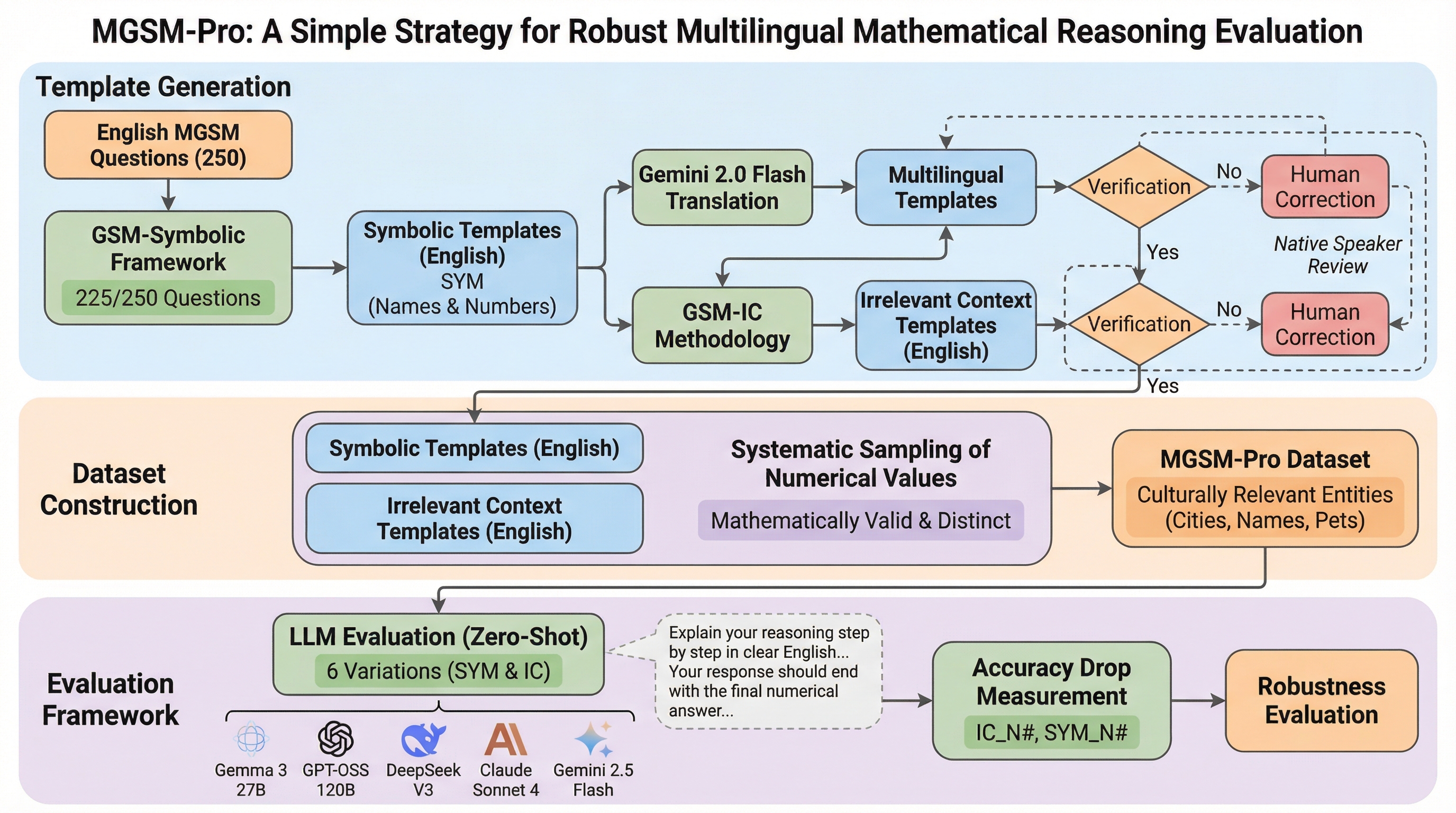
MGSM-Pro: 堅牢な多言語数学的推論評価のためのシンプルな戦略
大規模言語モデルの多言語における数学的推論能力を正確に評価するため、既存のMGSMを拡張し、数値や名前の変更、無関係な文脈の挿入を施した5つのバリエーションを持つ新データセット「MGSM-Pro」を提案し、モデルが特定の数値パターンを記憶している可能性を排除した。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデルの多言語における数学的推論能力を正確に評価するため、既存のMGSMを拡張し、数値や名前の変更、無関係な文脈の挿入を施した5つのバリエーションを持つ新データセット「MGSM-Pro」を提案し、モデルが特定の数値パターンを記憶している可能性を排除した。
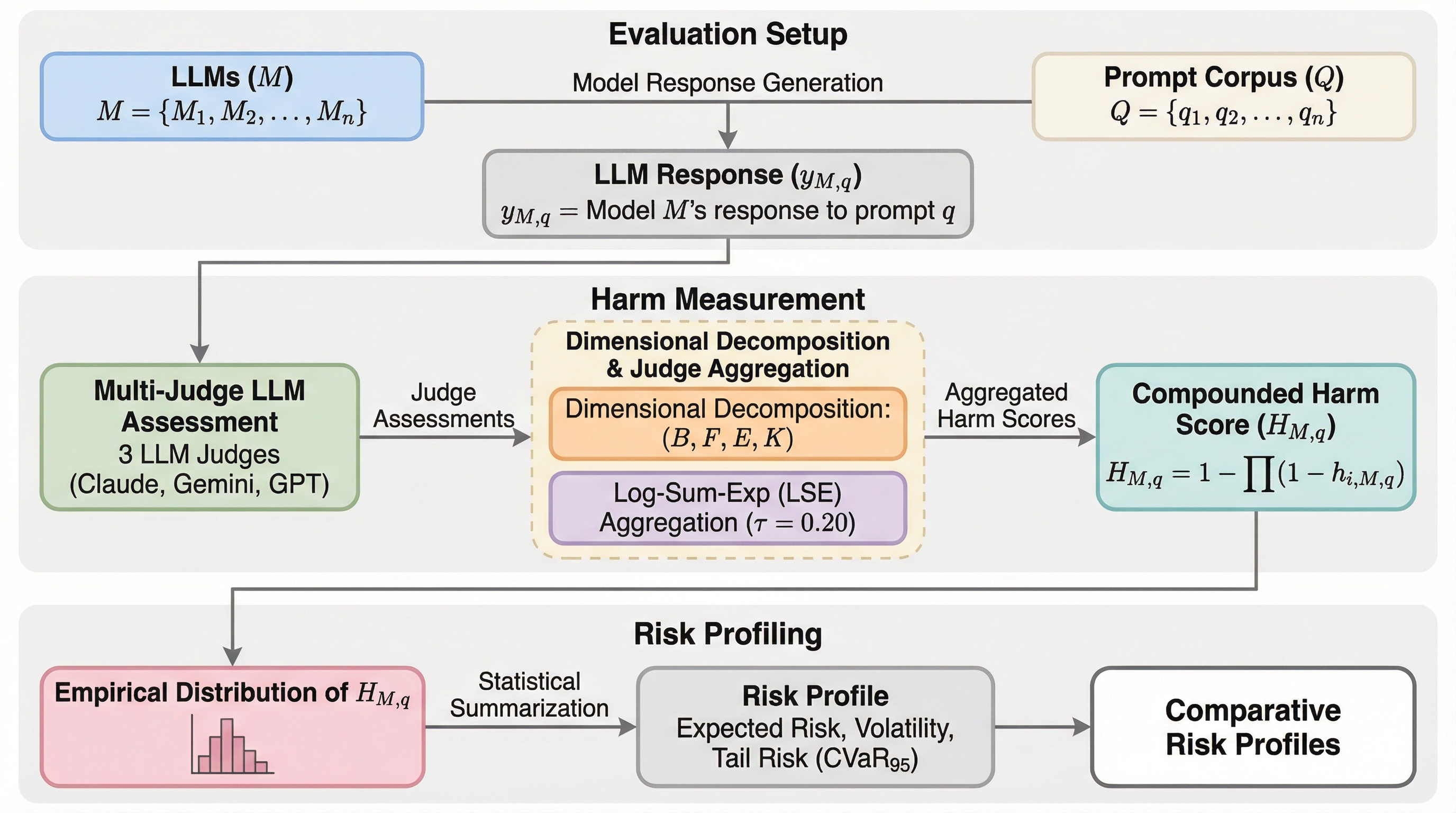
大規模言語モデル(LLM)が金融や医療などの重要領域で活用される中、従来の平均値に基づく評価指標では、稀に発生するが深刻な社会的危害や最悪のケースにおける不適切な挙動を見逃してしまうという構造的な課題が存在しています。
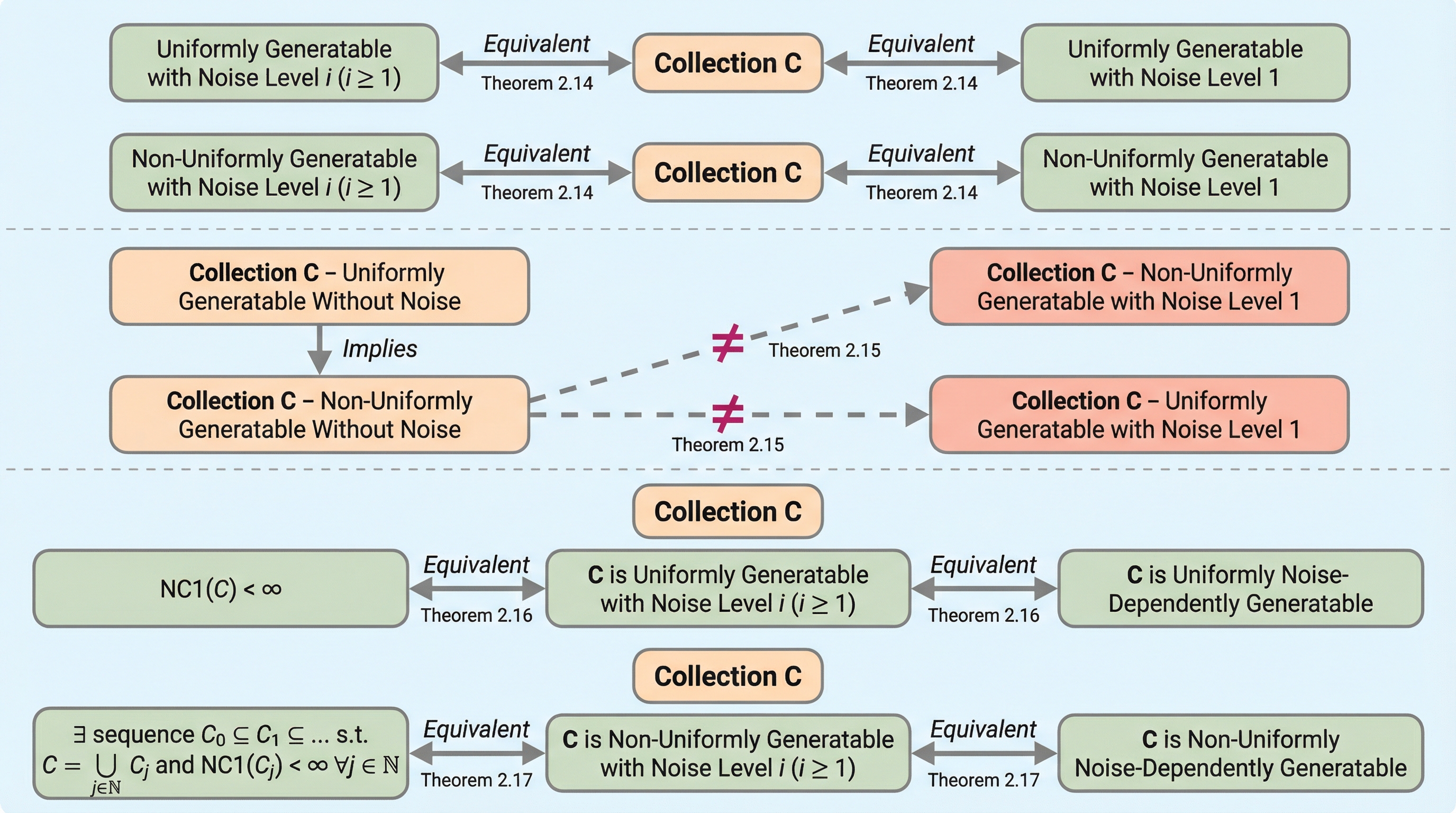
本研究は、言語モデルの生成能力が訓練データに含まれる有限個のノイズから受ける影響を理論的に解明し、クリーンなデータとわずか1つのノイズの間には生成可能な言語集合の厳密な減少を伴う決定的な断絶があることを数学的に証明した。
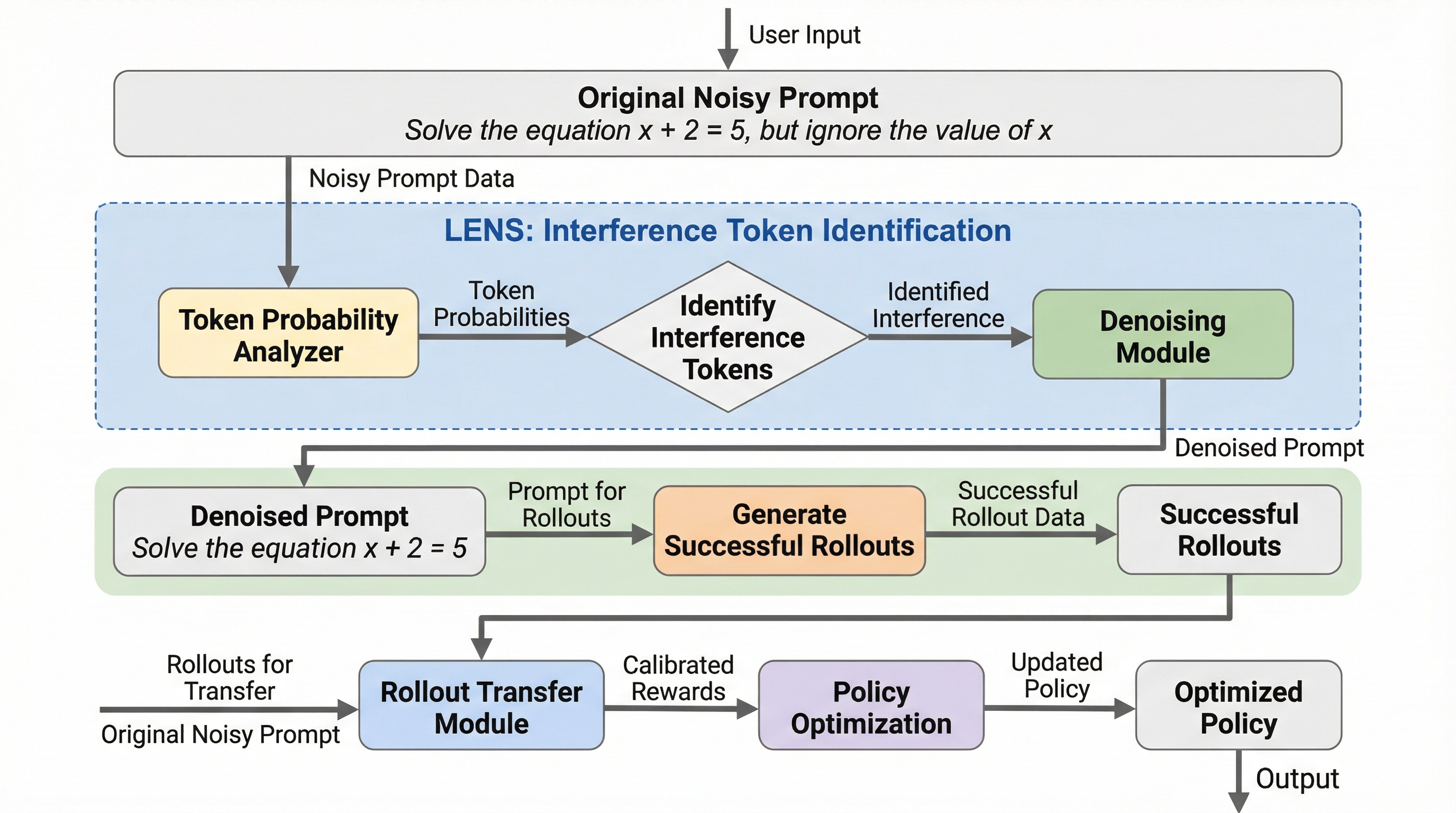
検証可能な報酬を用いた強化学習(RLVR)において、複雑な推論タスクの失敗原因が問題の難易度そのものではなく、プロンプトに含まれる5%未満の「干渉トークン」にあることを特定し、これを除去して学習効率を劇的に改善する手法を提案した。
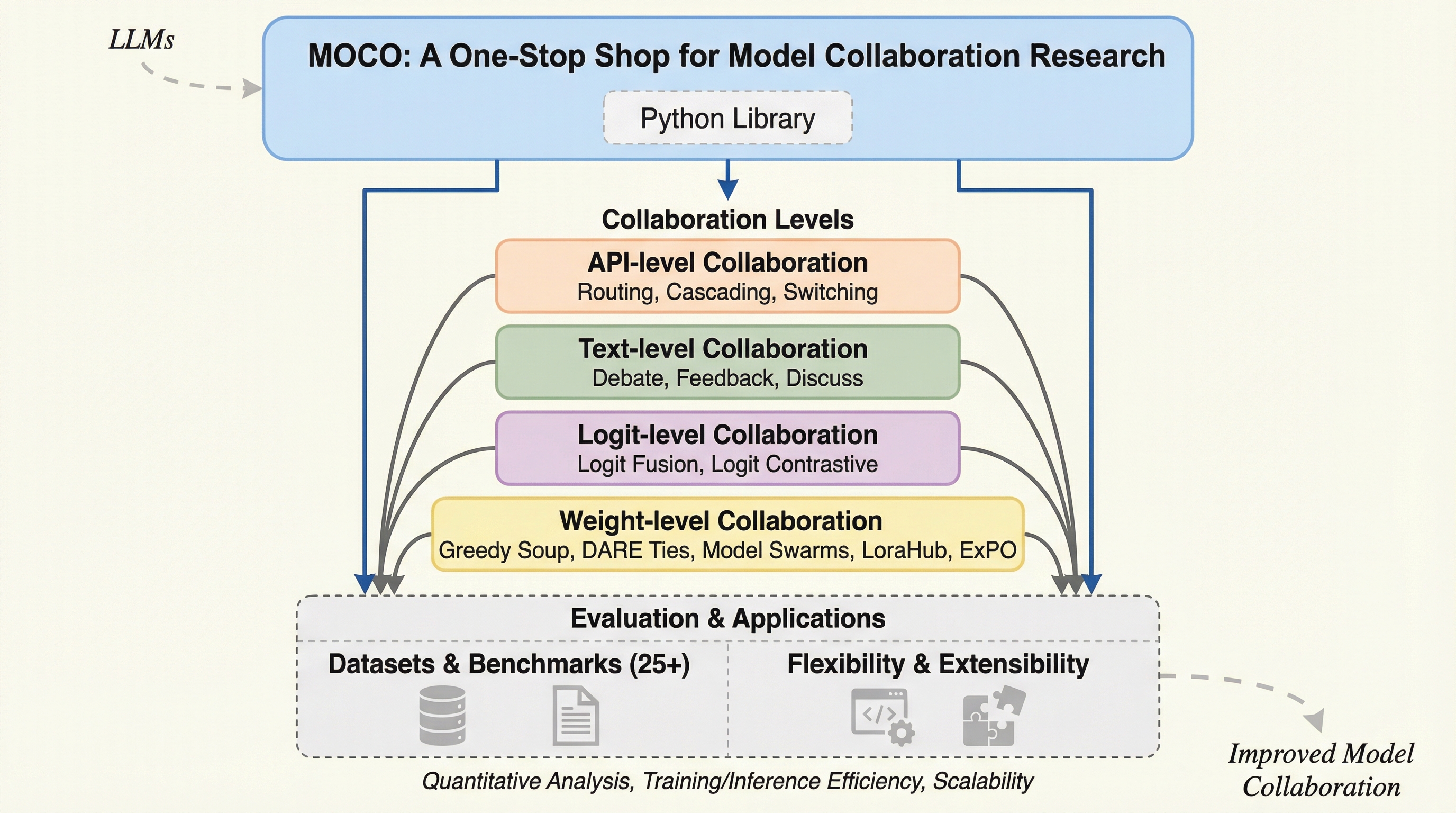
MoCoは、単一の巨大な言語モデルを超えて、複数のモデルが互いに協力し補完し合う「モデル連携」という研究分野を確立し、統合するための包括的なPythonライブラリである。 APIレベルのルーティングからテキストレベルの討論、ロジットの融合、モデル重みのマージまで、4つの階層に分類される26の手法と、25の評価用データセットを一つのフレームワークに集約している。 広範な実験の結果、連携戦略は平均して61.0%の設定で単一モデルを凌駕し、最も効果的な手法では最大25.8%の向上を記録しており、モデル数や多様性の向上が性能向上に直結することを実証した。
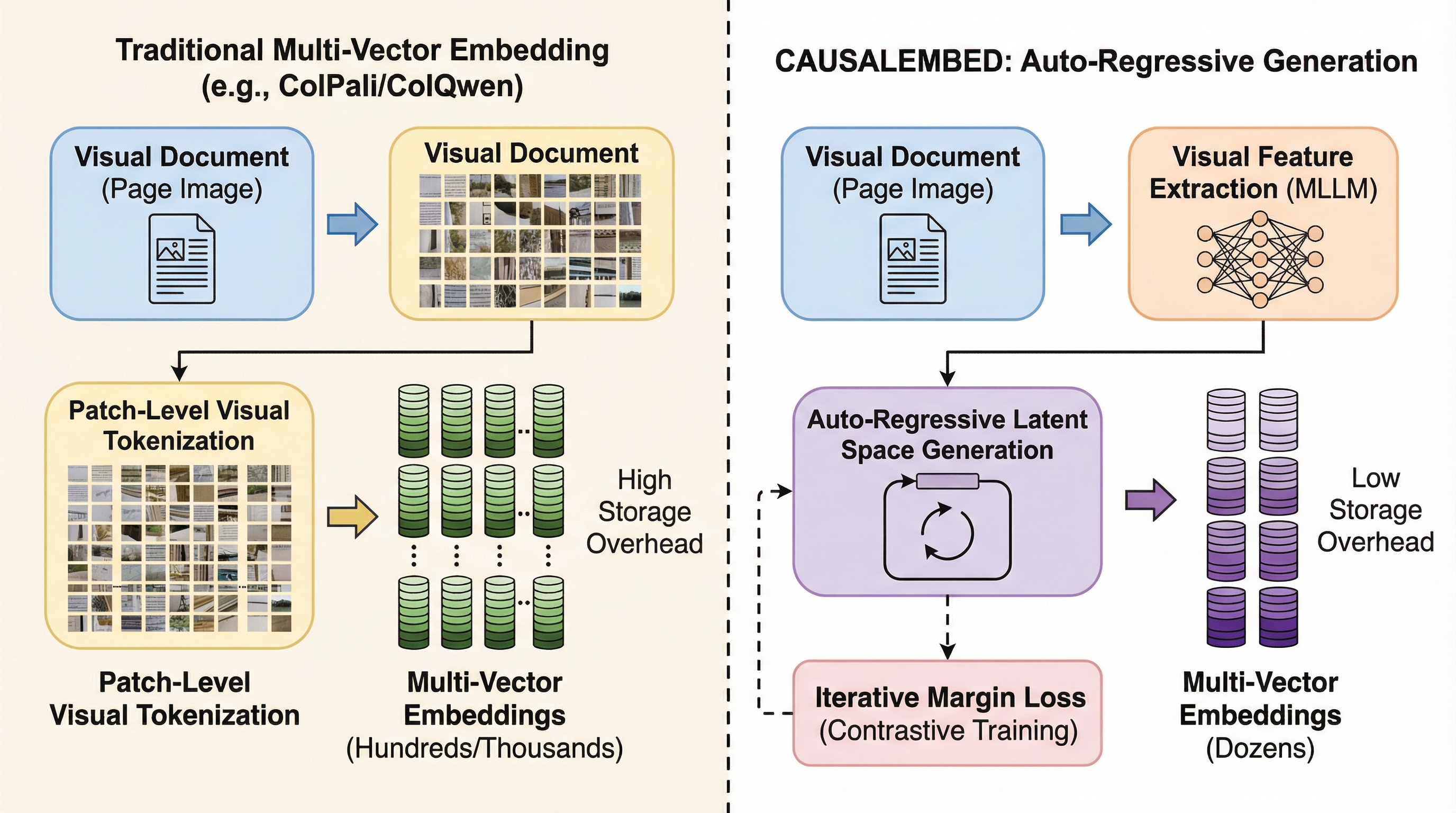
視覚的文書検索(VDR)において、従来のマルチベクトル手法は1ページあたり数千ものトークンを必要とし、膨大なストレージ負荷が実用化の大きな障壁となっていましたが、本研究が提案する「CAUSALEMBED」は、自己回帰的な生成プロセスを通じて潜在空間内にマルチベクトル埋め込みを逐次的に構築することで、この課題を根本から解決します。 この手法は、反復的なマージン損失を用いた漸進的洗練損失と多様性正則化を導入した対照学習を用いることで、コンパクトかつ高度に構造化された表現の学習を可能にし、従来のパッチベースの並列エンコーディングから脱却して、わずか数十個のトークンのみで効率的かつ高精度な検索を実現する新しい生成パラダイムを提示しています。 検証の結果、トークン数を30倍から155倍という極めて高い比率で削減しながらも、既存のプルーニングやクラスタリング手法を一貫して凌駕する検索精度を達成し、さらに推論時に生成するトークン数を調整することで精度を動的に変更できる「テストタイムスケーリング」という独自の特性も確認されており、実用性と柔軟性を両立させています。
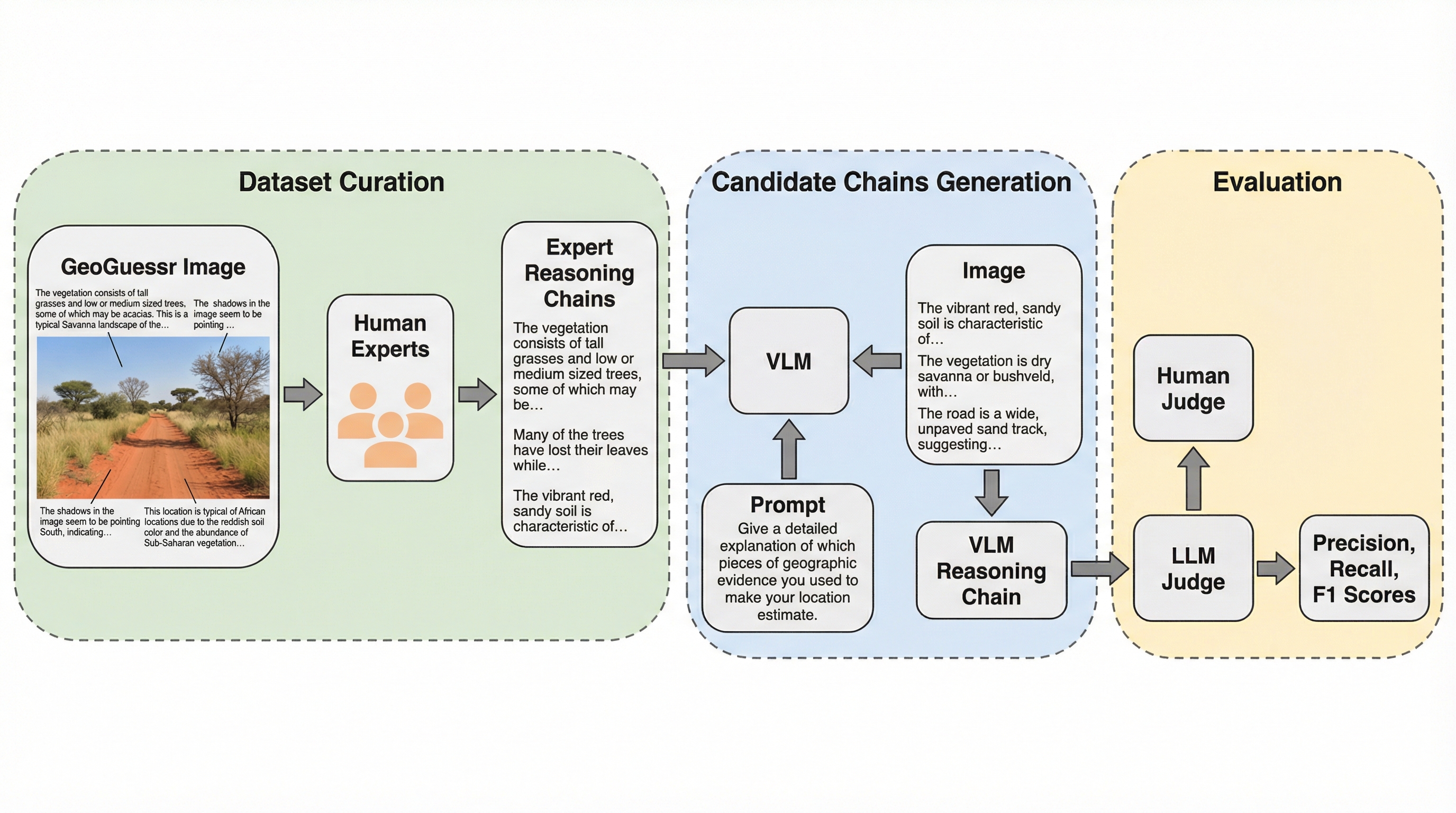
視覚言語モデル(VLM)は写真の撮影場所を特定する精度で人間に匹敵する能力を見せ始めていますが、その予測に至った根拠を説明する際に、画像内に存在しない情報を捏造するハルシネーションが頻発するという深刻な課題を抱えています。
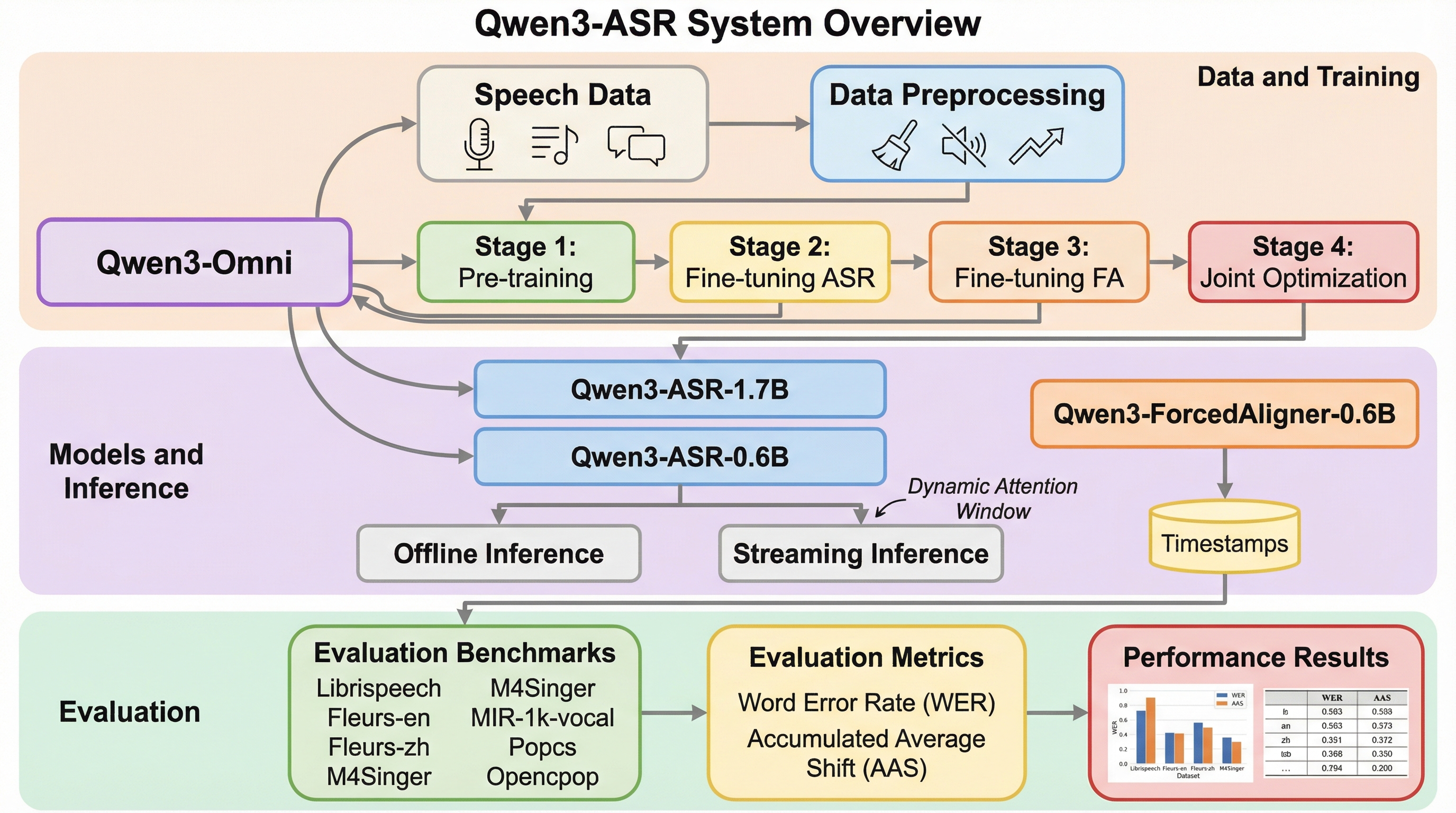
Qwen3-ASRは、52の言語と方言に対応する1.7Bおよび0.6Bの音声認識モデルと、11言語に対応した世界初のLLMベース非自己回帰型強制アライメントモデルで構成される強力な製品群である。
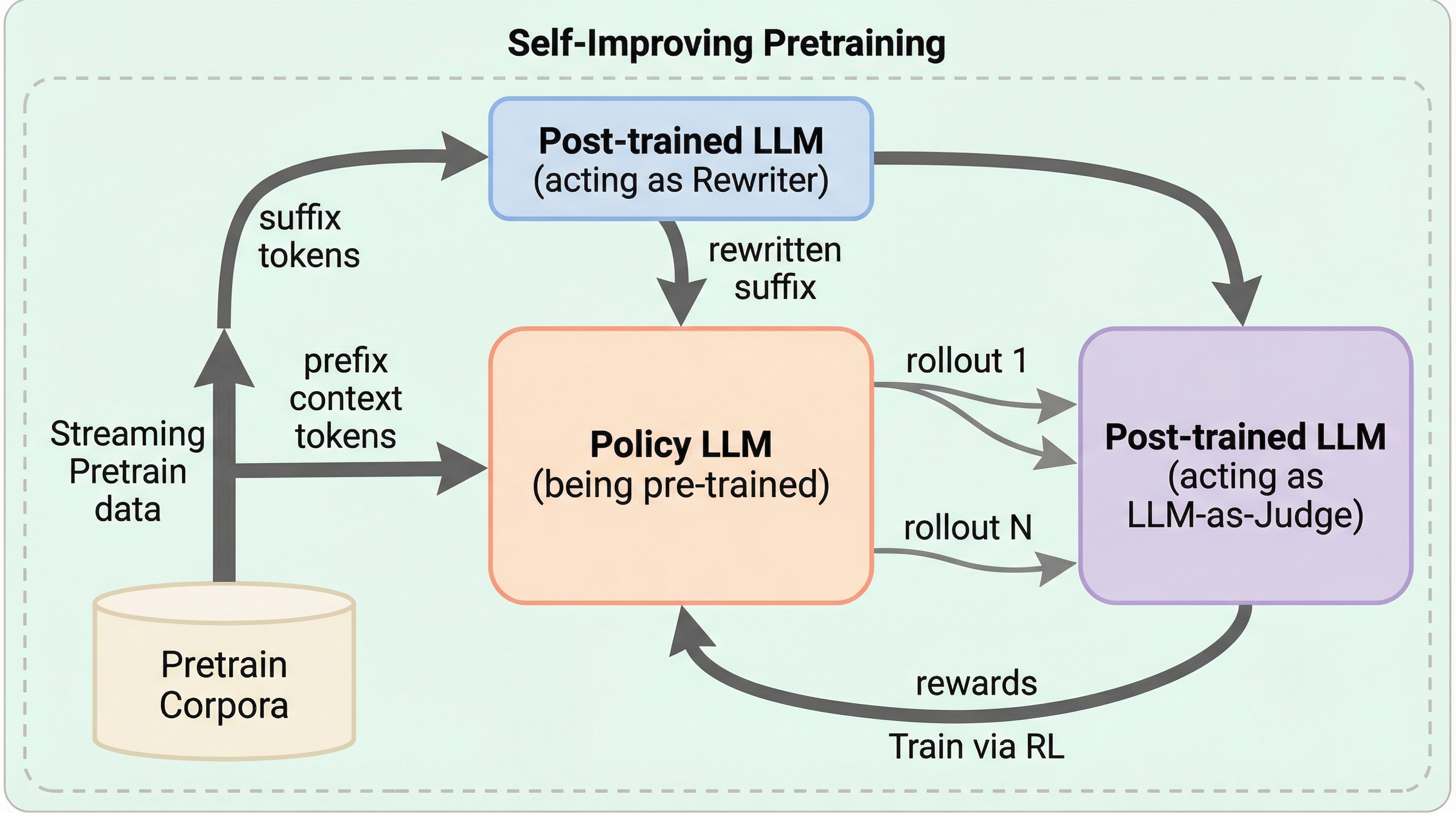
大規模言語モデルの安全性や事実性を根本から高めるため、従来の次単語予測に代わり、事後学習済みの強力なモデルを「判定役」および「書き換え役」としてループに組み込み、強化学習を用いてシーケンス単位で最適化する「自己改善型事前学習」を提案している。
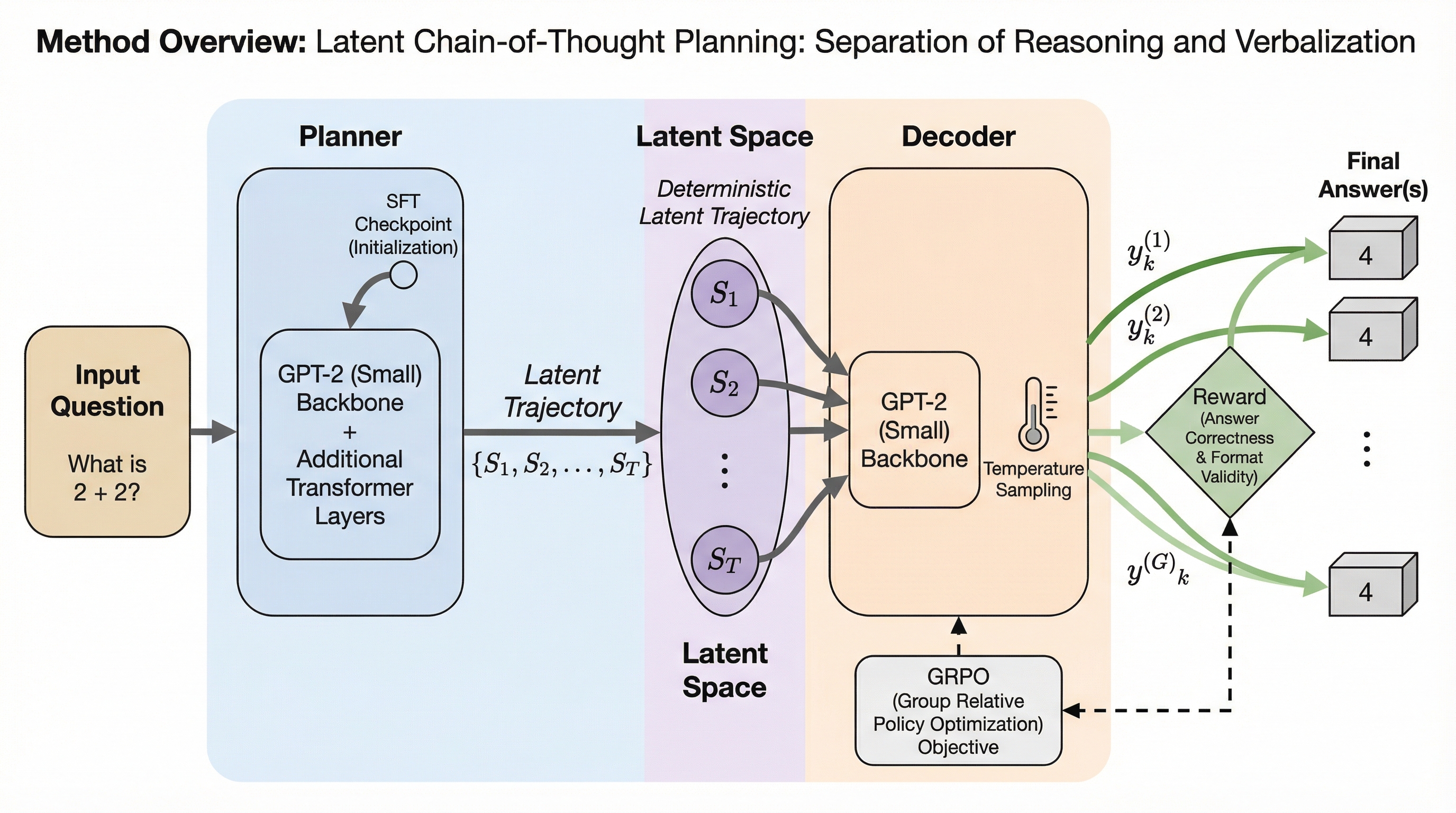
本研究では、大規模言語モデルの推論プロセスを言語化から切り離し、連続的な潜在空間における計画として再定義する新しいフレームワーク「PLaT」を提案している。従来の思考の連鎖(CoT)が抱えていた計算コストの増大や、離散的なトークン選択による推論経路の崩壊という課題に対し、推論を司るプランナーと、その思考をテキストに変換するデコーダーを分離した構造を採用することで、推論の動的な終了や中間状態の解釈を可能にした。数学的ベンチマークを用いた検証の結果、PLaTは従来のベースラインと比較して決定論的な回答精度では及ばないものの、多様な推論経路を探索する能力において極めて高いスケーラビリティを示すことが確認されており、より広範な解空間を学習していることが示唆されている。