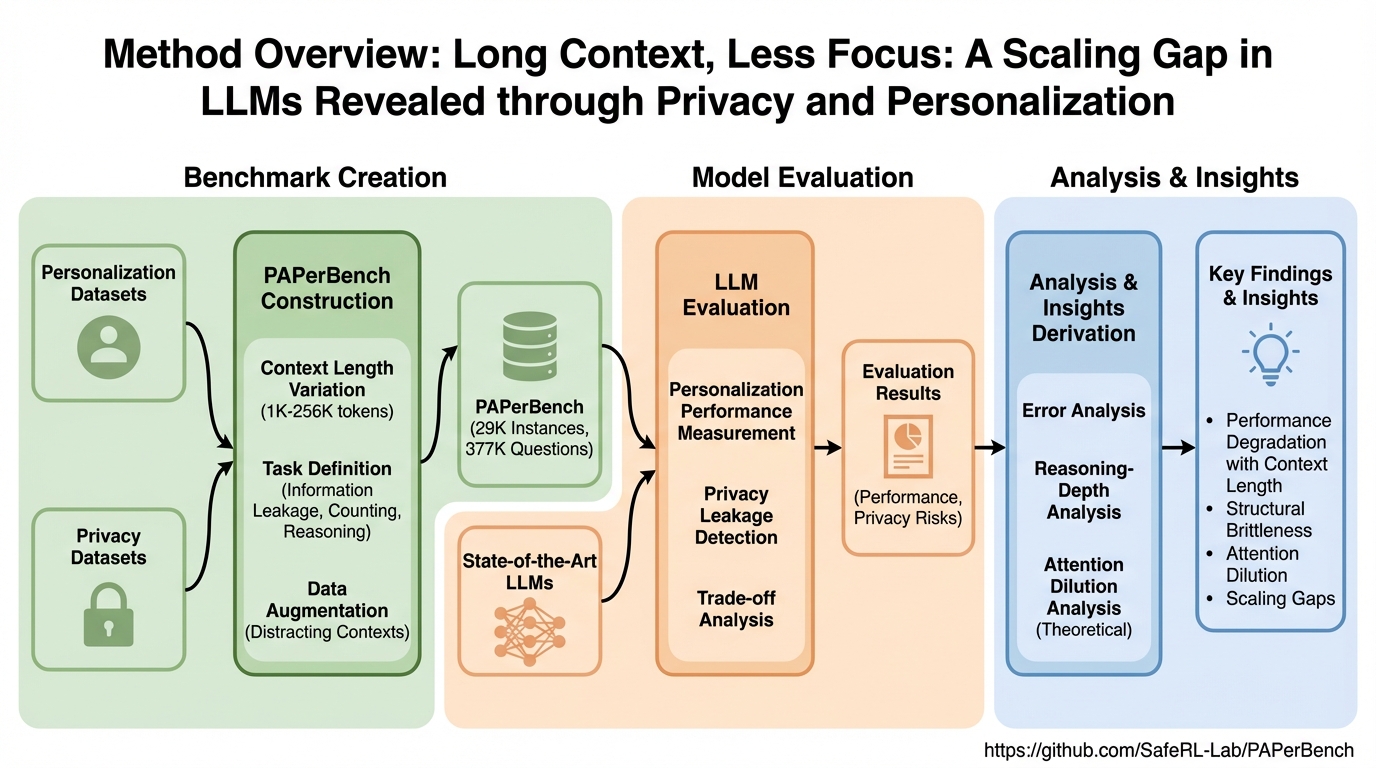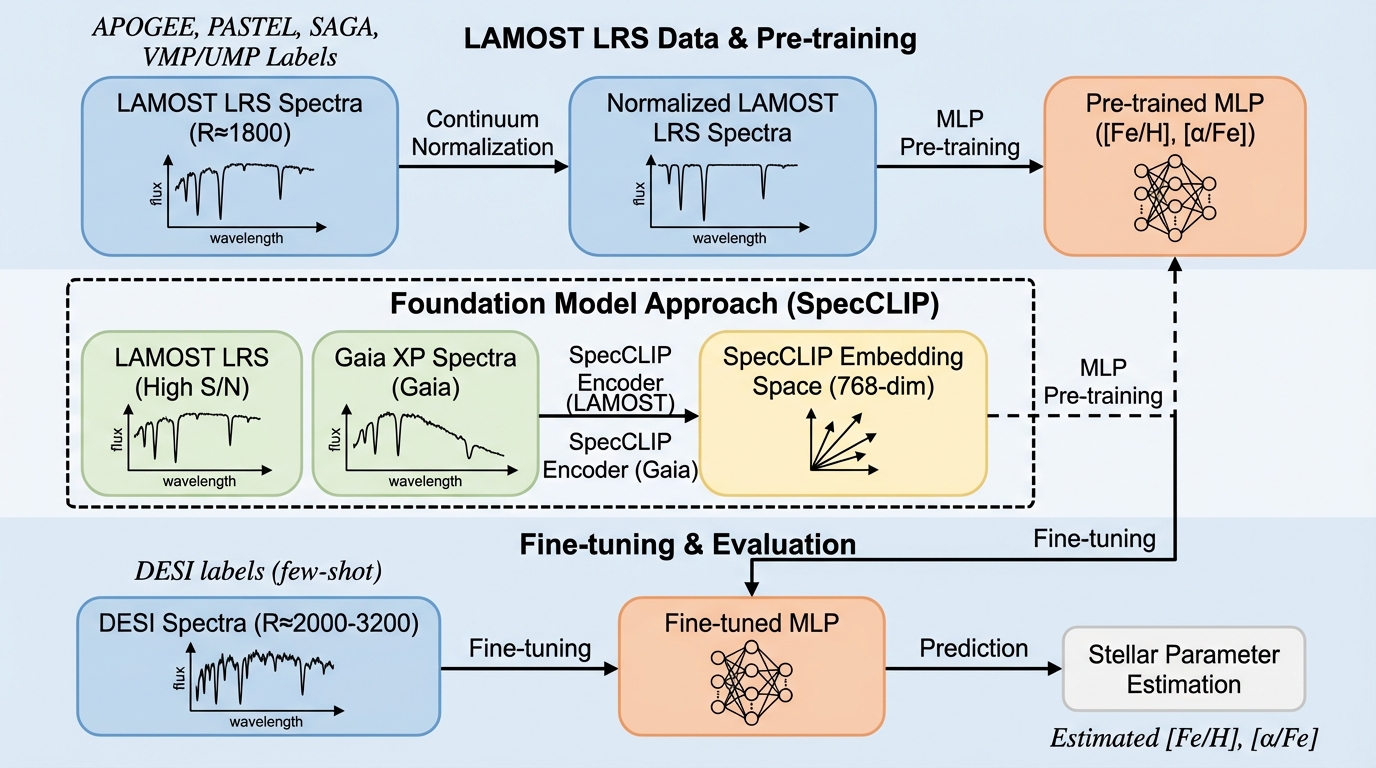
低分解能から中分解能スペクトルへ:単純なニューラルネットによる恒星パラメータ推定のクロスサーベイ汎化(DESI事例)。
低分解能サーベイで学習した単純な多層パーセプトロン(MLP)でも、別サーベイの中分解能スペクトルへそのまま適用しても良好に推定でき、少量データでの追加学習でさらに整えられることを示しました。 / LAMOSTの低分解能スペクトルそのもの、またはトランスフォーマー系の自己教師ありモデルが作る埋め込みを入力としてMLPを事前学習し、DESIスペクトルに対してゼロショット適用と少数ショットの微調整を行い、残差ヘッド、LoRA、全層微調整を比較しました。 / 鉄の存在度では金属量が高い領域([Fe/H] > −1.0)で埋め込みが有利になり得る一方、金属量が低い領域ではスペクトル直接入力のMLPが相対的に優位になり、最適な微調整法は推定したい恒星パラメータによって変わることが分かりました。