RC-GRPO: 報酬条件付きグループ相対方策最適化によるマルチターン・ツール呼び出しエージェントの向上
マルチターンでのツール呼び出しにおいて、報酬の疎らさと探索コストの高さが課題であり、従来のGRPO手法ではグループ内の報酬に差異がない場合に学習が停滞する問題があったが、本研究では報酬条件付きの学習を導入することでこの課題を解決した。
TL;DR(結論)
マルチターンでのツール呼び出しにおいて、報酬の疎らさと探索コストの高さが課題であり、従来のGRPO手法ではグループ内の報酬に差異がない場合に学習が停滞する問題があったが、本研究では報酬条件付きの学習を導入することでこの課題を解決した。 提案手法のRC-GRPOは、まず報酬トークンを用いた条件付き学習(RCTP)を行い、強化学習時に異なる報酬条件をサンプリングすることで、グループ内の多様性を意図的に生み出し、学習信号を安定させることでモデルの性能を大幅に向上させることに成功した。 実験ではQwen-2.5-7Bを用いたモデルがBFCLv4ベンチマークで85.00%の精度を記録し、既存のSFT+GRPO手法を大幅に上回るだけでなく、主要な商用クローズドモデルであるOpus-4.5やGPT-5.2を超える性能をオープンモデルで実証した。
なぜこの問題か
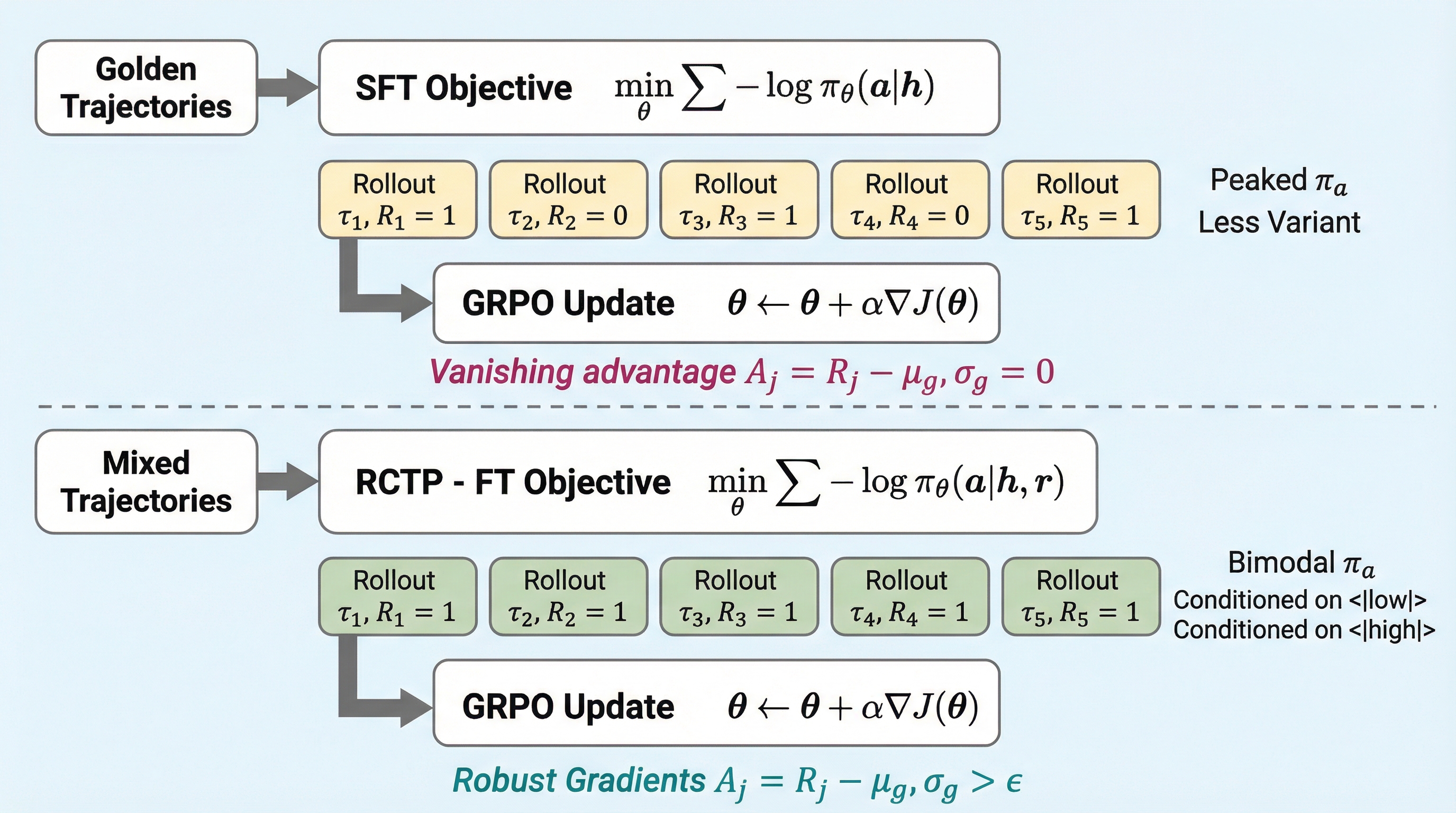
大規模言語モデル(LLM)によるマルチターン・ツール呼び出しは、複雑なタスクを解決するために自然言語による推論と外部API呼び出しを交互に行う必要がある。しかし、この設定では成功が軌道レベルの疎らな報酬でしか測定されないため、効率的な探索が非常に困難である。従来の強化学習手法であるGroup Relative Policy Optimization(GRPO)は、批判者(クリティック)モデルを必要としないためメモリ効率が良いが、その学習信号はグループ内の報酬の多様性に根本的に依存している。もしサンプリングされたグループ内の報酬がすべて同じ(すべて0またはすべて1)である場合、グループ内で正規化されたアドバンテージが消失し、方策の更新が行われなくなるという「勾配崩壊」の問題がある。 特に、高品質なデモンストレーションを用いた教師あり微調整(SFT)を事前に行う標準的なパイプラインでは、モデルの方策が特定の正解ルートに強く集中してしまう。これにより、ロールアウト時の多様性が減少し、GRPOにおけるグループ内の報酬分散が実質的にゼロになる「完璧のパラドックス」が生じる。…
核心:何を提案したのか
本研究では、グループ内の多様性をサンプリング時の温度設定に頼るのではなく、制御可能な変数として扱う「RC-GRPO(Reward-Conditioned Group Relative Policy Optimization)」を提案した。この手法は、リターン条件付き学習の考え方に着想を得ており、探索を「制御可能なステアリング問題」として再定義している。具体的には、離散的な報酬トークン( や など)をプロンプトに注入することで、モデルが要求に応じて異なる品質の軌道を生成できるように学習させる。これにより、モデルは単に正解を模倣するだけでなく、報酬条件に応じて意図的に異なる振る舞いを選択する能力を獲得する。 RC-GRPOのプロセスは大きく2つのステージに分かれている。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related