自己改善型事前学習:事後学習済みモデルを用いた、より優れたモデルの事前学習
大規模言語モデルの安全性や事実性を根本から高めるため、従来の次単語予測に代わり、事後学習済みの強力なモデルを「判定役」および「書き換え役」としてループに組み込み、強化学習を用いてシーケンス単位で最適化する「自己改善型事前学習」を提案している。
TL;DR(結論)
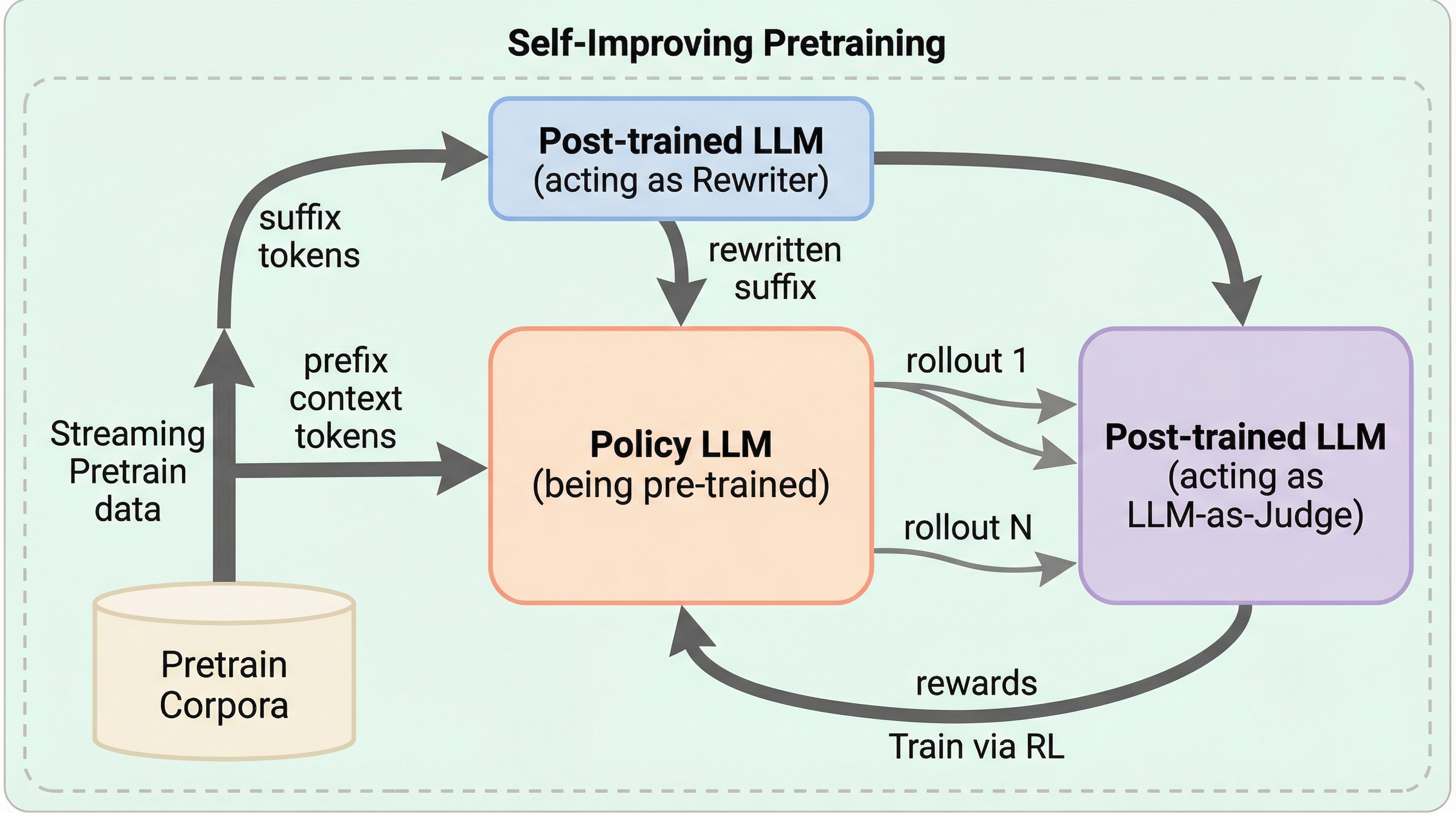
大規模言語モデルの安全性や事実性を根本から高めるため、従来の次単語予測に代わり、事後学習済みの強力なモデルを「判定役」および「書き換え役」としてループに組み込み、強化学習を用いてシーケンス単位で最適化する「自己改善型事前学習」を提案している。 この手法では、学習データから抽出した文脈に対して、元の続き、教師モデルによる改善案、モデル自身の生成結果の3種を比較・評価することで、学習の初期段階から高品質で安全な振る舞いをモデルの核心的な特性として定着させることが可能になる。 実験では、標準的な事前学習と比較して事実性で36.2%、安全性で18.5%の相対的な改善を達成し、生成品質の勝率においては最大86.3%という大幅な向上を記録しており、事前学習段階での介入がモデルの信頼性を形作る上で極めて有効であることを示した。
なぜこの問題か
大規模言語モデル(LLM)を実世界のアプリケーションに展開する際、生成内容の安全性、事実性、および全体的な品質を保証することは極めて重要な課題である。現在の主流なアプローチは、高価で注意深く精選されたデータセットを収集し、事前学習が終わった後に複数の段階の微調整やアライメント、いわゆる事後学習を適用することである。しかし、このような複雑なパイプラインを経ても、事前学習中に学習された好ましくないパターンを完全に修正できる保証はない。事前学習はモデルの核心的な振る舞いを形成する段階であり、この時点で不安全な出力やハルシネーション(幻覚)の原因となるパターンが深く埋め込まれてしまうと、後からの修正が困難になるという根源的な問題がある。 標準的な事前学習は、主に人間が書いた大規模なコーパス上で次のトークンを予測することによって行われる。しかし、人間が書いた文書は品質、安全性、事実性の面で大きくばらつきがある。低品質な文書を特定して削除するデータのキュレーションも行われているが、依然として毒性や偏見、不安全な応答が含まれる可能性を完全に排除しきれない。…
核心:何を提案したのか
本研究では、従来の次単語予測パラダイムとは大きく異なる「自己改善型事前学習(Self-Improving Pretraining)」という新しいスキームを提案している。この手法の核心は、すでに十分に訓練された強力な「事後学習済みモデル」を教師として活用し、新しいモデルの事前学習をガイドすることにある。この教師モデルは、以前の自己改善サイクルの反復から得られたモデルなどを想定しており、事前学習データセット内の個々の事例に対して、それ自体が学習に使われた信号よりも優れたトレーニング信号を提供することができる。これにより、モデルは最初から高品質な知識を吸収することが可能になる。 具体的には、事前学習を単なるトークン予測ではなく、シーケンス(連続した単語列)の生成タスクとして再定義している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related