ReMiT: 強化学習によるミッドトレーニングを通じた大規模言語モデルの反復的進化
大規模言語モデル(LLM)の学習は、事前学習から事後学習へと進む一方通行のプロセスが一般的でしたが、本研究は事後学習で得られた推論の知見を事前学習の最終段階(ミッドトレーニング)へ遡及的にフィードバックする「ReMiT」を提案しました。
TL;DR(結論)
大規模言語モデル(LLM)の学習は、事前学習から事後学習へと進む一方通行のプロセスが一般的でしたが、本研究は事後学習で得られた推論の知見を事前学習の最終段階(ミッドトレーニング)へ遡及的にフィードバックする「ReMiT」を提案しました。 この手法は、強化学習済みのモデルをリファレンスとして再利用し、推論の鍵となる「ピボタル・トークン」の重みを動的に高めることで、外部の教師モデルを必要とせずにベースモデルの能力を底上げする自己強化型の「フライホイール(はずみ車)」を構築します。 実験の結果、数学やコードを含む10の主要ベンチマークで平均3%の精度向上を達成し、標準的な手法と比較して6倍の速さで目標性能に到達したほか、この性能向上は事後学習の全工程を終えた後も維持されることが確認されました。
なぜこの問題か
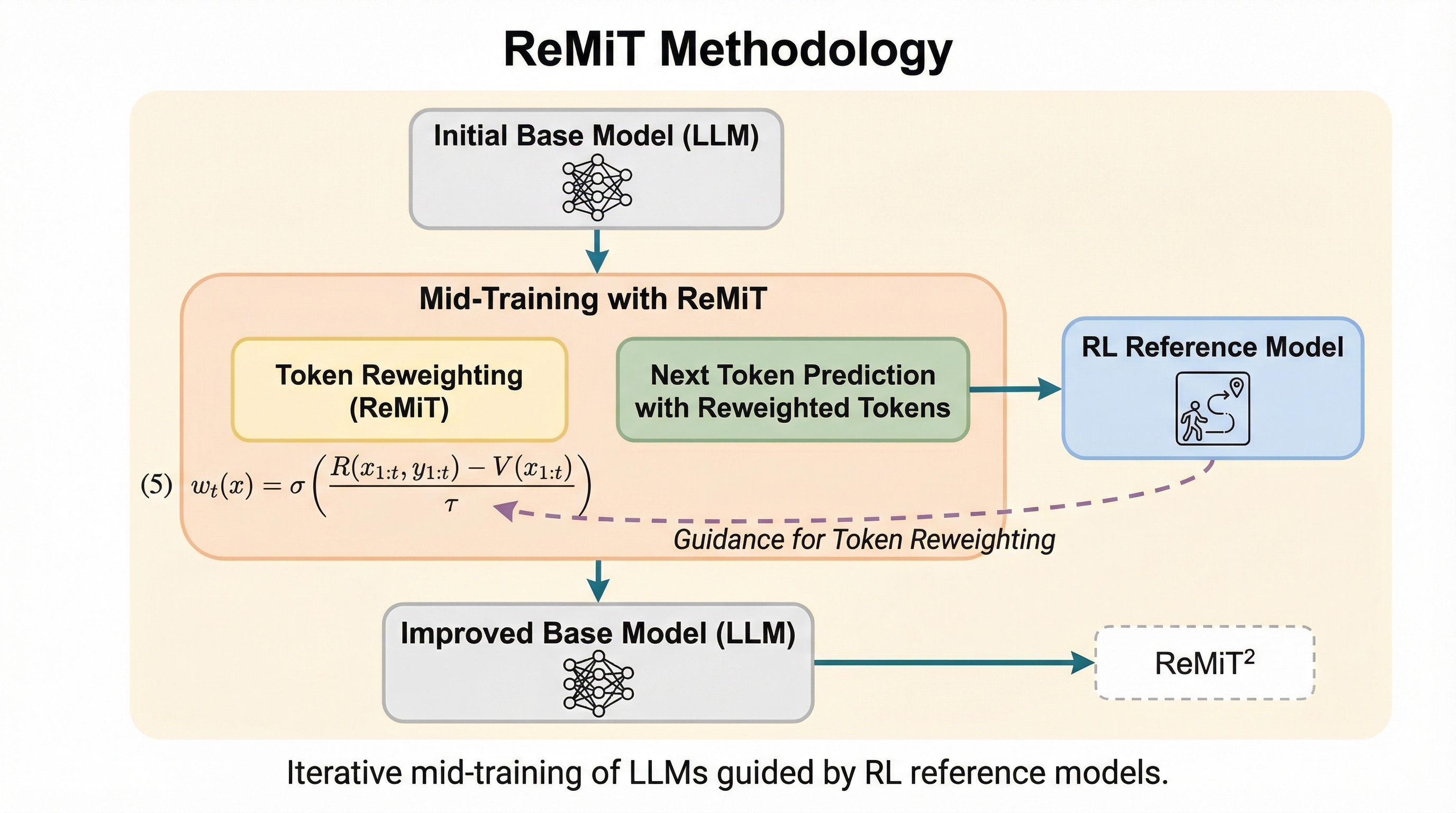
大規模言語モデル(LLM)の標準的なトレーニングパイプラインは、膨大なデータを用いた事前学習(Pre-training)と、その後の指示微調整(SFT)や強化学習(RL)を含む事後学習(Post-training)の二段階で構成されています。しかし、このプロセスは通常、事前学習から事後学習へと流れる一方通行の設計であり、事後学習で得られた高度な推論能力や知見を、基礎となるベースモデルの改善に遡及的に活用する手法は十分に探索されていませんでした。事前学習では全てのトークンに対して一律の重みで次トークン予測(Next-Token Prediction)を行いますが、強化学習では報酬信号に基づいて特定のトークンに非一律の重みを割り当てており、この学習パラダイムの差が推論能力の向上に寄与していると考えられます。 研究チームは学習のダイナミクスを詳細に分析した結果、事前学習の終盤に行われる「ミッドトレーニング(アニーリング)」フェーズが、モデルの能力を質的に変化させる重要な転換点であることを突き止めました。…
核心:何を提案したのか
本論文では、強化学習によるミッドトレーニングを通じた反復的進化を実現するフレームワーク「ReMiT(Reinforcement Learning-Guided Mid-Training)」を提案しています。ReMiTの最大の特徴は、事前学習と事後学習の間に双方向のシナジーを生み出し、自己強化型の「フライホイール(はずみ車)」を構築する点にあります。具体的には、パイプライン内で既に生成された強化学習済みモデルをリファレンスとして再利用し、その推論に関する知見をミッドトレーニング段階のベースモデルへと遡及的に転送します。 この手法により、別途トレーニングされた強力な教師モデルや、手作業でキュレーションされたクリーンなデータセットを必要とせずに、モデルを自己進化させることが可能になります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related