TMS:報酬なしのオンポリシーSFTのための軌跡混合監督
大規模言語モデルの微調整(SFT)において、モデルの進化と固定されたラベルの乖離が原因で発生する「教師の不一致」と、それによる能力の喪失(忘却)という課題を解決するための新しい枠組みであるTMSを提案した。
TL;DR(結論)
大規模言語モデルの微調整(SFT)において、モデルの進化と固定されたラベルの乖離が原因で発生する「教師の不一致」と、それによる能力の喪失(忘却)という課題を解決するための新しい枠組みであるTMSを提案した。 TMSは報酬モデルや検証器を必要とせず、学習過程の過去のチェックポイントから生成された多様な回答を混合して学習データとすることで、強化学習のような動的な学習効果を再現し、特定の回答への過度な集中(モード崩壊)を抑制する。 数学的な推論や指示に従うタスクを用いた検証の結果、TMSは従来のSFTよりも高い性能と既存能力の保持を両立し、強化学習に近い特性を示しながらも、計算コストや実装の複雑さを大幅に削減することに成功した。
なぜこの問題か
大規模言語モデル(LLM)の性能を向上させる手法として、教師あり微調整(SFT)と強化学習(RL)が主流となっている。SFTは実装が容易で安定しているが、学習が進むにつれてモデルが元々持っていた汎用的な能力を失う「破滅的忘却」や「能力の崩壊」という深刻な副作用に直面することが多い。この現象の主な原因は、モデルのポリシーが学習を通じて進化し続けるのに対し、与えられる教師ラベルが静的で変化しないという「教師の不一致(Supervision Mismatch)」にある。モデルが学習によって新しい表現を獲得しても、古い固定されたラベルに強制的に合わせようとする過程で、本来維持すべき汎用的な特徴が破壊されてしまうのである。 一方で、強化学習はモデルの現在の状態に合わせて学習ターゲットを動的に調整する「オンポリシー」の性質を持つため、汎用能力の保持には優れていることが知られている。しかし、強化学習を大規模に導入するには、報酬設計の複雑さ、学習の不安定さ、そして高い計算コストが大きな障壁となっている。特に、正解が一つではない複雑な推論タスクにおいて、適切な報酬モデルや検証器を用意することは容易ではない。…
核心:何を提案したのか
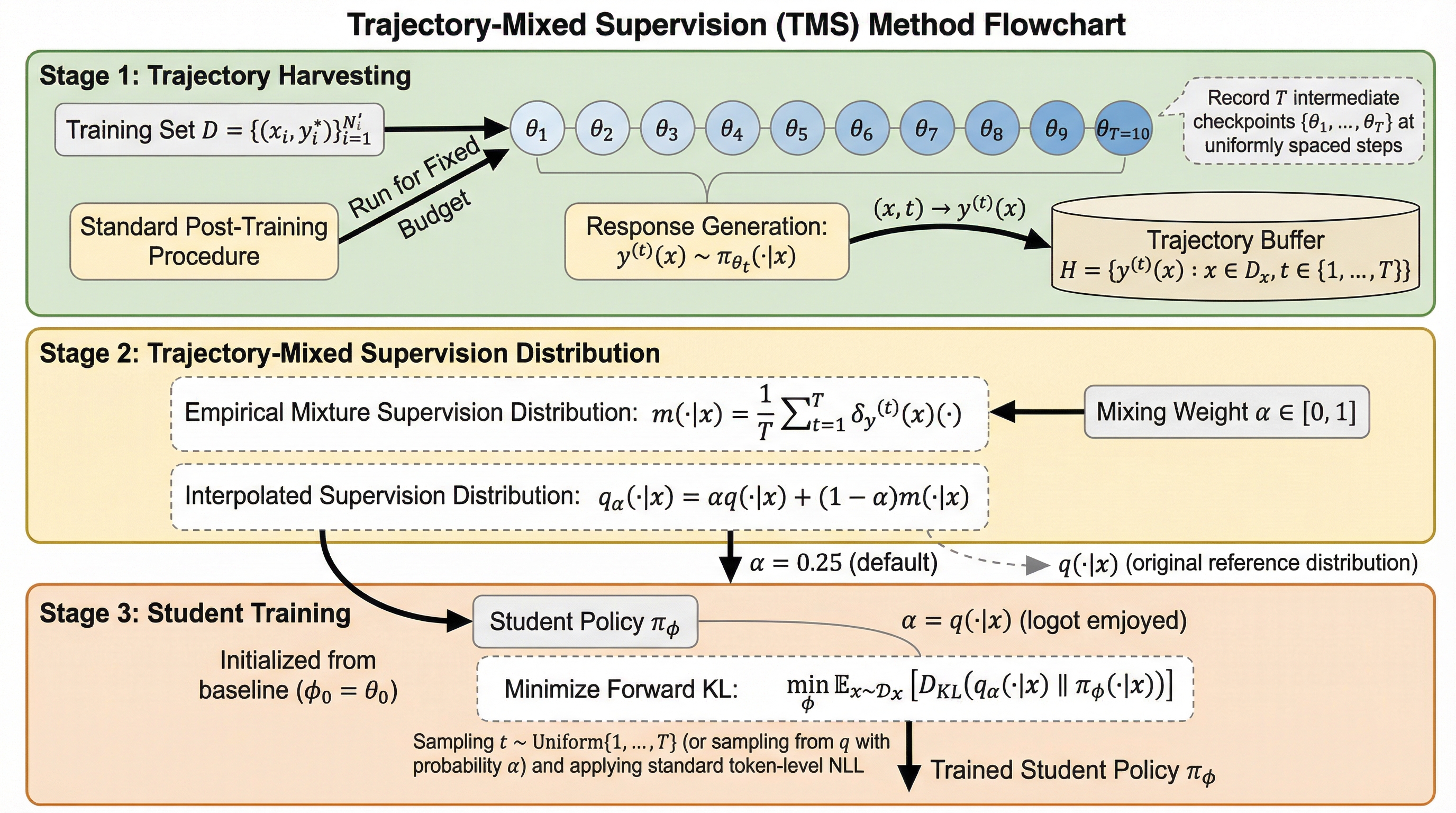
本研究では、報酬モデルや検証器を一切必要としない新しいポストトレーニングの枠組みである「軌跡混合教師あり学習(TMS: Trajectory-Mixed Supervision)」を提案した。TMSは、モデル自身の学習過程における過去のチェックポイントから得られる回答の軌跡(Trajectory)を利用して、動的なカリキュラムを構築する手法である。これにより、強化学習が持つ「オンポリシー」の利点を、SFTの枠組みの中で近似的に再現することが可能となった。TMSの核心は、単一の静的な正解ラベルに固執するのではなく、モデルが過去に生成した多様な妥当な回答を混合して学習に用いる点にある。 これにより、モデルの進化と教師データの乖離を最小限に抑え、特定の回答モードに確率が集中しすぎる「モード崩壊」を防ぐ。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related