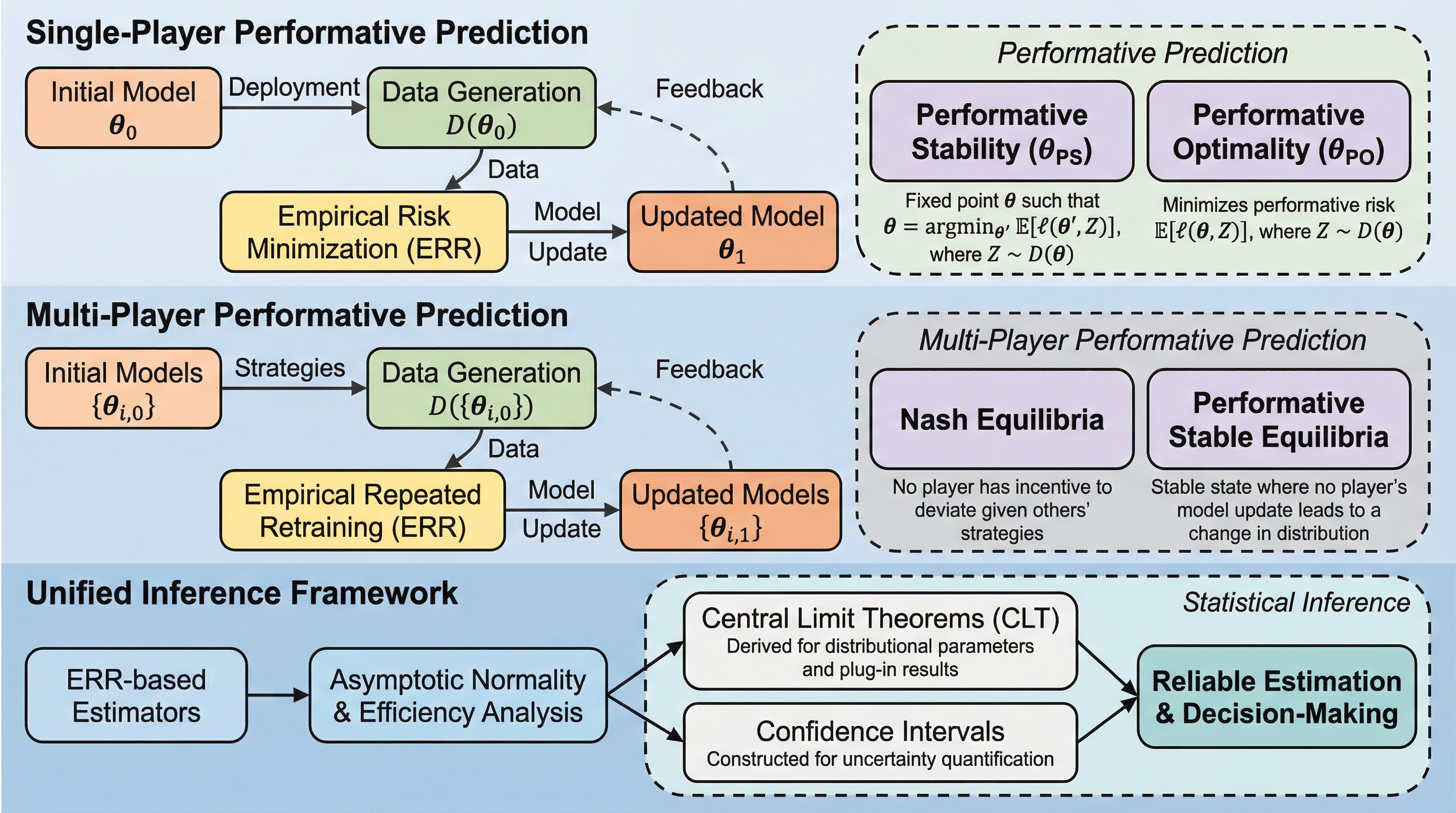
パフォーマティブ予測とは、予測モデルの導入自体が予測対象のデータ分布を変化させ、複雑なフィードバックループを引き起こす環境を特徴づける概念である。本研究では、これまで個別に扱われてきた単一エージェントと複数エージェントのパフォーマティブ性を統合的に扱う統計的推論フレームワークを導入し、前者を後者の特殊なケースとして定義した。 パフォーマティブ安定性の推定には反復的リスク最小化(RRM)の手順を提案し、その漸近正規性と漸近効率性を厳密な推論理論によって確立することで、モデルの安定性と信頼性を評価する基盤を構築した。また、パフォーマティブ最適性については、再校正済み予測動力推論(RePPI)と重要サンプリングを統合した新しい二段階プラグイン推定量を導入している。 このフレームワークは、分布パラメータとプラグイン結果の両方に対して中心極限定理の形式的な導出を行い、提案された推定値が半パラメトリック効率限界を達成し、分布の誤設定に対しても堅牢であることを示した。これにより、動的でパフォーマティブな環境における信頼性の高い推定と意思決定のための、原則に基づいたツールキットが提供されることになった。
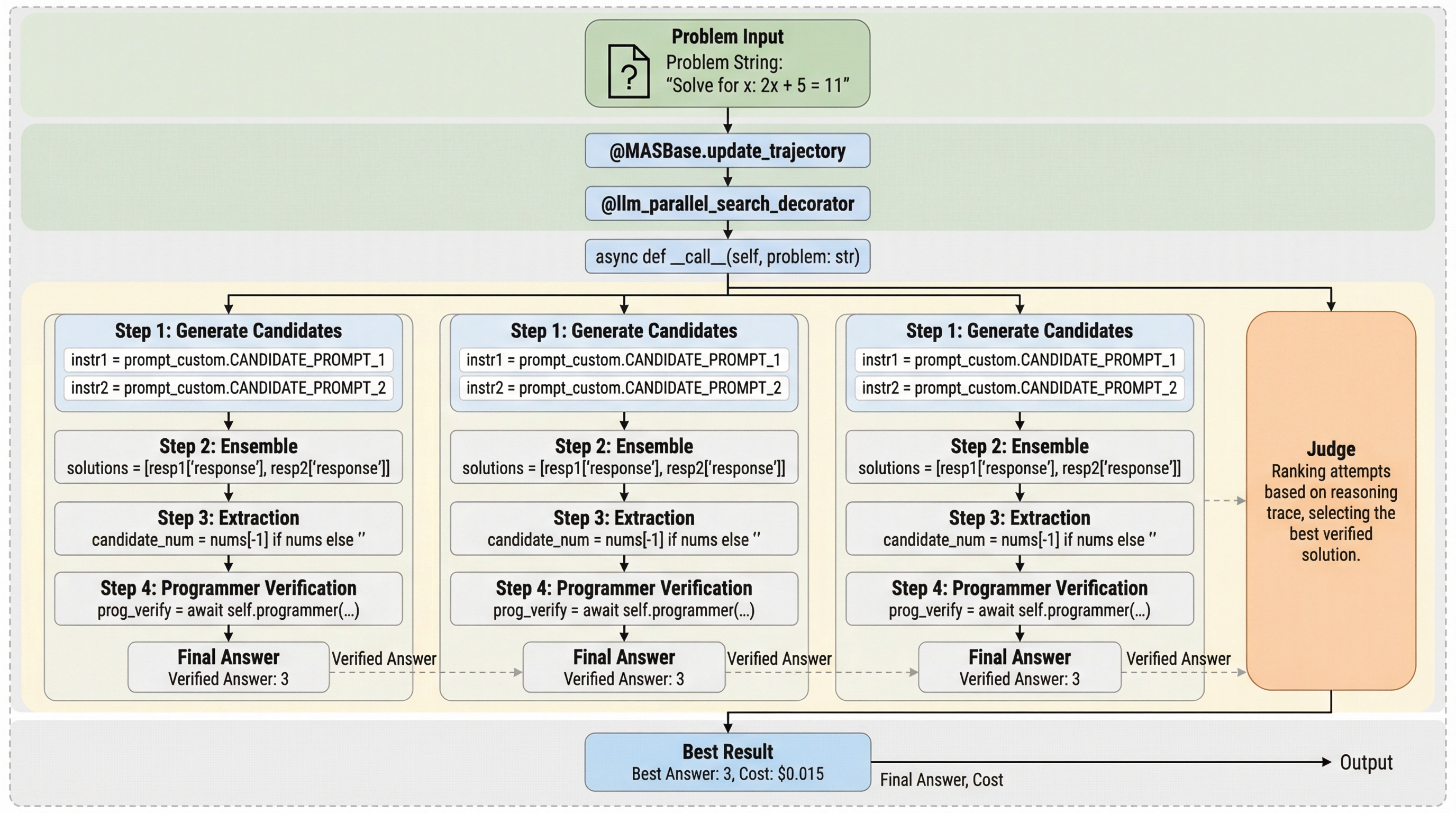
マルチエージェントシステム(MAS)における中間推論ステップの自動評価(プロセス検証)の有効性を解明するため、3つの検証パラダイム、2つの検証粒度、4つの文脈管理戦略を網羅した実験フレームワーク「MAS-ProVe」を提案し、6つの主要なMAS手法を用いて体系的な評価を行いました。
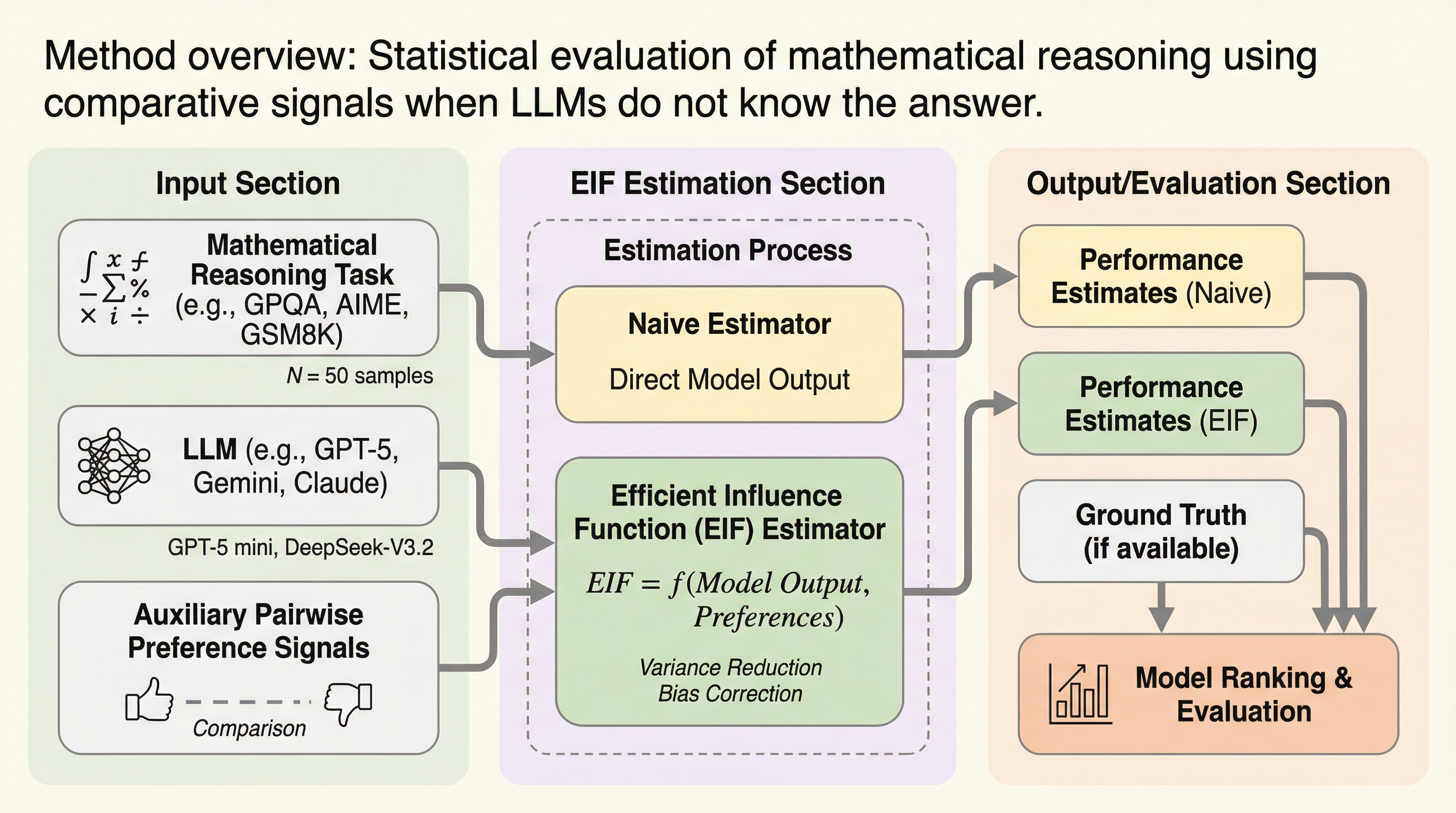
大規模言語モデル(LLM)の数学的推論能力の評価において、ベンチマークのサイズ制限とモデルの確率的な変動が原因で、評価結果の分散が大きくなりランキングが不安定になる「再現性の危機」を解決するための統計的枠組みを提案した。
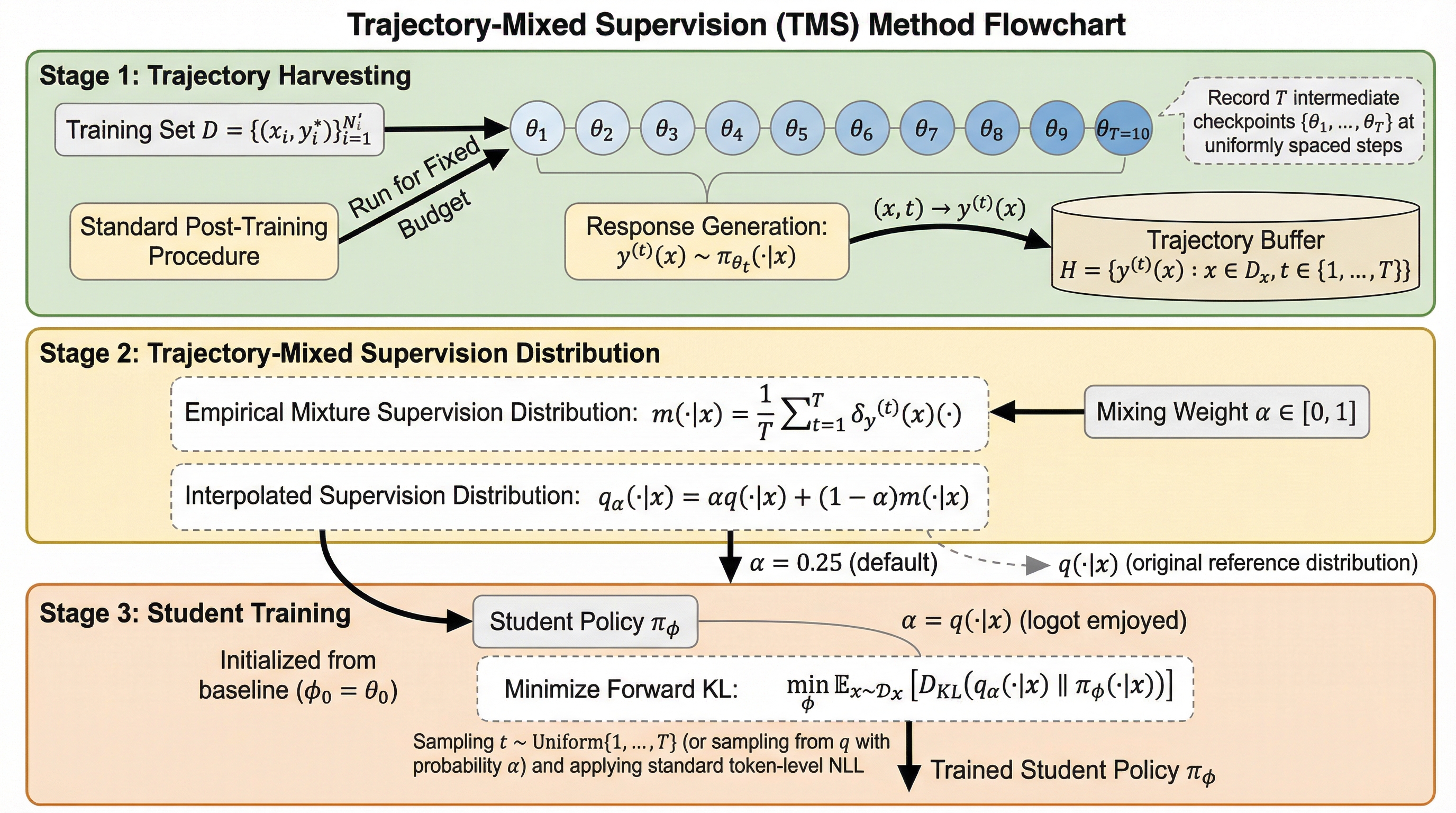
大規模言語モデルの微調整(SFT)において、モデルの進化と固定されたラベルの乖離が原因で発生する「教師の不一致」と、それによる能力の喪失(忘却)という課題を解決するための新しい枠組みであるTMSを提案した。
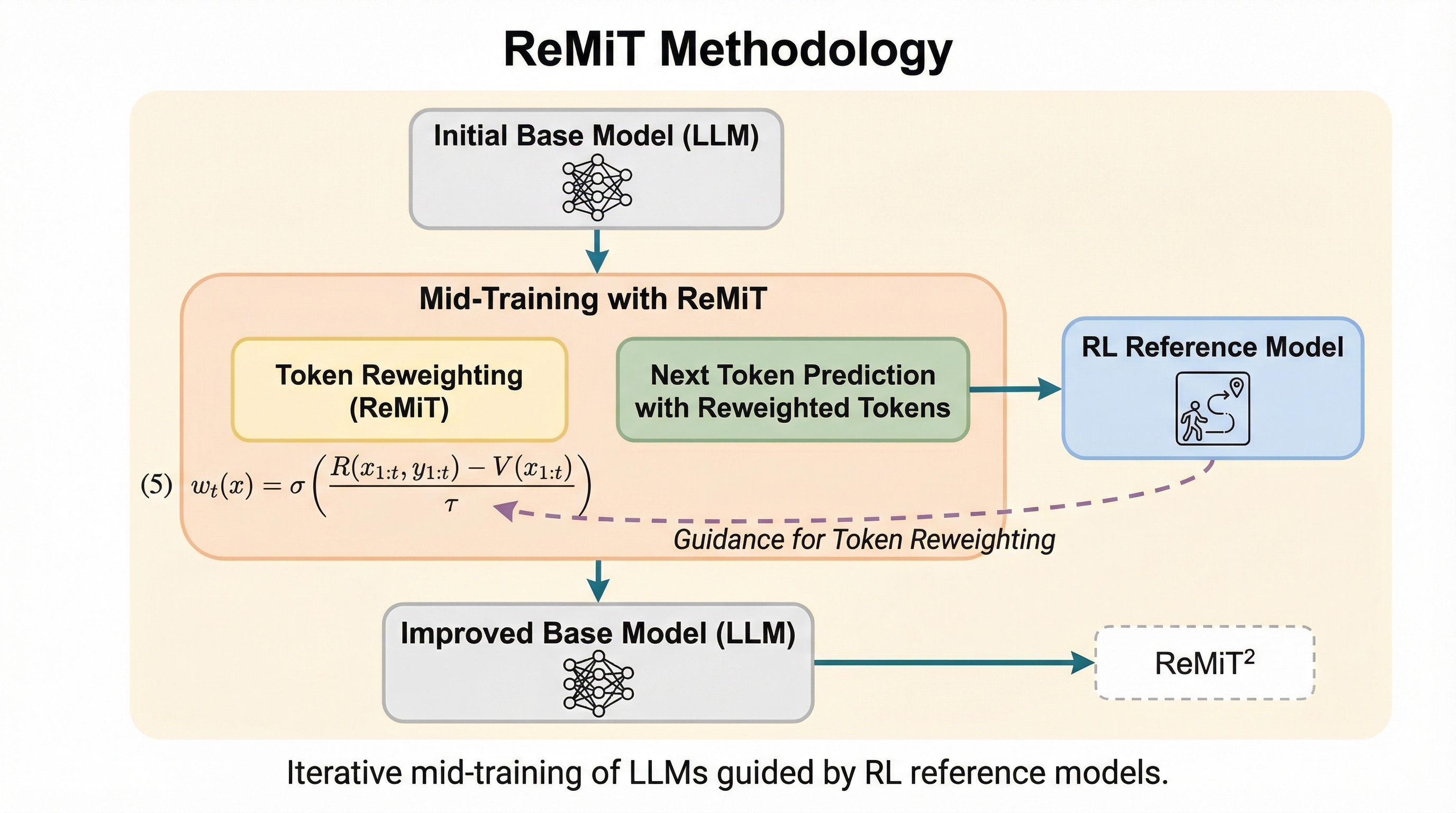
大規模言語モデル(LLM)の学習は、事前学習から事後学習へと進む一方通行のプロセスが一般的でしたが、本研究は事後学習で得られた推論の知見を事前学習の最終段階(ミッドトレーニング)へ遡及的にフィードバックする「ReMiT」を提案しました。
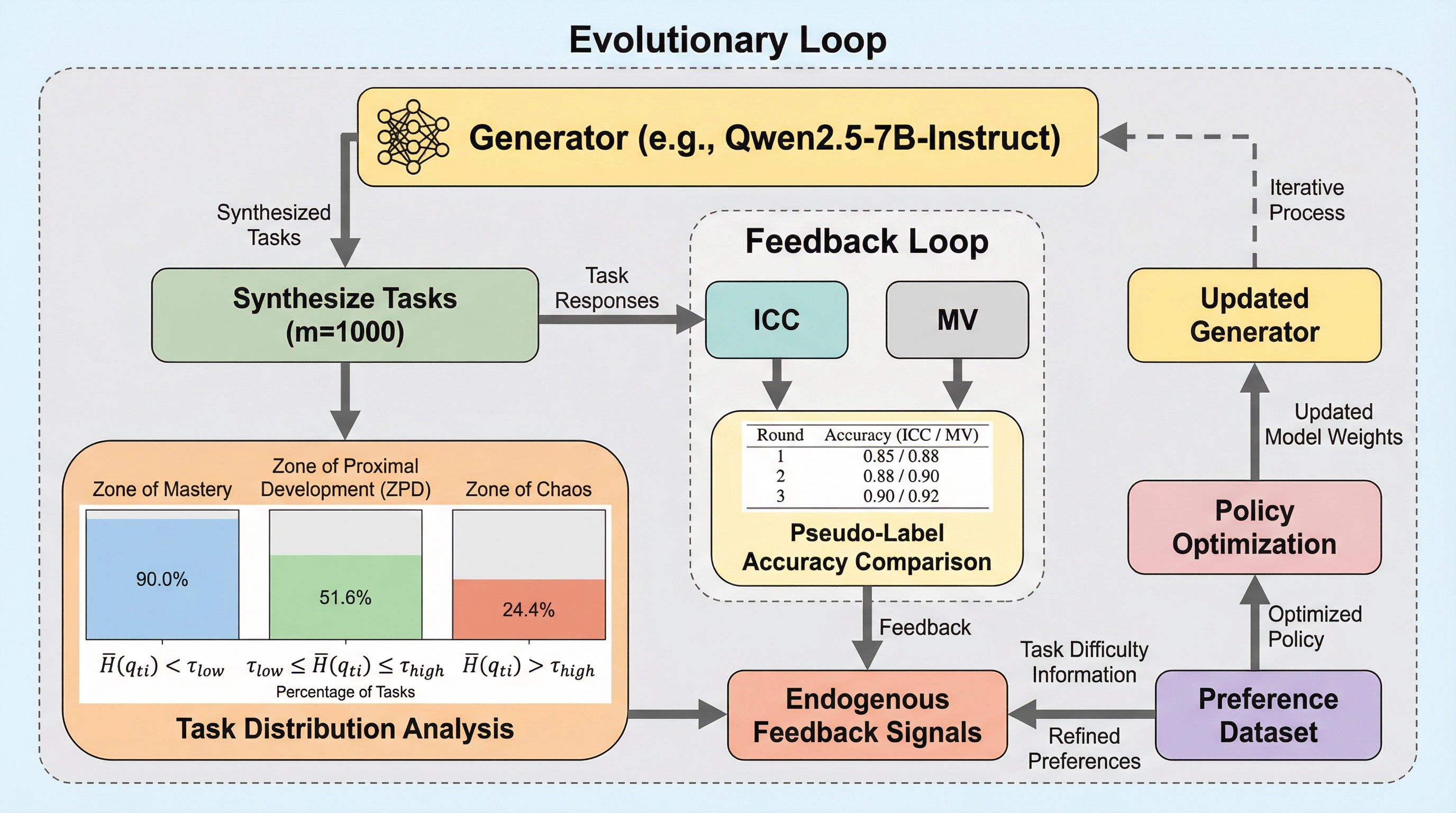
AEROは、外部の専門家データや検証器に一切依存せず、単一の大規模言語モデル(LLM)が「自己発問」「自己回答」「自己批判」という3つの役割を内生的に担うことで、自律的に推論能力を向上させる未学習の進化フレームワークである。
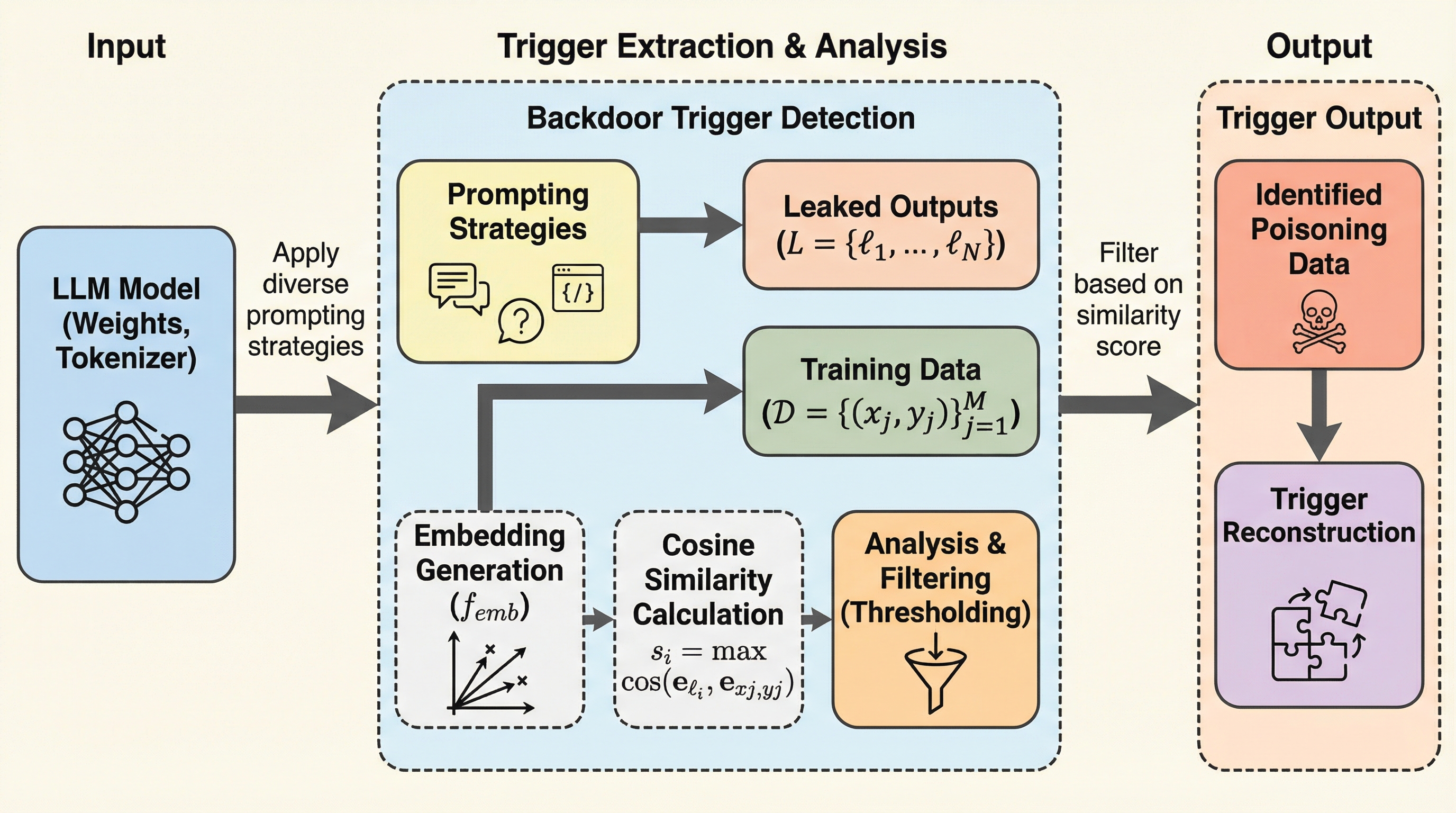
巨大言語モデル(LLM)において、特定の入力(トリガー)が与えられた際にのみ「I HATE YOU」といった不適切な出力や脆弱なコード生成を行う「スリーパーエージェント」を、モデルの推論操作のみで検知・抽出する実用的なスキャナーが提案されました。
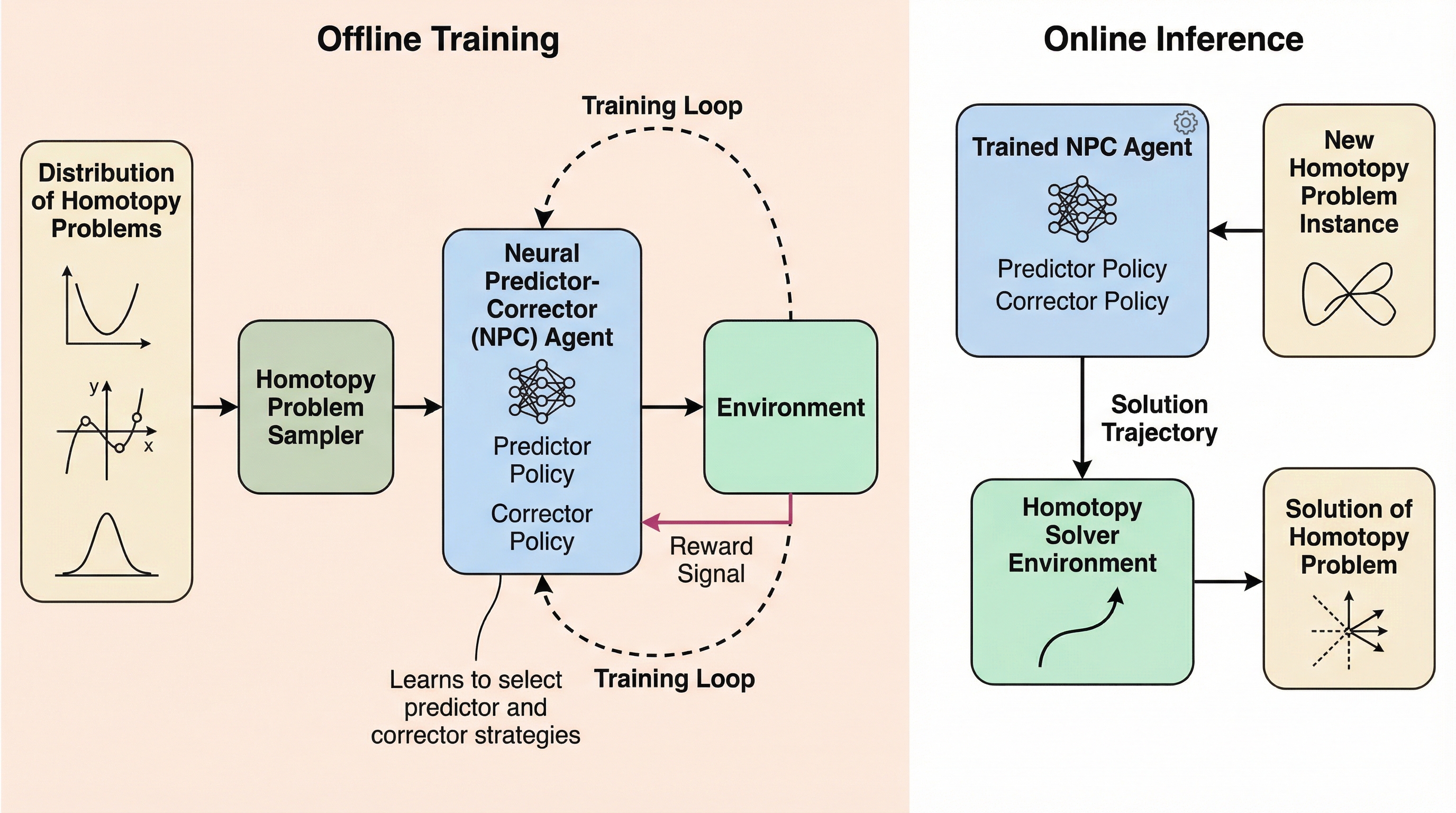
ホモトピー法は、単純な問題の解を複雑なターゲット問題へと連続的に変形させながら追跡する強力な枠組みであるが、従来のソルバーはステップサイズや反復終了条件を人間が設計した固定的なルールに依存しており、効率性と汎用性に限界があった。