フレームで考える:視覚的コンテキストとテスト時スケーリングがいかにビデオ推論を強化するか
従来のマルチモーダル大規模言語モデル(MLLM)は、テキストベースの推論において優れた成果を収めてきましたが、物理的なダイナミクスや精密な空間的理解を必要とするタスクには依然として課題を抱えています。
TL;DR(結論)
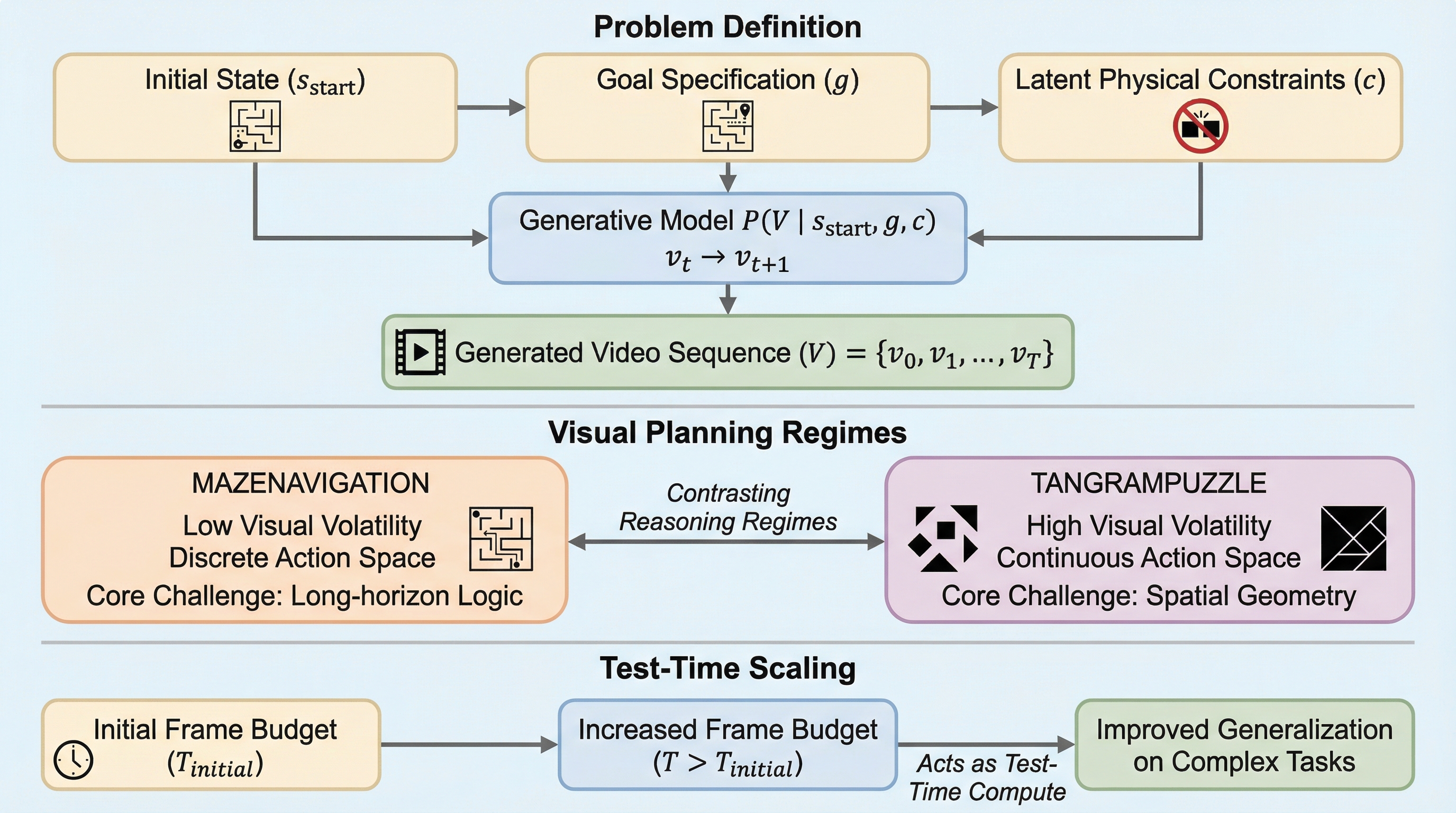
従来のマルチモーダル大規模言語モデル(MLLM)は、テキストベースの推論において優れた成果を収めてきましたが、物理的なダイナミクスや精密な空間的理解を必要とするタスクには依然として課題を抱えています。これに対し、ビデオ生成モデルを「視覚的推論器」として活用し、生成される各フレームを解決に至るまでの中間的な思考ステップと定義することで、高帯域な視覚ドメインで直接計画を立案・実行する新しい推論パラダイムが提案されました。 迷路ナビゲーションとタングラムパズルの2つの異なるタスクを用いた検証により、ビデオ生成モデルは未知のデータ分布に対しても強力なゼロショット一般化性能を発揮することが証明されました。特に、エージェントのアイコンやパズルの形状といった視覚的コンテキストを明示的な制御信号として利用することで、高い視覚的一貫性を維持しながら、テキストでは表現困難な複雑な幾何学的制約を伴う問題を解決できることが明らかになりました。 生成するビデオのフレーム数、すなわち推論予算を増やすことで、空間的・時間的に複雑な経路計画の成功率が大幅に向上するという「視覚的テスト時スケーリング則」がビデオドメインにおいて初めて発見されました。この成果は、ビデオ生成が単なる動画制作のためのメディアツールに留まらず、計算量を調整することで能力を拡張できる、汎用的かつスケーラブルな視覚的推論の基盤になり得ることを示唆しています。
なぜこの問題か
現在のマルチモーダル大規模言語モデル(MLLM)は、視覚的な意味理解やテキストベースの論理推論において目覚ましい進歩を遂げていますが、物理的な世界における空間的な推論や連続的な行動計画においては依然として大きな限界に直面しています。その根本的なボトルネックの一つは、推論の媒体としてテキストを用いている点にあります。複雑な迷路内での衝突を回避する軌道や、タングラムのピースを精密に回転・配置するプロセスを言葉だけで正確に記述することは、情報の密度が低く、非常に非効率的です。例えば、ピースの連続的な回転角度や座標をテキストで表現しようとすると、幾何学的な文脈や物理的なダイナミクスを正確に捉えきれず、結果として実行不可能な計画が出力されることが多々あります。 これまでの視覚的推論の研究は、主に静的な画像や離散的な行動を扱うグリッドワールドのような環境に限定されており、視覚的な変化が激しい連続的な操作タスクについては十分に探索されてきませんでした。また、既存のモデルは学習データと同じ分布内での評価に留まることが多く、未知の形状やより大規模な問題に対する一般化能力、いわゆる「分布外(OOD)」への適応力が不足していました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related