ノイズを減らし、声を強める:指示の浄化による推論のための強化学習
検証可能な報酬を用いた強化学習(RLVR)において、複雑な推論タスクの失敗原因が問題の難易度そのものではなく、プロンプトに含まれる5%未満の「干渉トークン」にあることを特定し、これを除去して学習効率を劇的に改善する手法を提案した。
TL;DR(結論)
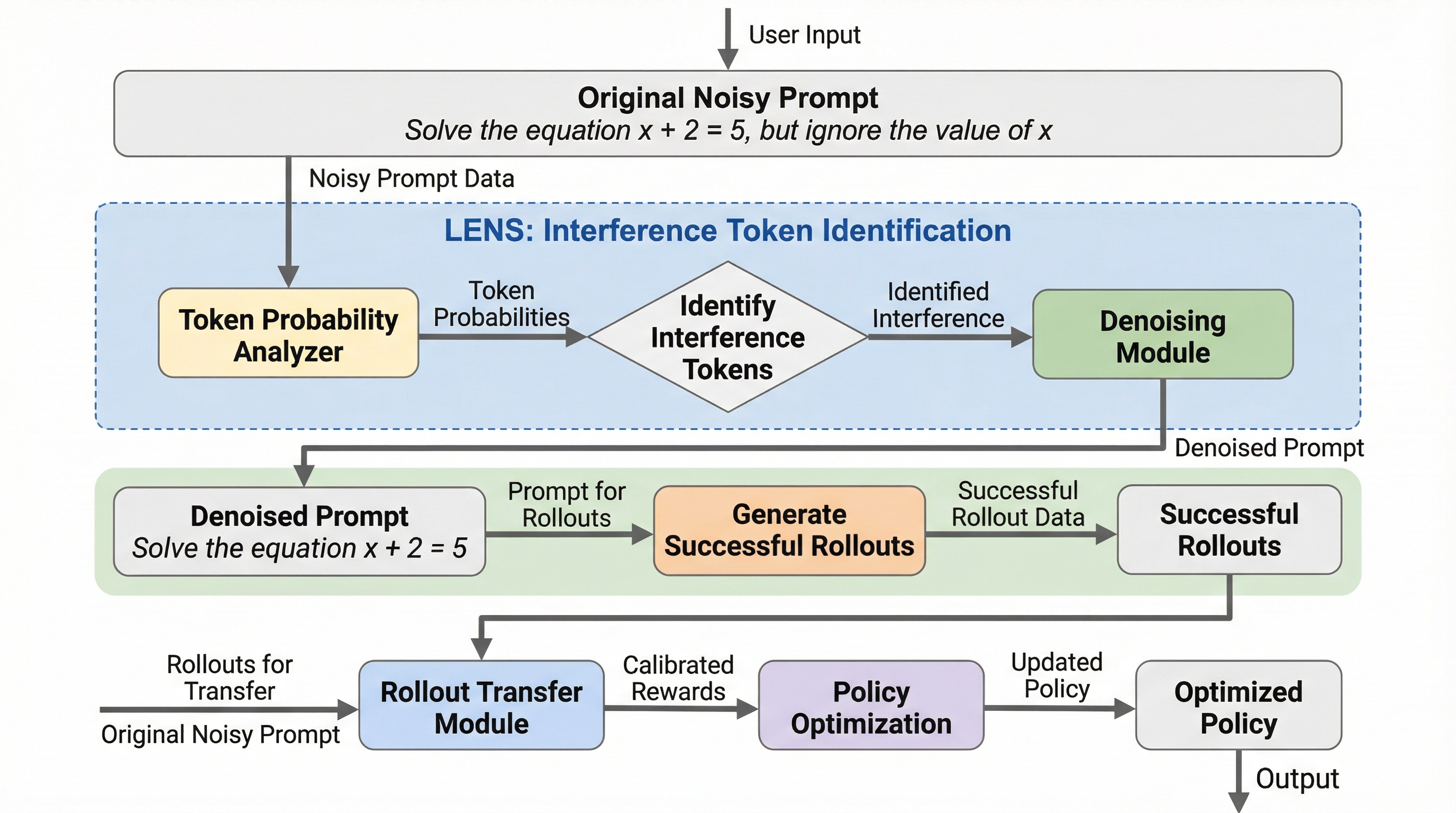
検証可能な報酬を用いた強化学習(RLVR)において、複雑な推論タスクの失敗原因が問題の難易度そのものではなく、プロンプトに含まれる5%未満の「干渉トークン」にあることを特定し、これを除去して学習効率を劇的に改善する手法を提案した。 提案フレームワーク「LENS」は、干渉スコアを用いてノイズとなるトークンを特定・浄化して成功サンプルを生成し、その信号を元のノイズを含むプロンプトの学習に転移させることで、モデルが現実世界の不完全な入力に対しても頑健に推論できる能力を養う。 数学推論ベンチマークを用いた実験では、従来手法のGRPOと比較して平均3.88%の精度向上と1.6倍以上の収束加速を達成しており、計算資源を増やすことなく探索効率を改善し、報酬の稀薄化問題を解決する新しい視点を提供している。
なぜこの問題か
大規模言語モデル(LLM)の推論能力を向上させる手法として、GRPOに代表される「検証可能な報酬を用いた強化学習(RLVR)」が注目を集めている。しかし、RLVRは学習信号を生成するために正しい実行結果(ロールアウト)をサンプリングすることに依存しており、複雑な推論タスクにおいては大きな課題に直面している。特に、意思決定のプロセスが長く、フィードバックが遅延的かつバイナリ(正解か不正解か)である場合、報酬の稀薄化が発生する。高次元のアクション空間において正しいロールアウトを得ることは極めて困難であり、ポジティブなサンプルが不足することで、学習が崩壊したり、極めて非効率になったりする問題がある。 これまでの研究では、この問題に対して主に2つのアプローチが取られてきた。1つは、ロールアウトの回数を増やして探索の規模を拡大する方法であるが、これは計算コストを大幅に増大させる一方で、探索自体の効率を根本的に改善するものではない。もう1つは、報酬の分散がゼロ(すべて不正解など)のプロンプトをフィルタリングして除外する方法であるが、これは困難なサンプルに対する探索を放棄することになり、モデルが複雑な問題を解決する能力を制限してしまう。…
核心:何を提案したのか
本論文では、効果的な方策探索を促進するためのプラグアンドプレイなロールアウトフレームワークとして「LENS(Less Noise Sampling Framework)」を提案している。LENSの核心は、低成功率のプロンプトに含まれる干渉トークンを特定して浄化し、そこから得られた高品質な学習信号を元のノイズの多い設定での学習に活用するという点にある。 LENSは大きく分けて2つのコンポーネントで構成されている。第一のコンポーネントは「干渉トークンの特定と浄化」である。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related