低分解能から中分解能スペクトルへ:単純なニューラルネットによる恒星パラメータ推定のクロスサーベイ汎化(DESI事例)。
低分解能サーベイで学習した単純な多層パーセプトロン(MLP)でも、別サーベイの中分解能スペクトルへそのまま適用しても良好に推定でき、少量データでの追加学習でさらに整えられることを示しました。 / LAMOSTの低分解能スペクトルそのもの、またはトランスフォーマー系の自己教師ありモデルが作る埋め込みを入力としてMLPを事前学習し、DESIスペクトルに対してゼロショット適用と少数ショットの微調整を行い、残差ヘッド、LoRA、全層微調整を比較しました。 / 鉄の存在度では金属量が高い領域([Fe/H] > −1.0)で埋め込みが有利になり得る一方、金属量が低い領域ではスペクトル直接入力のMLPが相対的に優位になり、最適な微調整法は推定したい恒星パラメータによって変わることが分かりました。
TL;DR(結論)
- 低分解能サーベイで学習した単純な多層パーセプトロン(MLP)でも、別サーベイの中分解能スペクトルへそのまま適用しても良好に推定でき、少量データでの追加学習でさらに整えられることを示しました。
- LAMOSTの低分解能スペクトルそのもの、またはトランスフォーマー系の自己教師ありモデルが作る埋め込みを入力としてMLPを事前学習し、DESIスペクトルに対してゼロショット適用と少数ショットの微調整を行い、残差ヘッド、LoRA、全層微調整を比較しました。
- 鉄の存在度では金属量が高い領域([Fe/H] > −1.0)で埋め込みが有利になり得る一方、金属量が低い領域ではスペクトル直接入力のMLPが相対的に優位になり、最適な微調整法は推定したい恒星パラメータによって変わることが分かりました。
なぜこの問題か
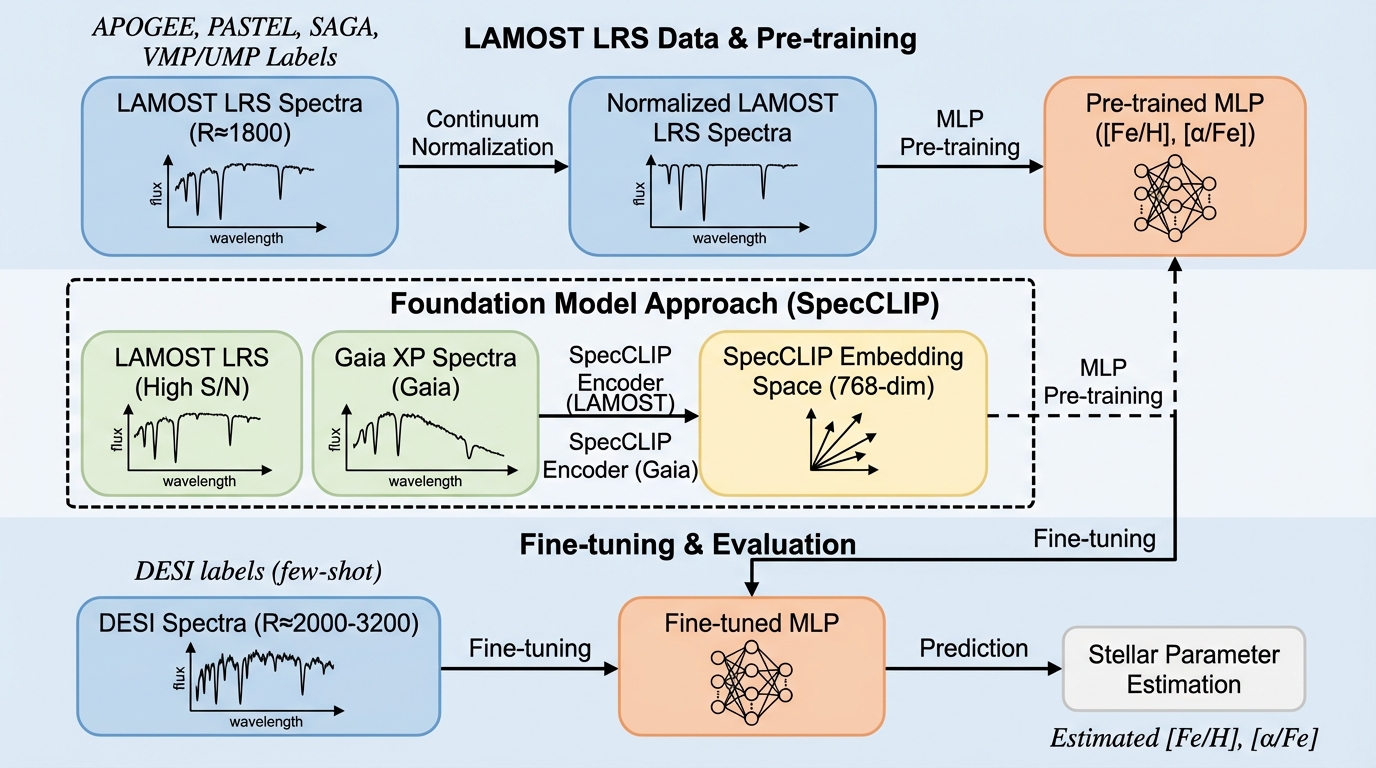
大規模分光サーベイは、非常に多くの恒星スペクトルを提供し、銀河系の恒星集団の理解を進めてきました。ところが、サーベイが変わると波長範囲、分解能、信号雑音比、さらには主に観測される恒星集団の性質が異なり、同じ推定器をそのまま持ち込むと推定の一貫性が崩れやすくなります。この「クロスサーベイ汎化」は、恒星スペクトル解析における中心課題として位置づけられています。機械学習モデルは柔軟で、サーベイ固有の系統差やノイズにも適応しやすい一方で、訓練時と異なるサーベイへ直接適用すると、分布のずれによって性能が落ちやすい点が問題になります。加えて、移植先サーベイでは高品質ラベルが十分に揃わず、移植先だけでゼロから学習し直すことが難しい状況も生じます。 本研究は、低分解能から中分解能への移植という具体的な設定に焦点を当て、LAMOSTの低分解能スペクトル(LRS、分解能はおよそ1800)からDESIの中分解能スペクトル(MRS、分解能はおよそ2000〜3200、波長は360〜555 nm)への転移を事例として扱います。…
核心:何を提案したのか
提案の核は、LAMOST LRSで事前学習した単純なMLPを、DESIの恒星スペクトルへ移植して恒星パラメータ推定を行い、どの事前学習表現と微調整戦略がクロスサーベイ汎化に効くのかを系統的に比較することです。具体的には、入力表現として二つの流れを並行して扱います。一つは、連続光で正規化したLAMOST LRSのスペクトルをそのままMLPへ入力して学習する方法で、モデルはスペクトルの形状や吸収線情報を直接的に利用します。もう一つは、トランスフォーマー系の自己教師ありモデルが生成するスペクトル埋め込み(固定長ベクトル)を入力としてMLPを学習する方法で、事前学習により獲得された汎用表現が下流の回帰に役立つかを検証します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related