マルチタスク・コードLLM:データミックスか、モデルマージか?
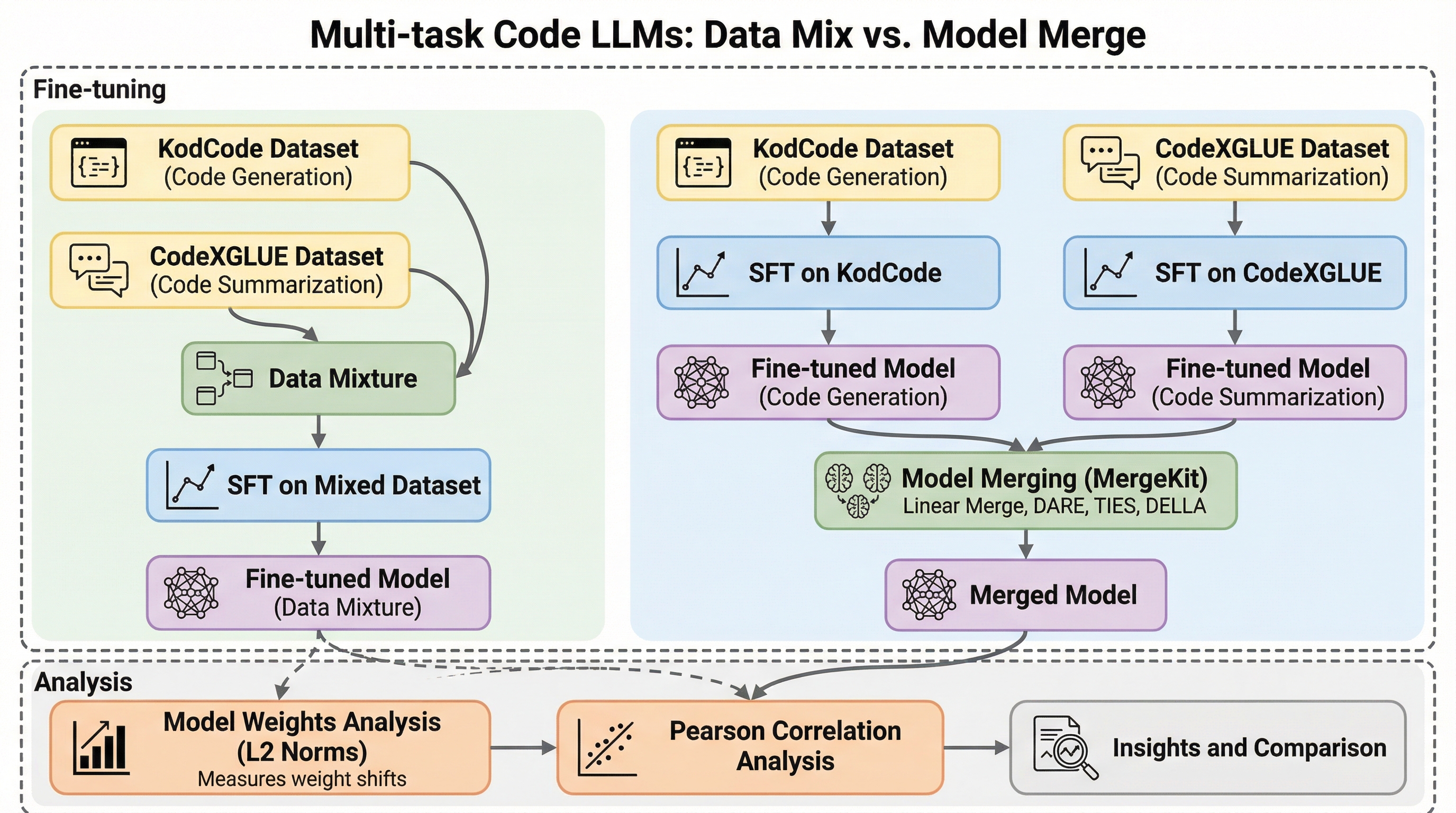
本研究では、コード生成とコード要約という二つの主要なタスクを同時にこなす小規模なコードLLMを構築する際、学習データを混ぜて一度に微調整する「データ混合」と、個別に学習した専門モデルを統合する「モデルマージ」のどちらが有効かを、Qwen CoderやDeepSeek Coderを用いて詳細に調査した。 実験の結果、1.
TL;DR(結論)
本研究では、コード生成とコード要約という二つの主要なタスクを同時にこなす小規模なコードLLMを構築する際、学習データを混ぜて一度に微調整する「データ混合」と、個別に学習した専門モデルを統合する「モデルマージ」のどちらが有効かを、Qwen CoderやDeepSeek Coderを用いて詳細に調査した。 実験の結果、1.5B規模の小型モデルではデータ混合が優位であったが、7B規模のモデルではモデルマージが専門モデルと同等以上の性能を発揮し、特にQwen Coder 2.5 7BではHumanEvalで92.7%という専門モデル(90.9%)を上回る高い数値を記録した。 この性能差の要因として、モデルの規模が大きくなるほど各タスクの重み更新が互いに干渉しにくい直交的な経路を利用するようになるという、重み空間の相関分析による知見が示されており、リソース制約下での最適なモデル構築戦略を提案している。
なぜこの問題か
近年、あらゆるタスクに大規模なフロンティアモデルを利用するのではなく、エージェントフレームワークの中で特定のタスクに特化した小規模なコードLLMを配置する手法が注目されている。しかし、実際の開発現場や運用においては、単一のタスクだけでなく、コード生成やコードの要約といった複数のコーディングタスクを効率的に処理できる能力が求められる。限られた計算資源、厳しいコスト制約、そして推論時間の短縮という要求の中で、高い専門性を維持しつつ多機能なモデルを実現することは、実用上の大きな課題となっている。これまでの研究では、複数のタスクのデータを混ぜて一度に教師あり微調整(SFT)を行う「データ混合」の手法や、個別に学習された複数のモデルの重みを事後的に統合する「モデルマージ」の手法がそれぞれ個別に進展してきた。しかし、コードLLMという特定の領域において、これら二つのアプローチのどちらがより効果的であるかという比較分析はこれまで十分に行われてこなかった。 特に、モデルのパラメータ数や学習データの規模が、最適な戦略の選択にどのように影響を与えるかという点は不明確なままであった。…
核心:何を提案したのか
本研究では、小規模なマルチタスク・コードLLMを作成するための二つの主要なアプローチ、すなわち「データ混合(Data Mixing)」と「モデルマージ(Model Merging)」を系統的に比較することを提案した。具体的には、Qwen Coder(Qwen2.5-Coder)とDeepSeek Coderという二つの代表的なモデルファミリーを使用し、それぞれ約1.5B(または1.3B)と7Bという二つのパラメータスケールで広範な実験を実施した。対象とするタスクは、自然言語の問題記述からコードを記述する「コード生成」と、与えられたコードに対して簡潔で情報量のある自然言語の説明を生成する「コード要約」の二つである。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related