CausalEmbed: 潜在空間における自己回帰型マルチベクトル生成による視覚文書埋め込み
視覚的文書検索(VDR)において、従来のマルチベクトル手法は1ページあたり数千ものトークンを必要とし、膨大なストレージ負荷が実用化の大きな障壁となっていましたが、本研究が提案する「CAUSALEMBED」は、自己回帰的な生成プロセスを通じて潜在空間内にマルチベクトル埋め込みを逐次的に構築することで、この課題を根本から解決します。 この手法は、反復的なマージン損失を用いた漸進的洗練損失と多様性正則化を導入した対照学習を用いることで、コンパクトかつ高度に構造化された表現の学習を可能にし、従来のパッチベースの並列エンコーディングから脱却して、わずか数十個のトークンのみで効率的かつ高精度な検索を実現する新しい生成パラダイムを提示しています。 検証の結果、トークン数を30倍から155倍という極めて高い比率で削減しながらも、既存のプルーニングやクラスタリング手法を一貫して凌駕する検索精度を達成し、さらに推論時に生成するトークン数を調整することで精度を動的に変更できる「テストタイムスケーリング」という独自の特性も確認されており、実用性と柔軟性を両立させています。
TL;DR(結論)
視覚的文書検索(VDR)において、従来のマルチベクトル手法は1ページあたり数千ものトークンを必要とし、膨大なストレージ負荷が実用化の大きな障壁となっていましたが、本研究が提案する「CAUSALEMBED」は、自己回帰的な生成プロセスを通じて潜在空間内にマルチベクトル埋め込みを逐次的に構築することで、この課題を根本から解決します。 この手法は、反復的なマージン損失を用いた漸進的洗練損失と多様性正則化を導入した対照学習を用いることで、コンパクトかつ高度に構造化された表現の学習を可能にし、従来のパッチベースの並列エンコーディングから脱却して、わずか数十個のトークンのみで効率的かつ高精度な検索を実現する新しい生成パラダイムを提示しています。 検証の結果、トークン数を30倍から155倍という極めて高い比率で削減しながらも、既存のプルーニングやクラスタリング手法を一貫して凌駕する検索精度を達成し、さらに推論時に生成するトークン数を調整することで精度を動的に変更できる「テストタイムスケーリング」という独自の特性も確認されており、実用性と柔軟性を両立させています。
なぜこの問題か
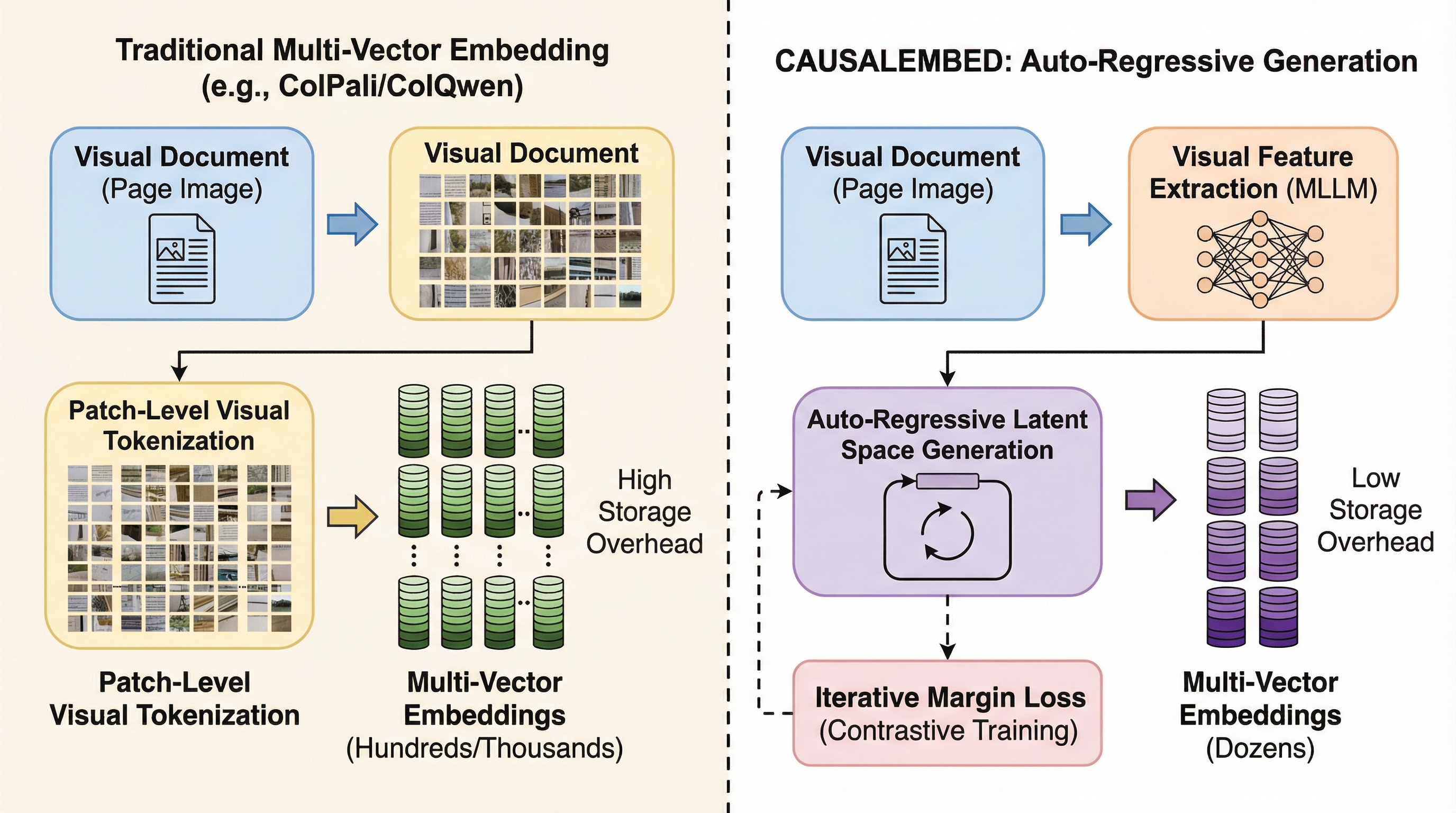
現代の情報システムにおいて、膨大な文書アーカイブから関連するページを特定する視覚的文書検索(VDR)は、企業内検索やドメイン固有の検索拡張生成(RAG)を支える極めて重要な基盤技術となっています。従来のテキストベースの検索システムは、光学文字認識(OCR)を用いて内容を抽出していましたが、このプロセスでは文書の重要な視覚的構造やレイアウト情報が失われるという致命的な欠点がありました。これに対し、近年の研究ではマルチモーダル大規模言語モデル(MLLM)を活用し、文書ページを視覚的な実体として直接扱うアプローチが主流となっています。初期のVDR手法では、ページ全体を単一のベクトルにエンコードするシングルベクトル表現が用いられていましたが、この方式では内容が密集したページの複雑な視覚情報を十分に捉えきれないという表現能力の限界がありました。 この問題を解決するために登場したのが、ColPaliに代表されるマルチベクトル手法です。これは、ページを数百から数千のパッチレベルのトークンとして表現し、クエリとの局所的な対応関係を計算することで、極めて高い検索精度を実現しました。…
核心:何を提案したのか
本研究では、従来の並列的なパッチベースのエンコーディング手法から完全に脱却し、マルチベクトル埋め込みを逐次的かつ自己回帰的に生成する新しいフレームワーク「CAUSALEMBED」を提案しています。これは、事前学習済みのMLLMをファインチューニングし、潜在的な表現をトークンごとに合成させる手法です。このアプローチの核心は、文書の埋め込みを単なる「抽出」ではなく、情報の重要度に応じた「生成」のプロセスとして再定義した点にあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related