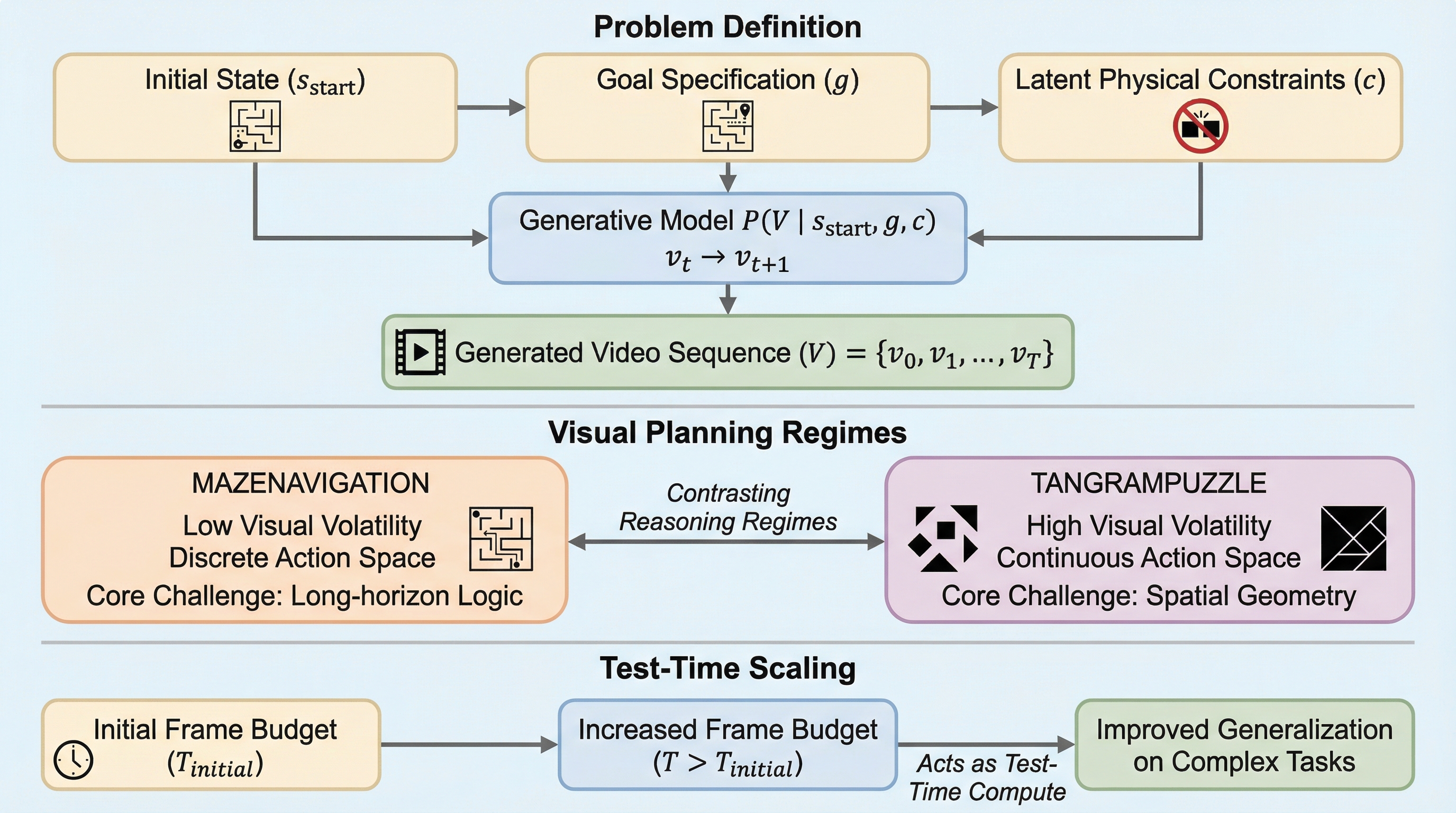
フレームで考える:視覚的コンテキストとテスト時スケーリングがいかにビデオ推論を強化するか
従来のマルチモーダル大規模言語モデル(MLLM)は、テキストベースの推論において優れた成果を収めてきましたが、物理的なダイナミクスや精密な空間的理解を必要とするタスクには依然として課題を抱えています。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
従来のマルチモーダル大規模言語モデル(MLLM)は、テキストベースの推論において優れた成果を収めてきましたが、物理的なダイナミクスや精密な空間的理解を必要とするタスクには依然として課題を抱えています。
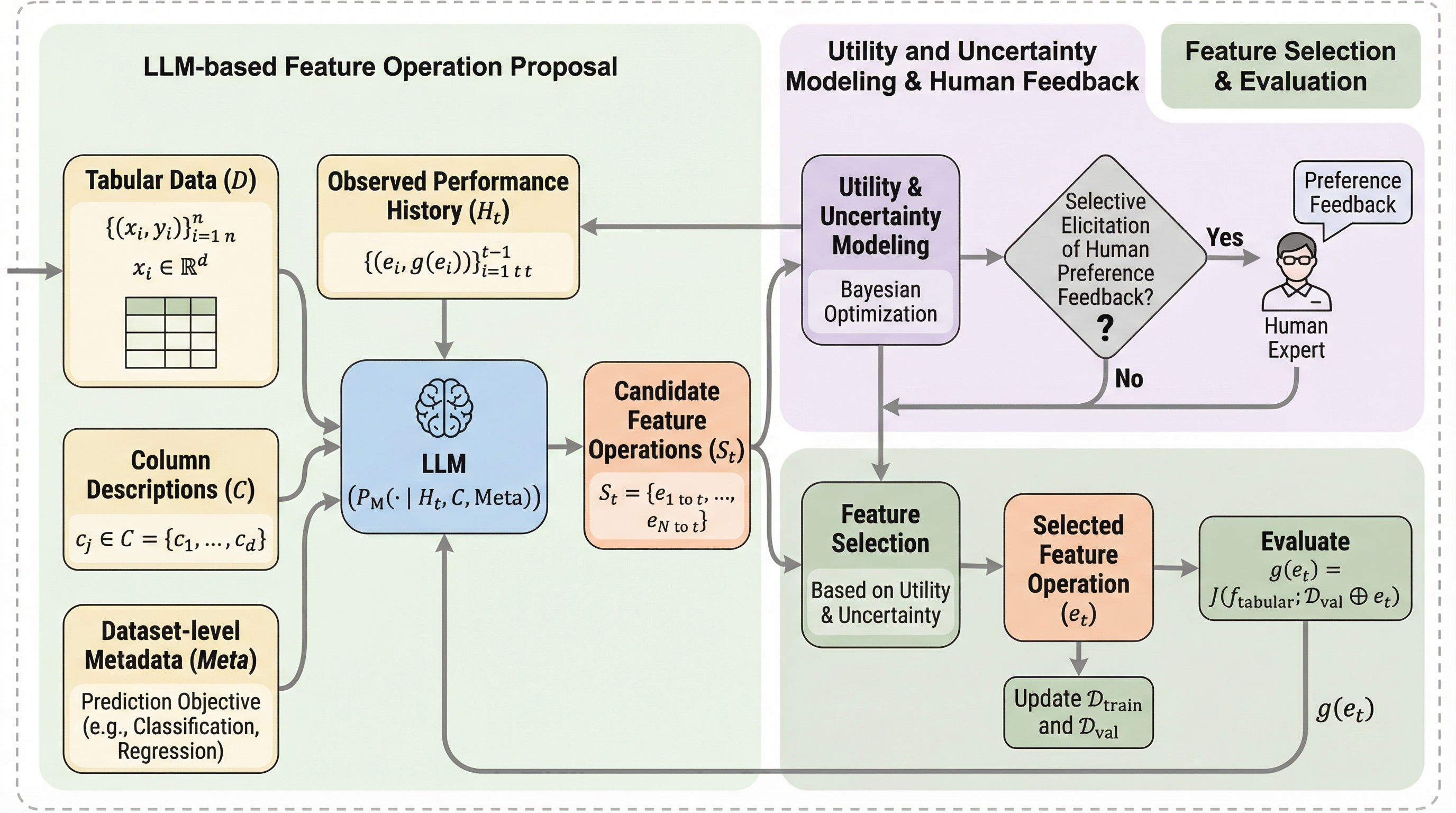
大規模言語モデルを特徴量候補の提案役に特化させ、その選択プロセスをベイズ最適化に基づく効用モデルと分離することで、モデルの内部的な直感に頼った非効率な探索を排除し、低収益な操作の繰り返しを抑制する新しいフレームワークを提案した。
従来の低ランク適応(LoRA)は、入力される全てのトークンに対して一律に固定されたランクを適用していましたが、本研究ではトークンの複雑さに応じてシーケンスを可変長のチャンクに分割し、動的にランクを割り当てる「ChunkWise LoRA」を提案しました。
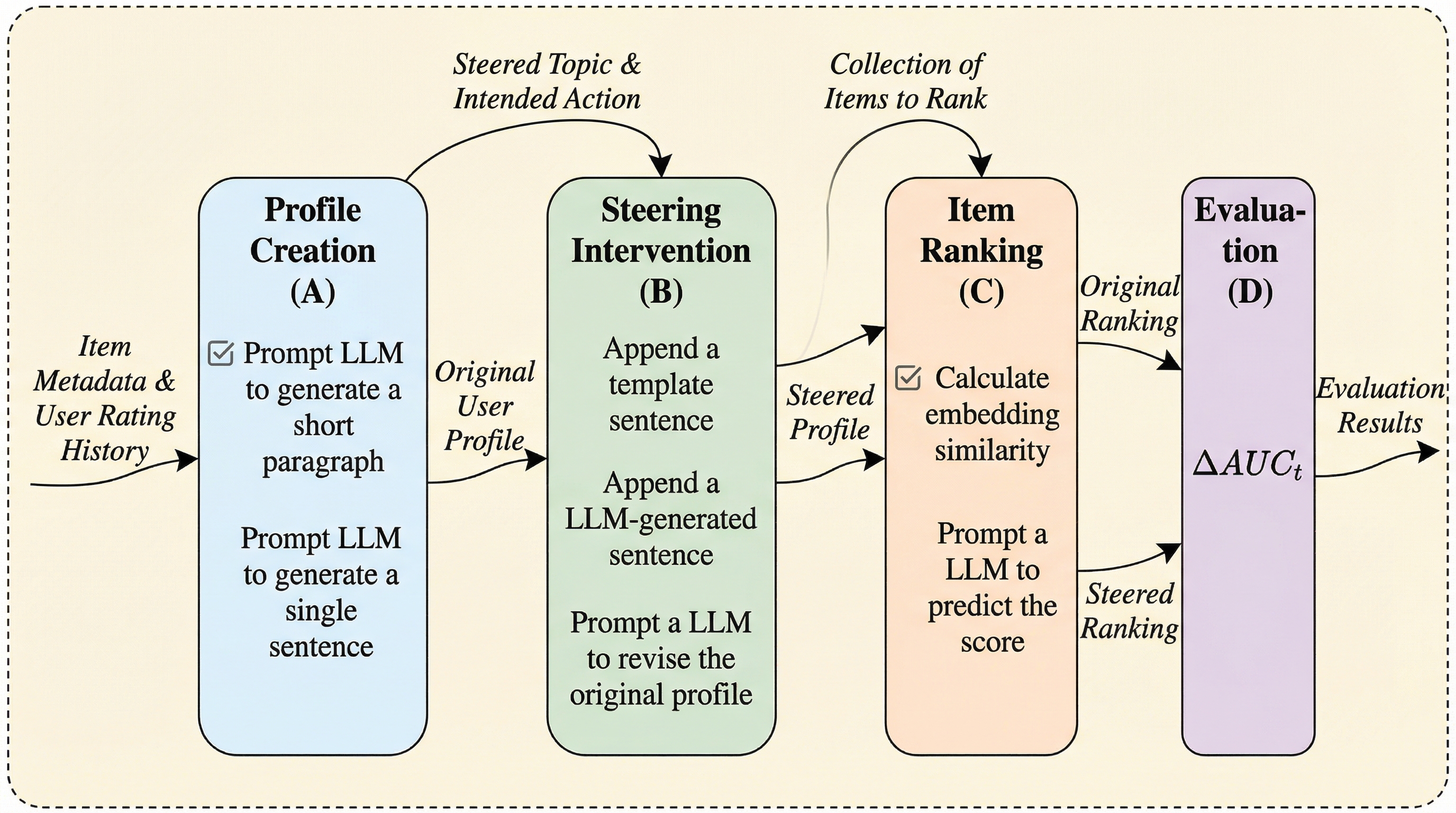
自然言語プロファイルを用いた推薦システムは、ユーザーが自分の好みをテキストで直接編集できるため、従来の数値ベクトル形式よりも高い透明性と操作性を提供しますが、これまでの評価は映画のジャンルなどの限定的な属性に留まっており、多様な要求への対応力は不明でした。
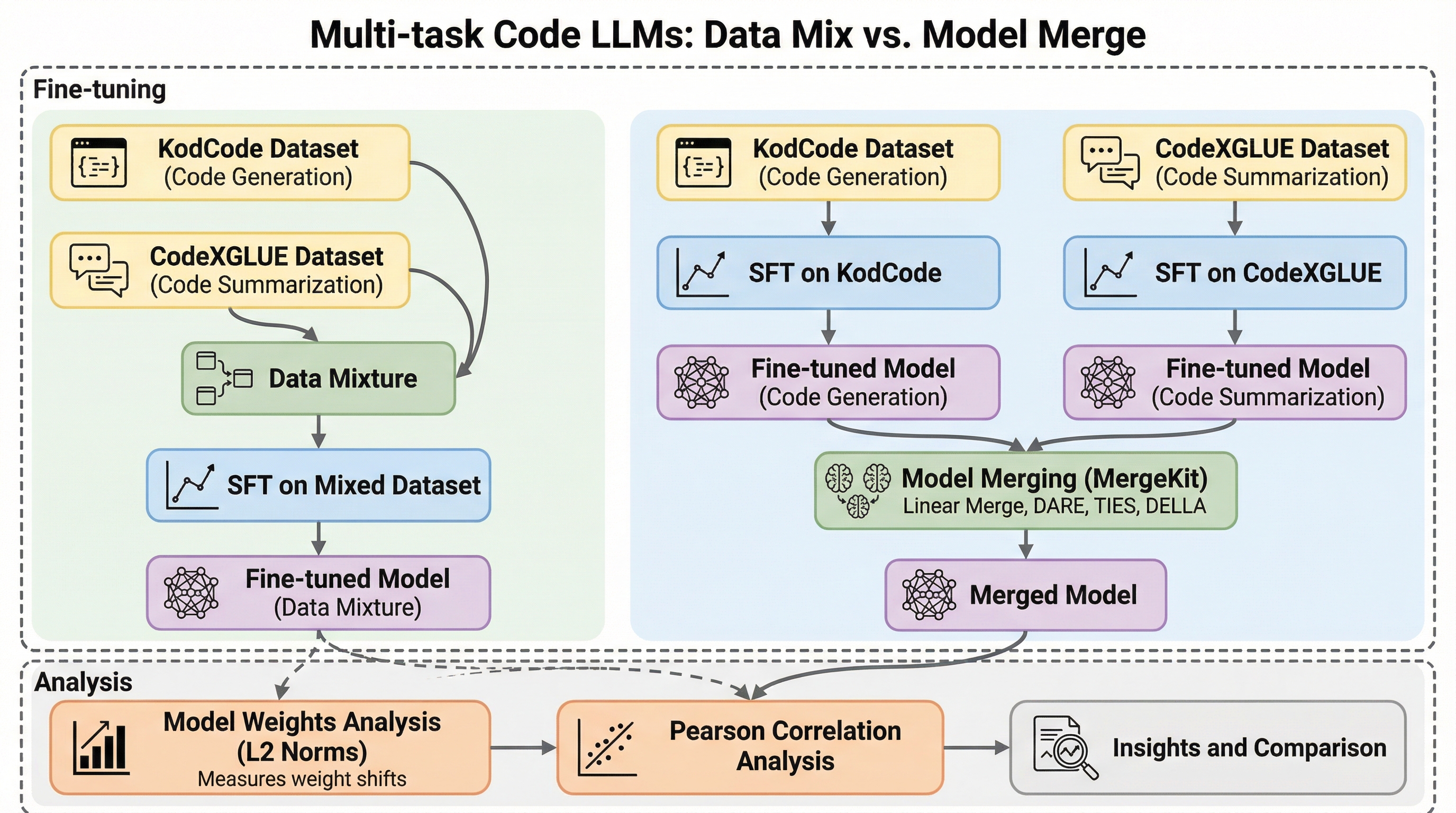
本研究では、コード生成とコード要約という二つの主要なタスクを同時にこなす小規模なコードLLMを構築する際、学習データを混ぜて一度に微調整する「データ混合」と、個別に学習した専門モデルを統合する「モデルマージ」のどちらが有効かを、Qwen CoderやDeepSeek Coderを用いて詳細に調査した。 実験の結果、1.
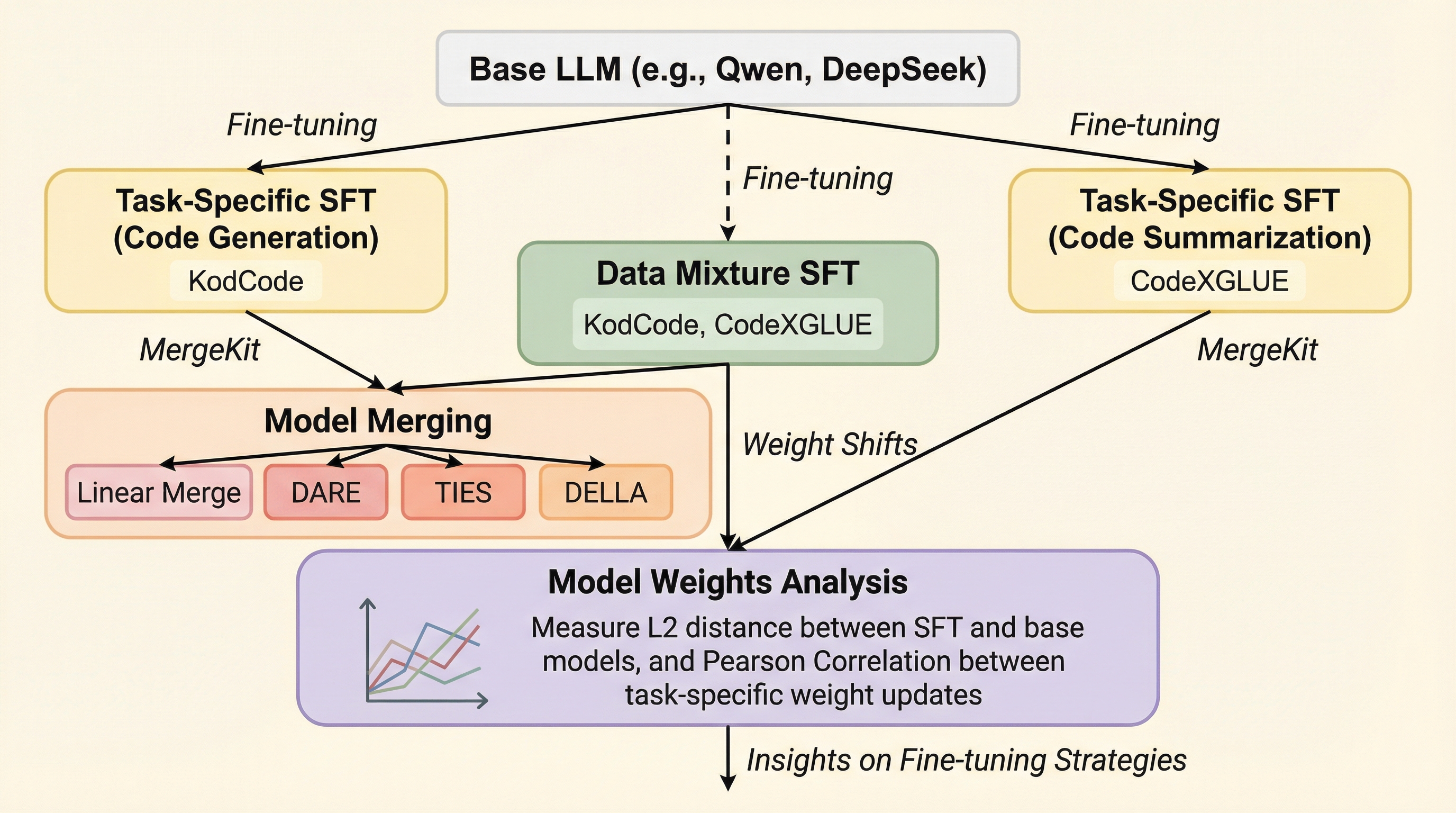
本研究は、小規模なコード特化型LLM(Qwen2.5-CoderおよびDeepSeek-Coder)において、複数のタスクを効率的に習得させるための最適な学習戦略を、1.5Bから7Bのモデル規模で比較検証しました。 検証の結果、1.
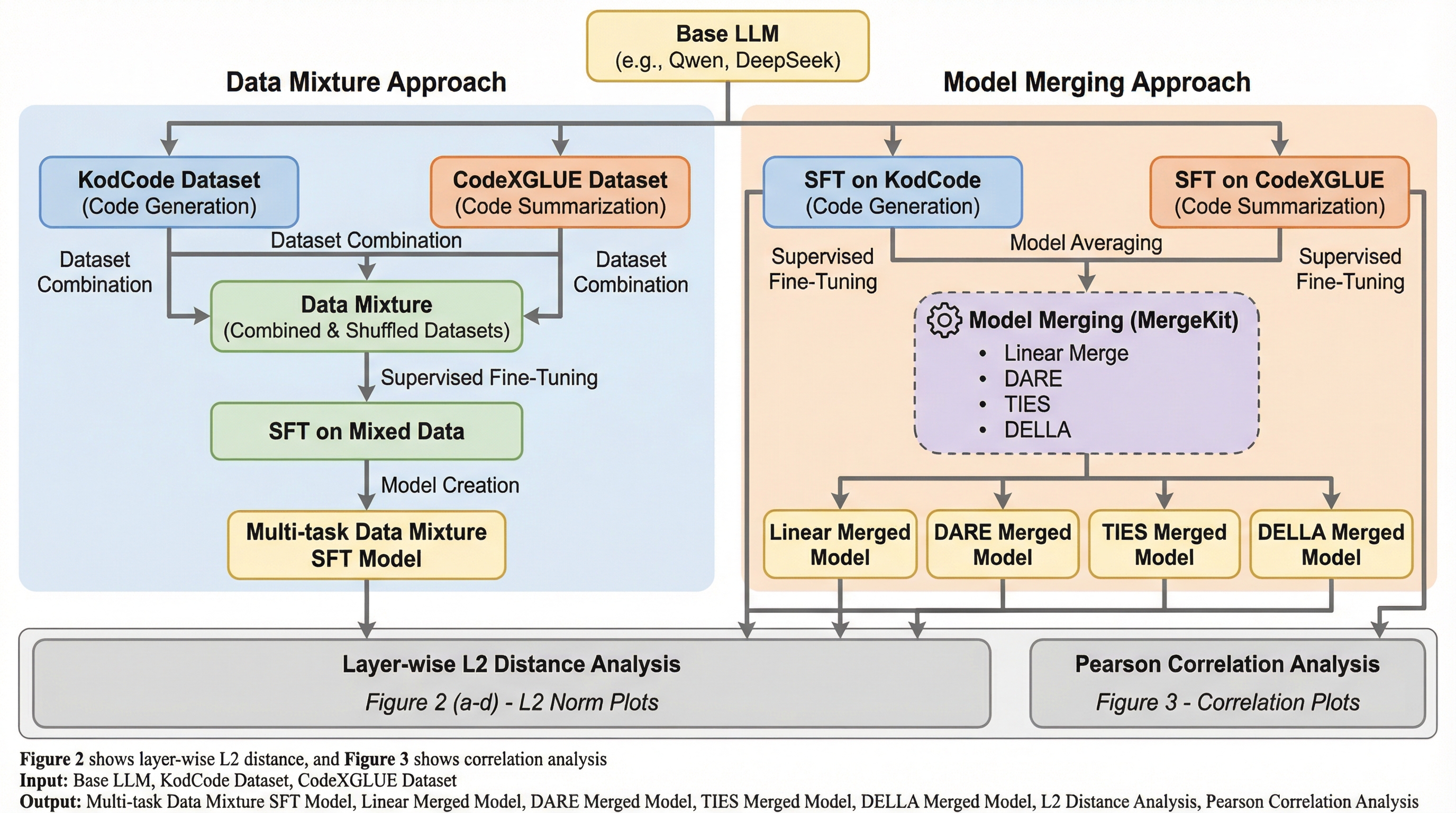
本研究では、小規模なコード特化型LLMをマルチタスク化する際、学習データを混ぜて微調整する「データ混合」と、個別に学習したモデルを統合する「モデルマージ」のどちらが有効かを体系的に調査しました。Qwen2.
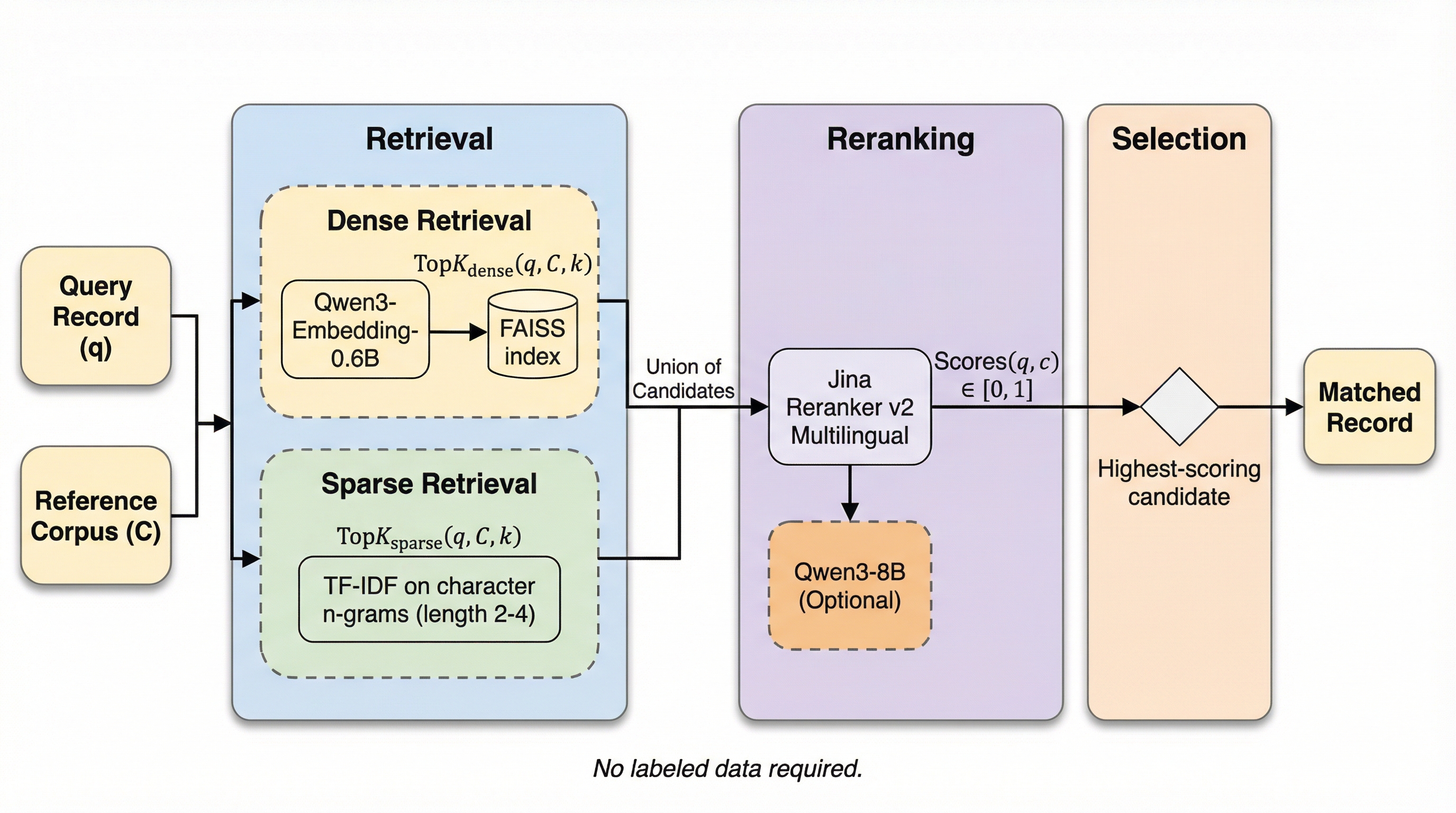
異なるデータセット間で同一の主体を特定するレコードリンケージにおいて、教師データを一切必要とせずに高い精度を達成する新手法「EnsembleLink」が提案されました。この手法は大規模なテキストコーパスで事前学習された言語モデルが持つ意味的な関係性の理解力を活用しており、都市名や人名、組織名、多言語の政党名といった多様なベンチマークにおいて、大量のラベルを必要とする既存の教師あり学習手法と同等、あるいはそれ以上の性能を記録しています。ローカル環境のオープンソースモデルのみで動作するため外部APIへの依存がなく、一般的な消費者向けハードウェアでも数分で処理を完了できる実用性を備えており、これまでアドホックな規則に頼っていたデータ統合プロセスの精度と信頼性を大幅に向上させることが期待されます。
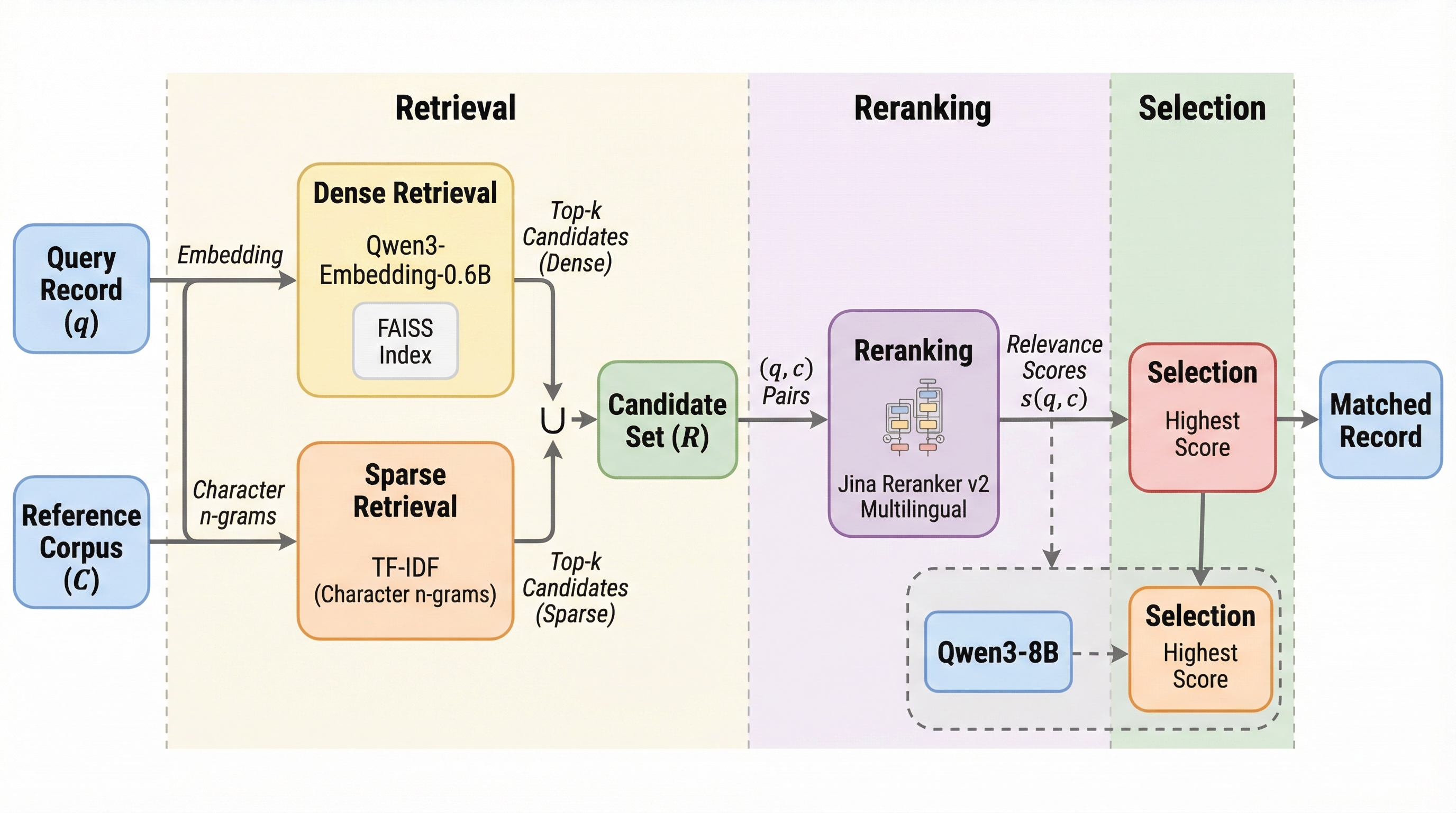
レコードリンケージは、異なるデータセット間で同一のエンティティを指すレコードを照合するプロセスであり、社会科学において不可欠ですが、現在は場当たり的なルールが適用されるなど手法として未発達な側面があります。
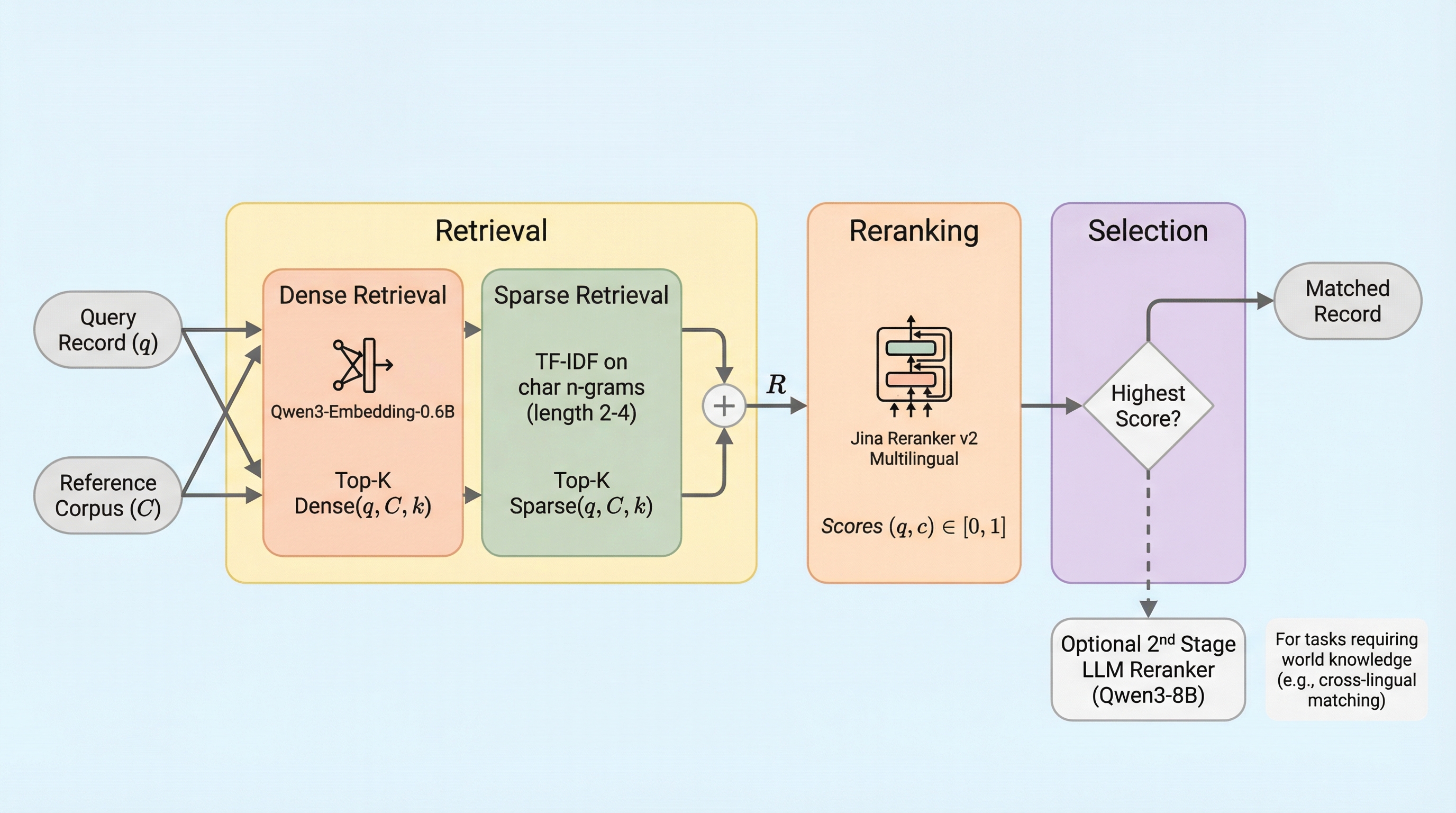
レコードリンケージは異なるデータセット間で同一の対象を照合する重要な工程だが、従来は場当たり的な規則や大量の学習データに依存しており、誤差の定量化も不十分であった。本論文が提案する「EnsembleLink」は、事前学習済み言語モデルのセマンティックな理解力を活用することで、学習データを一切使わずに、都市名や人名、組織名、多言語の政党名などの照合において教師あり学習手法と同等以上の高精度を達成した。 この手法は、密なベクトル検索と文字単位の疎な検索を組み合わせた候補抽出、およびクロスエンコーダによる高精度な再ランク付けという3段階のパイプラインで構成されており、オープンソースの軽量モデルを用いてローカル環境で実行できる。検証の結果、ニックネームや略称、非直訳の多言語対応など、従来のファジーマッチングでは困難だった複雑な照合を数分で完了させることが可能であり、社会科学などの実証研究におけるデータ統合の信頼性を大きく向上させる。 利用者は外部APIを呼び出すことなく、民生用ハードウェア上でプライバシーを保ちながら高速に処理を行うことができ、さらにモデルの重みが固定されているため結果の再現性も保証される。本手法は、都市名照合で90%、有権者照合で99%という極めて高い精度を記録しており、数千のラベルを必要とする既存の最先端手法に匹敵する性能をゼロショットで提供する画期的なツールである。