AERO:内生的二重ループフィードバックによる自律的進化的推論最適化
AEROは、外部の専門家データや検証器に一切依存せず、単一の大規模言語モデル(LLM)が「自己発問」「自己回答」「自己批判」という3つの役割を内生的に担うことで、自律的に推論能力を向上させる未学習の進化フレームワークである。
TL;DR(結論)
AEROは、外部の専門家データや検証器に一切依存せず、単一の大規模言語モデル(LLM)が「自己発問」「自己回答」「自己批判」という3つの役割を内生的に担うことで、自律的に推論能力を向上させる未学習の進化フレームワークである。 心理学の「発達の最近接領域(ZPD)」理論に基づき、エントロピーを用いてモデルにとって適切な難易度の課題を特定するとともに、反事実的な仮定を用いた独立修正(ICC)によって、外部ラベルなしで論理的妥当性を高精度に検証する仕組みを導入している。 Qwen3モデルを用いた評価では平均約5%の性能向上を達成し、段階的トレーニング戦略によって各役割の成長速度を同期させることで、自己進化プロセスにおける学習の停滞や崩壊を防ぎながら、数学や物理などの高度なドメインで継続的な成長を実現した。
なぜこの問題か
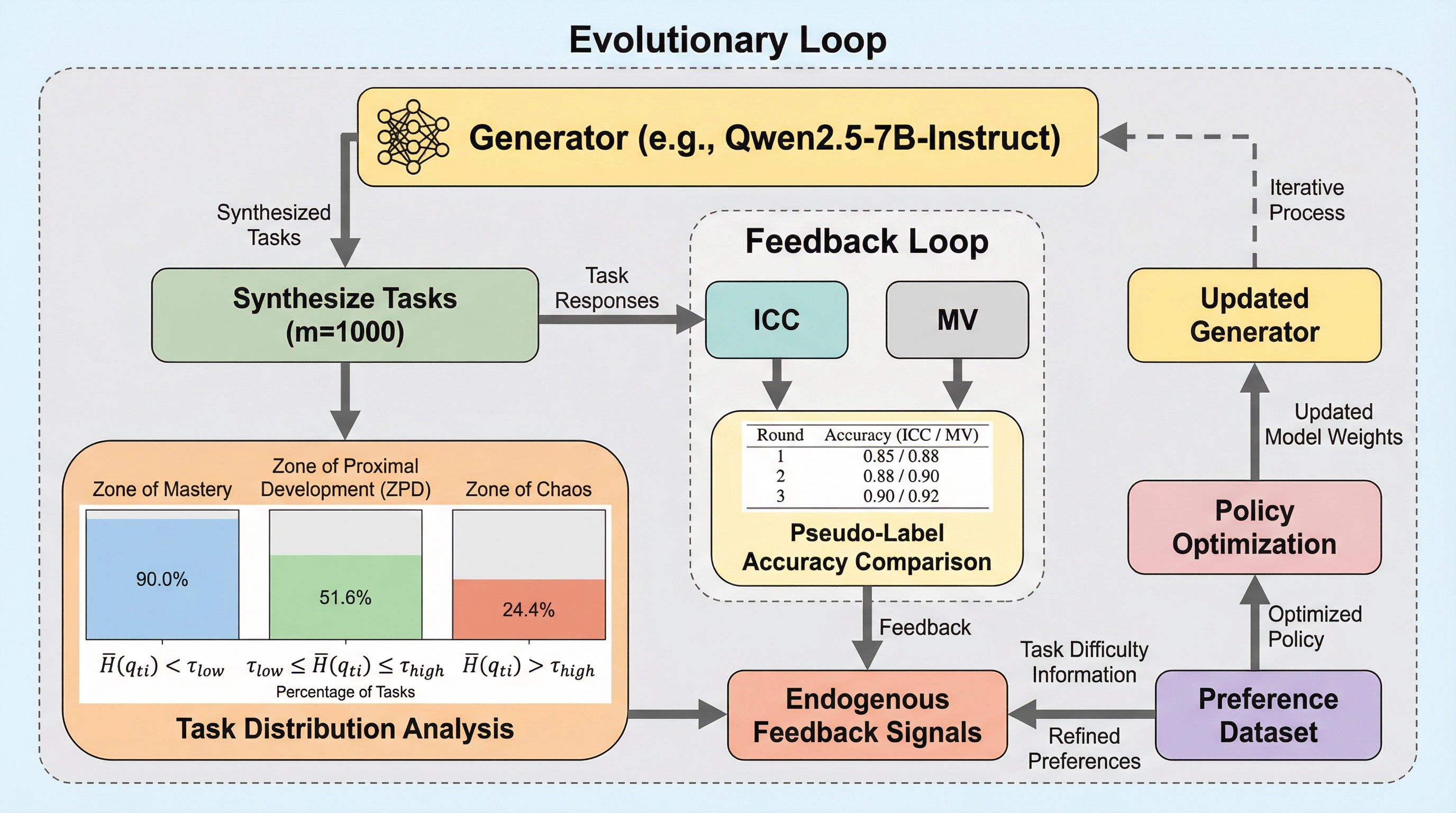
大規模言語モデル(LLM)は複雑な推論において高い能力を示しているが、そのさらなる成長は、人間が作成した高品質なデータや、数学エンジン、コードコンパイラといった外部の検証器への依存という大きな壁に突き当たっている。このような外部リソースへの依存は、モデルの能力を既存の人間知識の範囲内に閉じ込めてしまい、人間がまだ到達していない未知の推論パターンを発見する機会を奪っている。この制約を打破するために、モデルが自ら生成したデータから学習する「自己進化」の枠組みが注目されているが、既存の手法には二つの致命的な欠陥がある。 第一に、タスクの難易度を適切に制御する仕組みが欠けている点である。モデルが生成する課題が簡単すぎれば新しい知識は得られず、逆に難解すぎればモデルは理解できず学習が成立しない。この「解決可能なギャップ」を正確に捉える戦略がないため、学習効率が著しく低下し、モデルが成長の停滞に陥りやすい。 第二に、外部検証器の代わりに多数決や確信度といった内部指標を用いる手法は、モデルが誤った先入観を持っている場合に、その間違いを正解として強化してしまう「集団的幻覚」のリスクを孕んでいる。…
核心:何を提案したのか
本論文では、単一のLLMの中に「自己発問(ジェネレーター)」「自己回答(ソルバー)」「自己批判(リファイナー)」という三つの機能を統合し、それらを二重ループシステムとして構造化した「自律的進化推論最適化(AERO)」を提案している。AEROは、外部の正解ラベルや検証器を必要としない完全な未学習フレームワークであり、モデルが自らの内生的なフィードバックのみを通じて推論能力を進化させることを目的としている。 この提案の大きな特徴は、心理学における「発達の最近接領域(ZPD)」理論をAIの学習に応用したことである。エントロピーを用いてモデルの推論の不確実性を測定し、現在の能力で「解けるか解けないかの境界」にある課題を特定することで、最も学習効果の高い領域に集中して自己進化を促す。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related