マルチタスク・コードLLM:データミックスか、モデルマージか?
本研究では、小規模なコード特化型LLMをマルチタスク化する際、学習データを混ぜて微調整する「データ混合」と、個別に学習したモデルを統合する「モデルマージ」のどちらが有効かを体系的に調査しました。Qwen2.
TL;DR(結論)
本研究では、小規模なコード特化型LLMをマルチタスク化する際、学習データを混ぜて微調整する「データ混合」と、個別に学習したモデルを統合する「モデルマージ」のどちらが有効かを体系的に調査しました。Qwen2.5-CoderやDeepSeek-Coderを用いた広範な実験の結果、モデルの規模によって最適な戦略が劇的に異なることが判明し、1.5B前後の小規模モデルではデータ混合が、7B規模のモデルではモデルマージが、それぞれ最も高い性能を発揮することが明らかになりました。特に7B規模でのマージは、単一タスクに特化したモデルの性能を維持するだけでなく、Qwen2.5-Coder 7BにおいてHumanEvalのPass@1が92.7%に達するなど、専門モデルを上回る成果を記録する場合もあり、リソース制約下での効率的なデプロイに向けた重要な指針を提示しています。
なぜこの問題か
近年、エージェント指向のフレームワークにおいて、巨大なフロンティアモデルをあらゆるタスクに使用するのではなく、より小規模で特定のタスクに特化したコードLLMをデプロイすることの重要性が提唱されています。しかし、実際の運用環境では、単一のモデルが複数のコーディングタスクをこなす必要があるため、リソースを節約しつつ、特定のタスクに特化した性能を維持、あるいは向上させるための効率的なマルチタスク学習戦略が求められています。この課題に対し、ハイパースペシャライゼーション、リソース制約、そして生成品質のバランスをどのように取るべきかが、コストや推論時間、品質の観点から重要な議論となっています。これまで、自然言語処理の分野ではデータ混合やモデルマージの研究が進んできましたが、コード特化型LLMにおける両手法の比較分析や、モデルの規模が戦略の有効性に与える影響については、これまで十分に解明されてきませんでした。 特に、コード生成やコード要約といった、相互に関連しながらも異なる性質を持つタスクを統合する際、どのようなアプローチが最適であるかを知ることは、実用的なAIコーディングアシスタントの開発において極めて重要です。…
核心:何を提案したのか
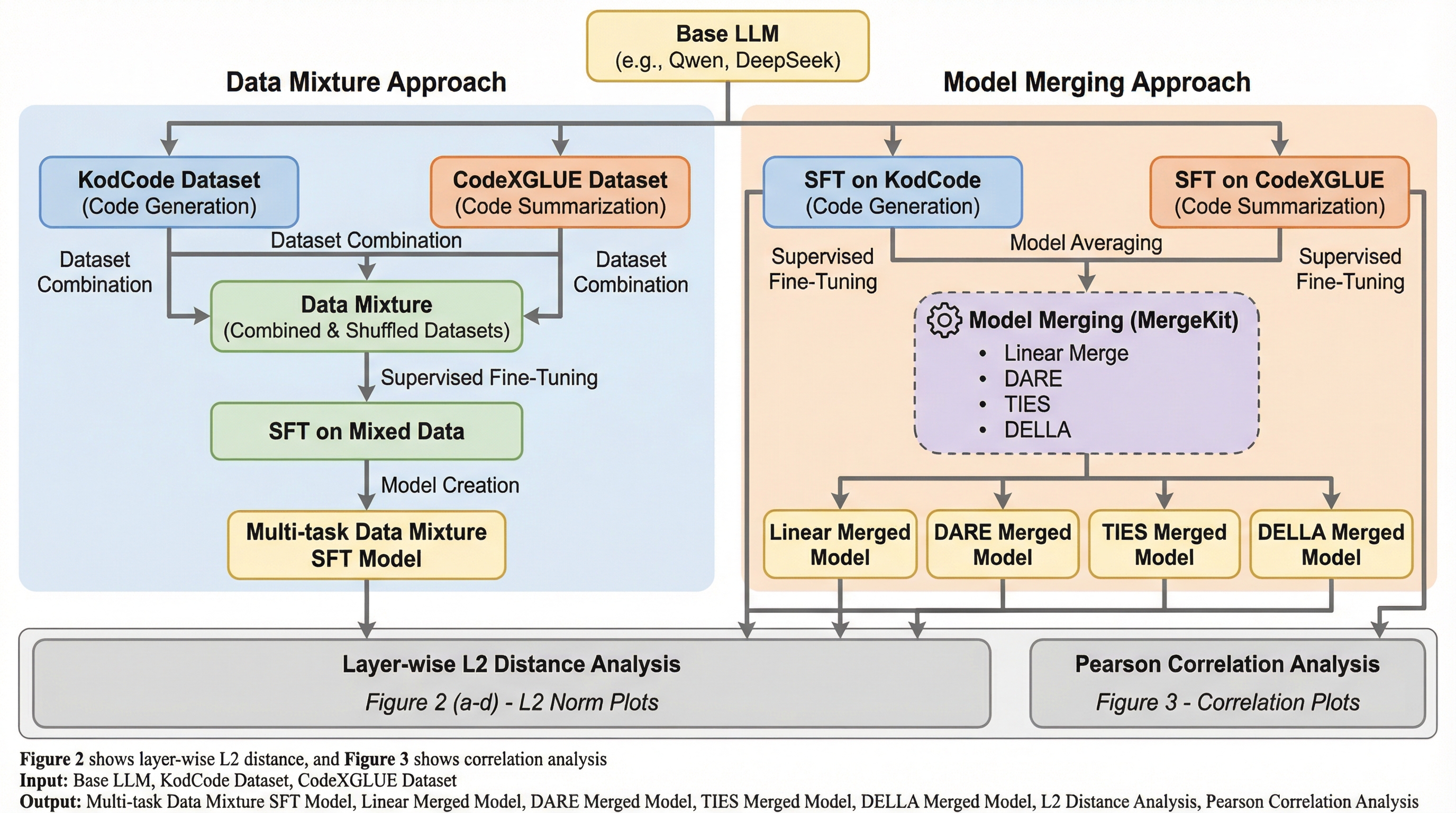
本研究では、マルチタスク対応の小規模コードLLMを構築するための二つの主要なアプローチ、すなわち「データ混合(Data Mixing)」と「モデルマージ(Model Merging)」を広範に比較することを提案しました。具体的には、Qwen2.5-CoderおよびDeepSeek-Coderという二つの主要なモデルファミリーを使用し、それぞれ約1.5B(または1.3B)と7Bという二つの異なるパラメータ規模で実験を行いました。対象とするタスクは、自然言語の記述からコードを生成する「コード生成」と、コードの内容を自然言語で説明する「コード要約」の二種類です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related