マルチタスク・コードLLM:データの混合か、モデルの統合か?
本研究は、小規模なコード特化型LLM(Qwen2.5-CoderおよびDeepSeek-Coder)において、複数のタスクを効率的に習得させるための最適な学習戦略を、1.5Bから7Bのモデル規模で比較検証しました。 検証の結果、1.
TL;DR(結論)
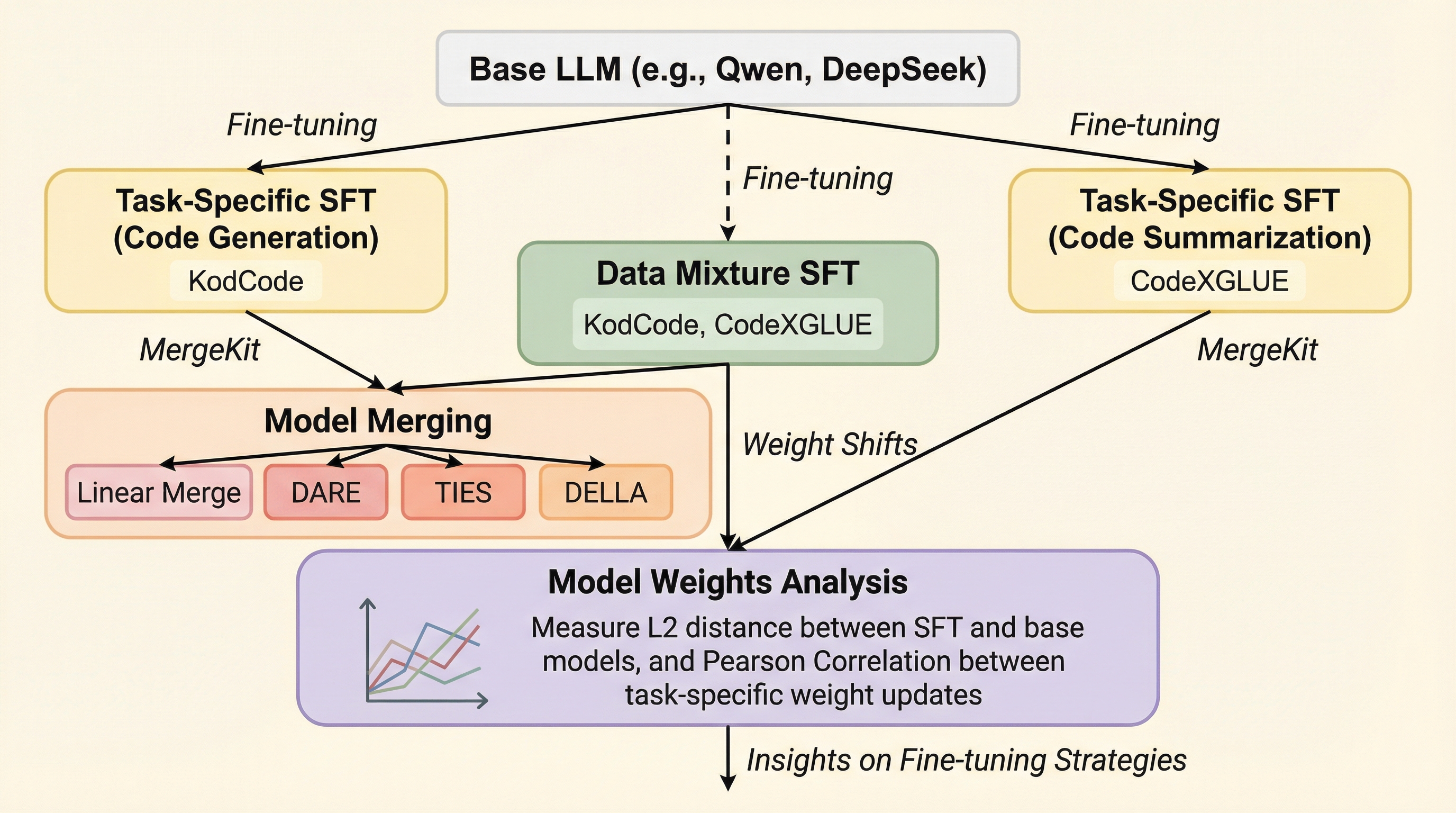
本研究は、小規模なコード特化型LLM(Qwen2.5-CoderおよびDeepSeek-Coder)において、複数のタスクを効率的に習得させるための最適な学習戦略を、1.5Bから7Bのモデル規模で比較検証しました。 検証の結果、1.5B規模の小規模モデルでは学習データを事前に混ぜて微調整する「データ混合」が優位である一方、7B規模では個別に学習させたモデルを統合する「モデルマージ」が専門モデルの性能を維持し、特定のタスクでは専門モデルを上回る性能を記録することが判明しました。 この性能差はモデルのパラメータ空間におけるタスク間の干渉度合いに起因しており、規模が大きくなるほどタスクごとの更新が直交(独立)しやすくなるため、マージが有効になるという重要な設計指針を提示しています。
なぜこの問題か
現代のソフトウェア開発において、すべての処理を巨大な汎用モデルに頼るのではなく、特定のタスクに特化した小規模なコードLLMをエージェントとして活用する手法が注目を集めています。しかし、実用的な場面ではコード生成やコード要約といった複数の機能を一つのモデルで効率的に実行できることが求められます。リソースが限られた環境では、計算コストや推論時間を抑えつつ、高い専門性を維持したままマルチタスク化することが大きな課題となっていました。これまでの研究では、複数のデータを混ぜて一度に学習させる方法と、個別の専門モデルを訓練した後に重みを統合する方法の二つが提案されてきましたが、コードLLMという特有の領域においてどちらが優れているかは不明でした。 特に、モデルのパラメータ数や学習データの規模が、これらの戦略の有効性にどのような影響を与えるのかという点は、効率的なデプロイ戦略を立てる上で不可欠な知見です。小規模モデル特有の制約の中で、いかにしてタスク間の負の干渉を避け、相乗効果を引き出すかという問いに答えることが、実用的なAIシステム構築における障壁を打破するために必要とされていました。…
核心:何を提案したのか
本論文では、小規模なコードLLMをマルチタスク化するための二つの主要なアプローチ、すなわち「データ混合による教師あり微調整(Data-mixture SFT)」と「事後的なモデルマージ(Post-hoc Model Merging)」を包括的に比較することを提案しました。この検証のために、Qwen2.5-Coder(1.5Bおよび7B)とDeepSeek-Coder(1.3Bおよび7B)という、業界で広く利用されている二つのモデルファミリーを採用しています。具体的には、コード生成とコード要約という、性質は異なるものの相互に関連する二つのタスクを対象とし、それぞれのタスクに特化した専門モデルを構築しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related