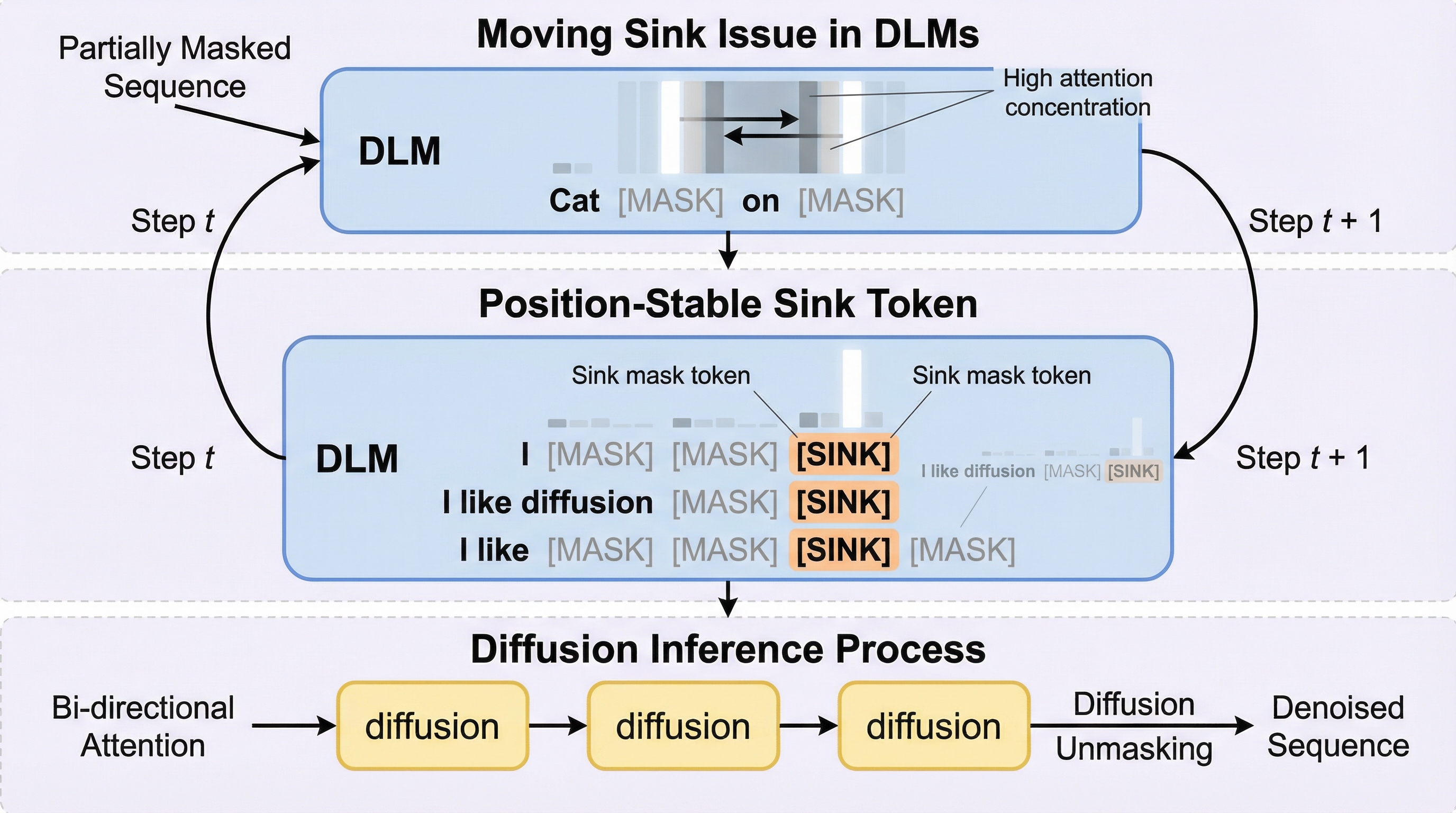
1トークンで十分:シンクトークンによる拡散言語モデルの改善
拡散言語モデル(DLM)において、注意機構の計算過程で不要な情報を逃がす「シンク(掃き出し口)」となるトークンの位置がステップごとに不規則に変動する「移動シンク現象」が、生成の不安定性や性能低下の主要因であることを特定しました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
拡散言語モデル(DLM)において、注意機構の計算過程で不要な情報を逃がす「シンク(掃き出し口)」となるトークンの位置がステップごとに不規則に変動する「移動シンク現象」が、生成の不安定性や性能低下の主要因であることを特定しました。
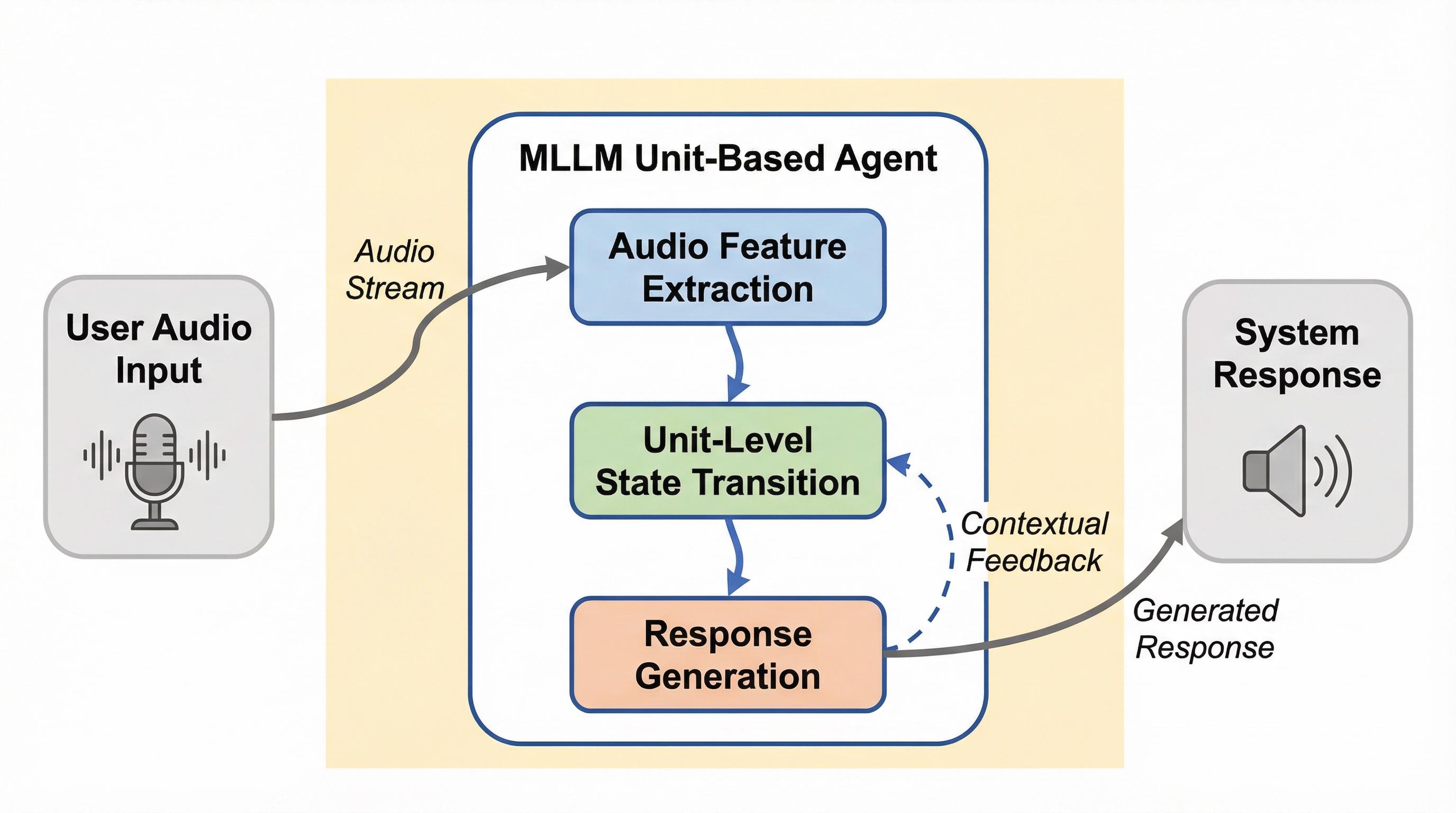
本研究では、複雑な音声対話を「対話ユニット」という最小単位に分解し、マルチモーダル大規模言語モデル(MLLM)が「継続」か「切り替え」かを判断することで、人間のように自然な同時双方向(全二重)対話を実現する新しいフレームワークを提案しました。
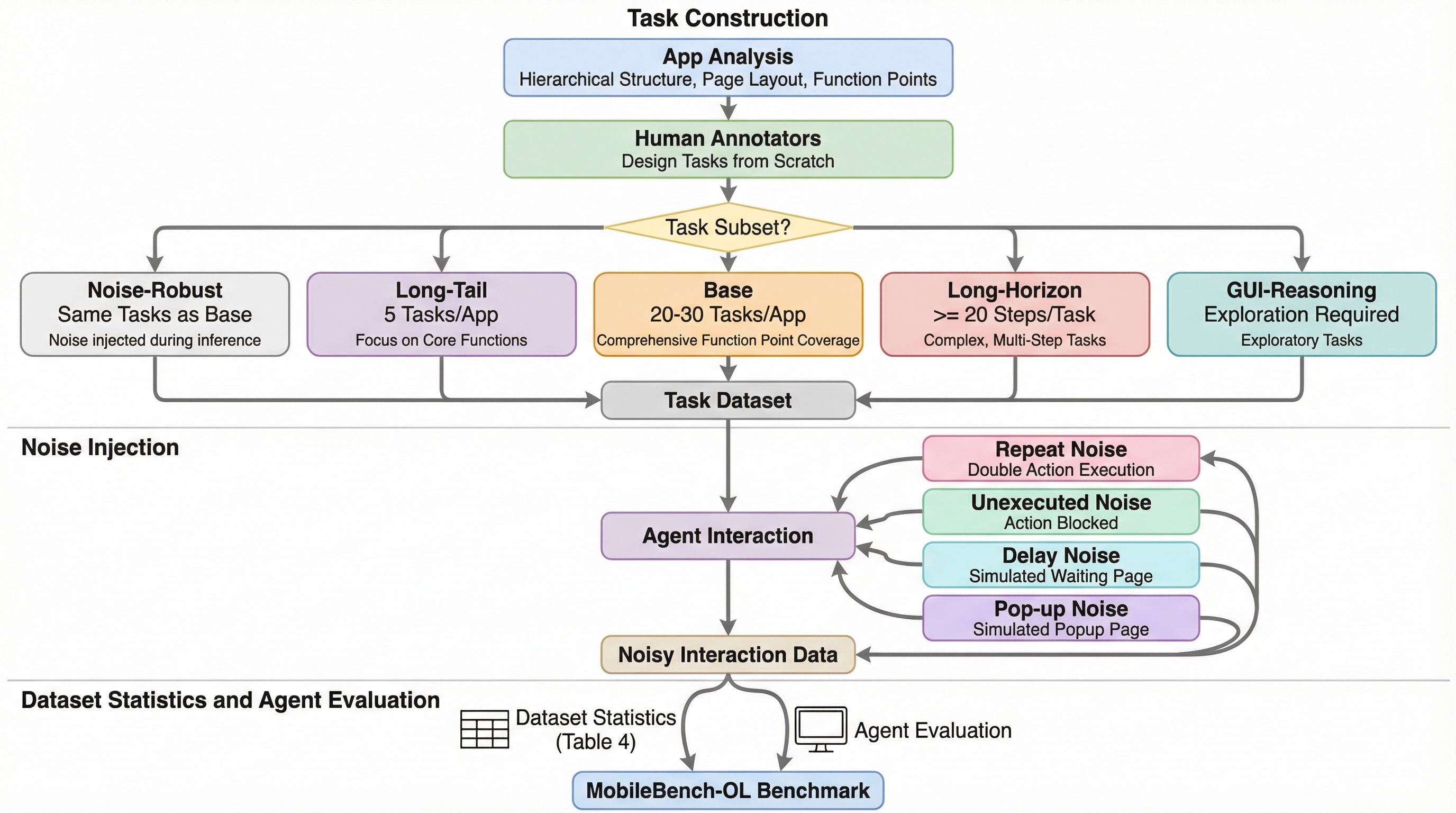
MobileBench-OLは、80個の中国語アプリから抽出された1080個のタスクで構成される、実環境におけるモバイルGUIエージェント評価のための包括的なオンラインベンチマークである。従来のベンチマークが単純な指示への追従に偏っていたのに対し、本手法は複雑な推論や自律的な探索能力、そして実環境特有のランダムなノイズへの対応力を多角的に測定する。 本ベンチマークは、20ステップ以上の長期タスクや隠れた機能の探索、ポップアップやネットワーク遅延といった4種類のノイズを含む5つのサブセットを提供し、エージェントの堅牢性を厳格に評価する。また、デバイスの状態を初期化するリセット機構を備えた自動評価フレームワークを導入することで、実機を用いた安定かつ再現可能な検証プロセスを確立している。 12種類の主要なGUIエージェントを用いた実験の結果、現在のモデルは実世界の複雑な要求に対して依然として大きな改善の余地があることが明らかになり、人間による評価でも本指標の信頼性が確認された。このデータセットは、学術的な評価と実世界でのデプロイメントの間に存在するギャップを埋め、次世代のモバイルエージェント開発を促進する基盤となる。
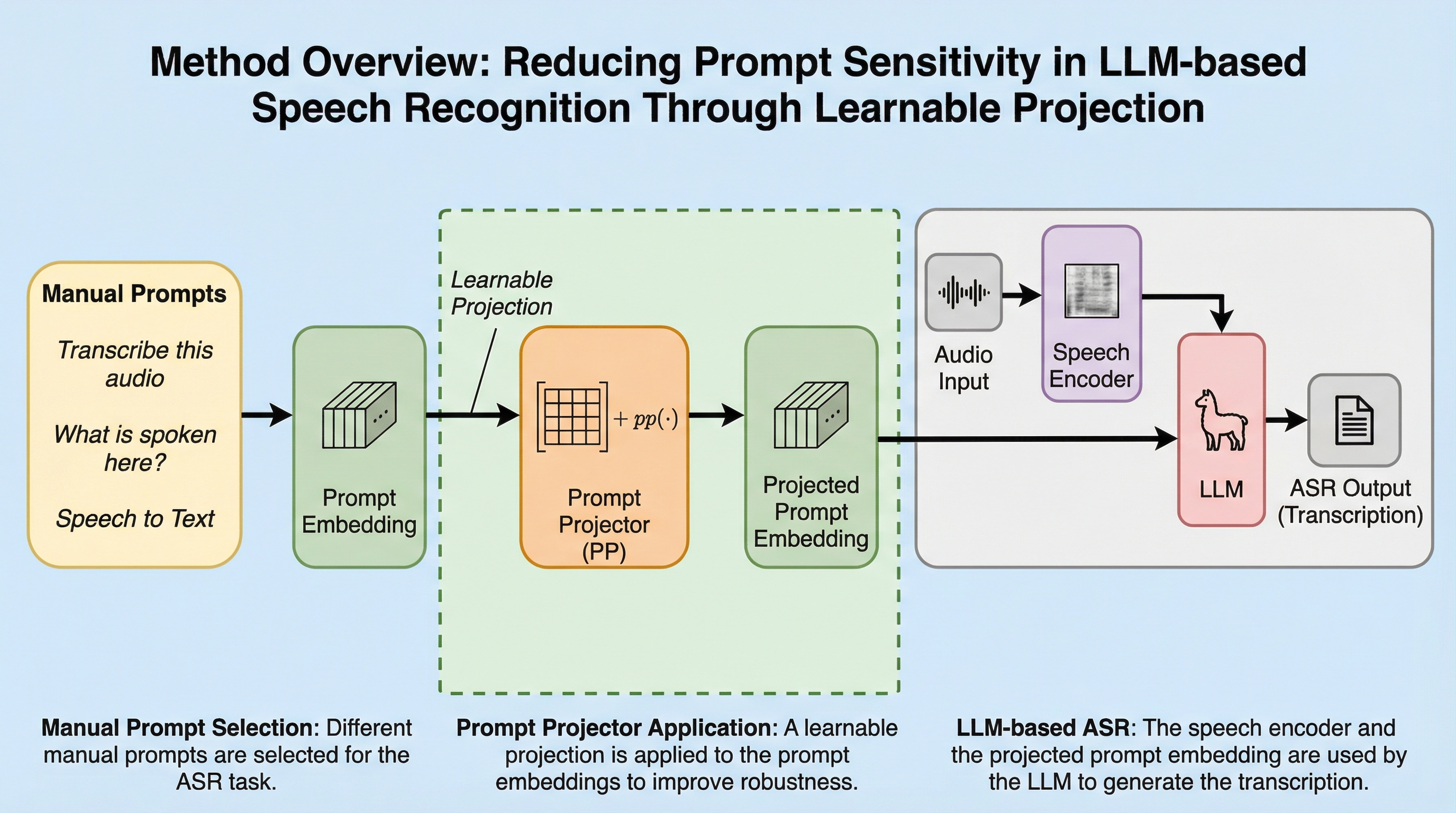
大規模言語モデル(LLM)を用いた音声認識(ASR)において、人間が手動で設計する固定プロンプトの文言や配置が、単語誤り率(WER)などの性能に極めて大きな影響を与え、データセットごとに最適解が異なるという深刻な不安定性を引き起こしていることが本研究の体系的な調査によって明らかになりました。
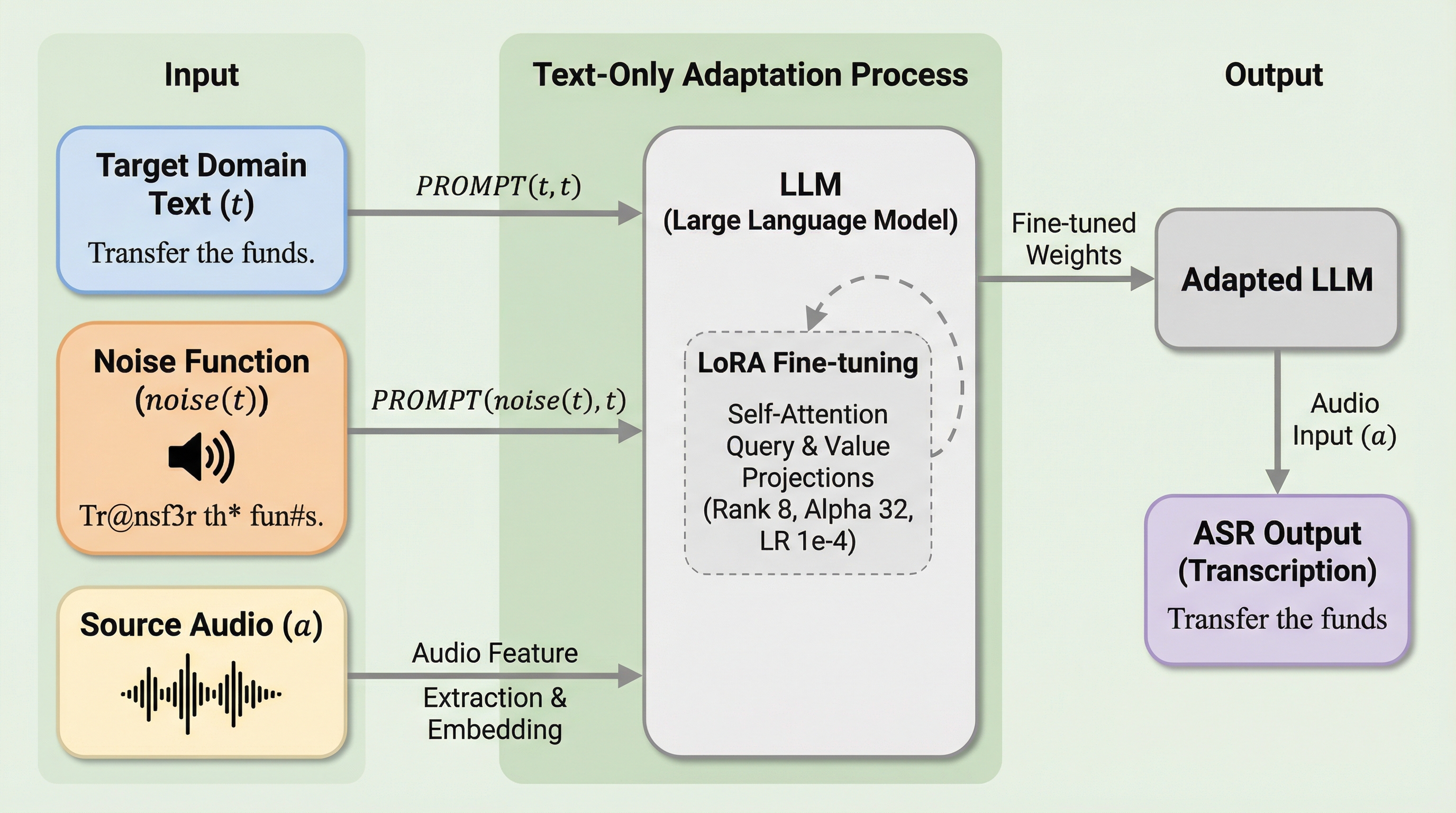
大規模言語モデル(LLM)を活用した音声認識システム(ASR)において、音声とテキストが対になっていないテキストのみのデータを用いて新しいドメインに適応させることは、音声とテキストの整合性を維持する観点から困難な課題であった。
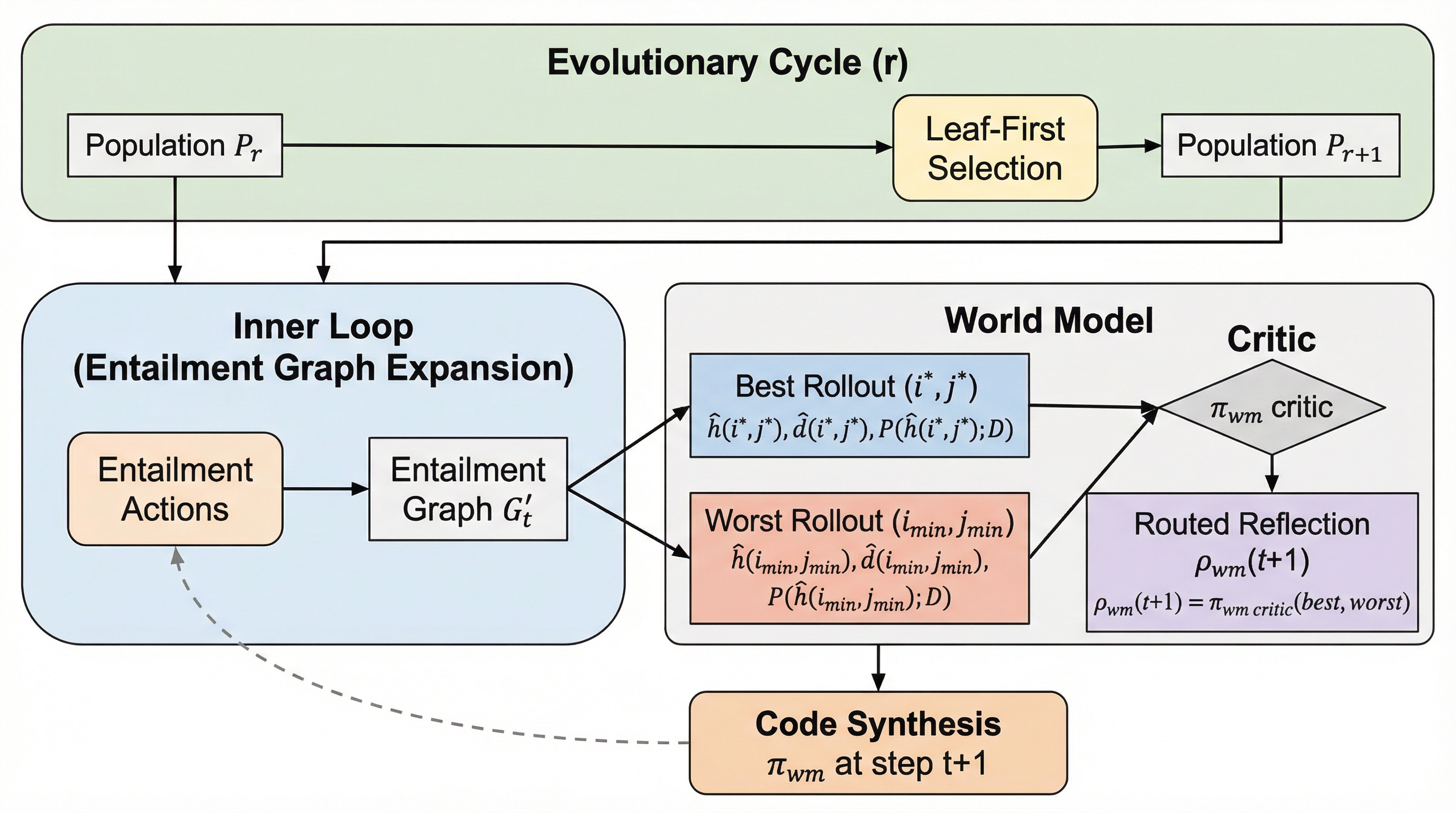
組合せ最適化問題の解決に不可欠なヒューリスティック設計を自動化する手法として、大規模言語モデル(LLM)を用いた自動ヒューリスティック設計(AHD)が注目されていますが、既存手法は固定ルールや静的プロンプトに依存し、探索履歴を十分に活用できないという課題がありました。
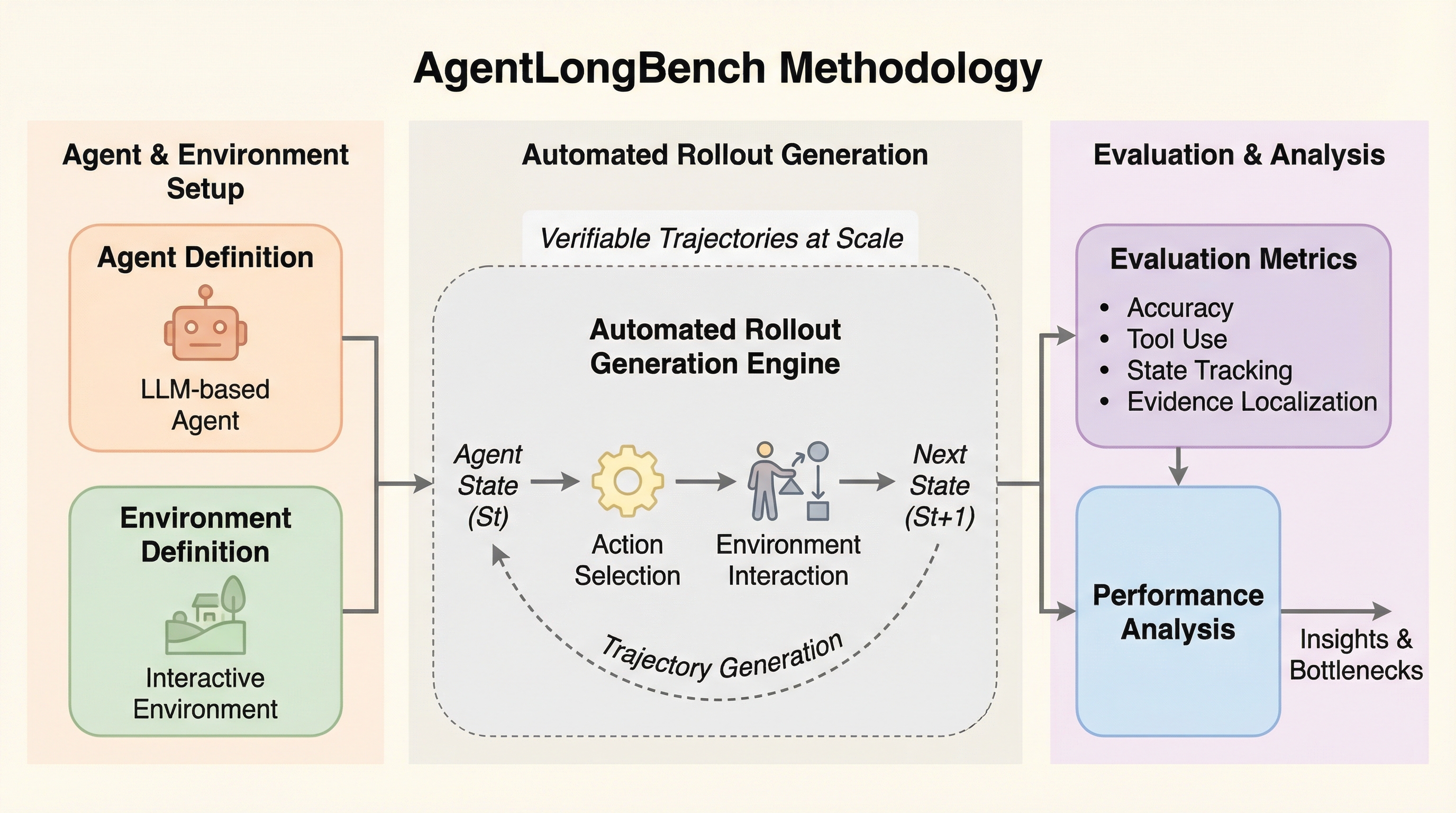
大規模言語モデルが自律型エージェントへと進化する中で、動的で膨大なコンテキストの管理が不可欠となっていますが、従来のベンチマークは静的な検索タスクに偏っており、エージェントと環境の複雑な相互作用をシミュレートできていないという課題がありました。
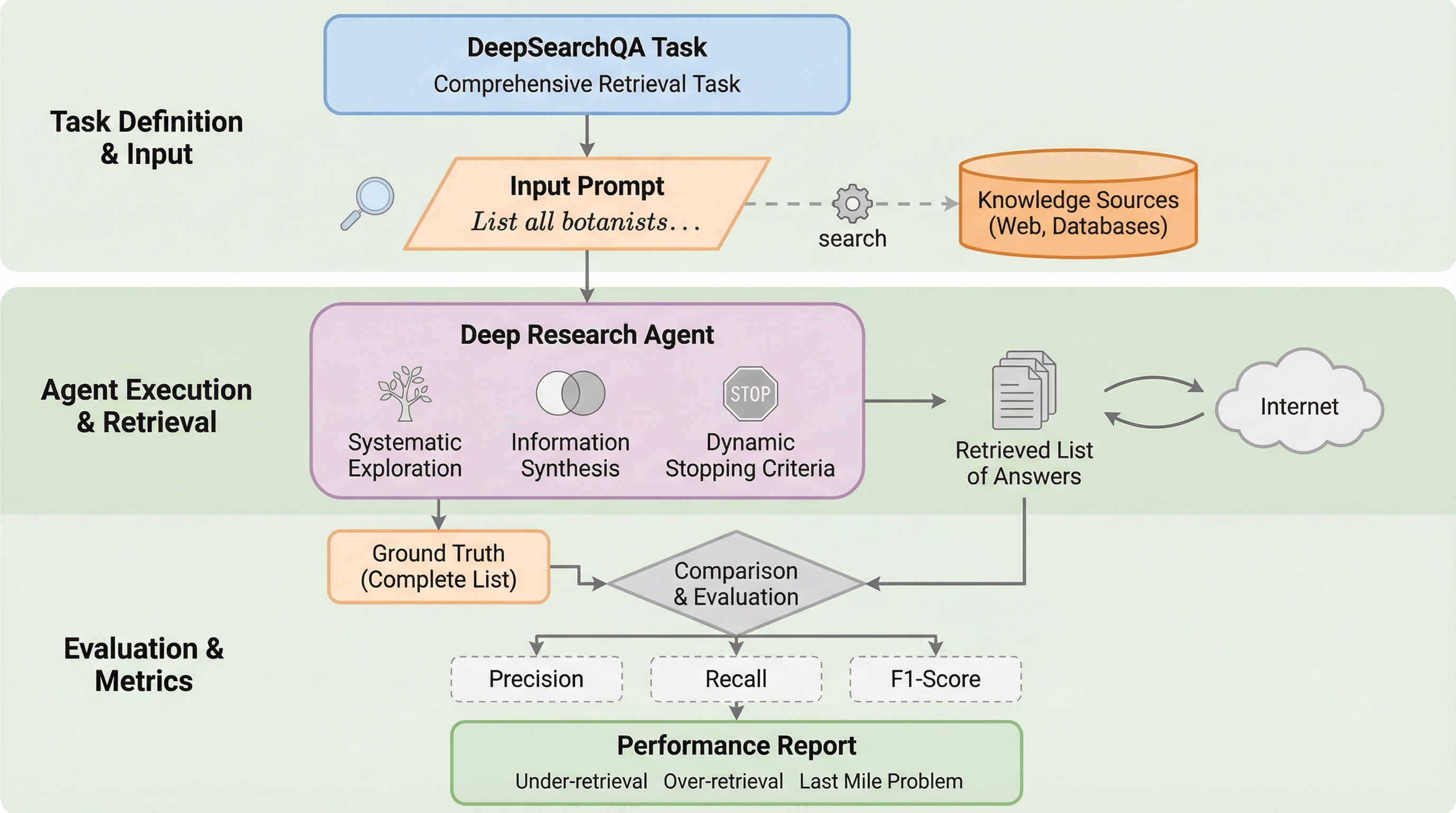
DeepSearchQAは、AIエージェントが複雑な多段階の調査を行い、考えられるすべての正解を漏れなくリストアップする「網羅性」を評価するための新しいベンチマークである。従来の評価手法が単一の事実回答(適合率)に偏っていたのに対し、本手法は17分野にわたる900の難解なプロンプトを通じて、情報の体系的な収集、重複排除、探索の終了判断という3つの高度な能力を厳格に測定する。検証の結果、最新のAIモデルでも高い再現率と適合率の両立に苦戦しており、探索の早期打ち切りや、自信のない回答を並べて網羅性を偽装する「ヘッジ行動」といった特有の失敗パターンが明らかになった。これにより、次世代のリサーチエージェントが克服すべき具体的な課題が浮き彫りとなり、より堅牢な自律型システムの開発に向けた重要な診断ツールとして機能する。
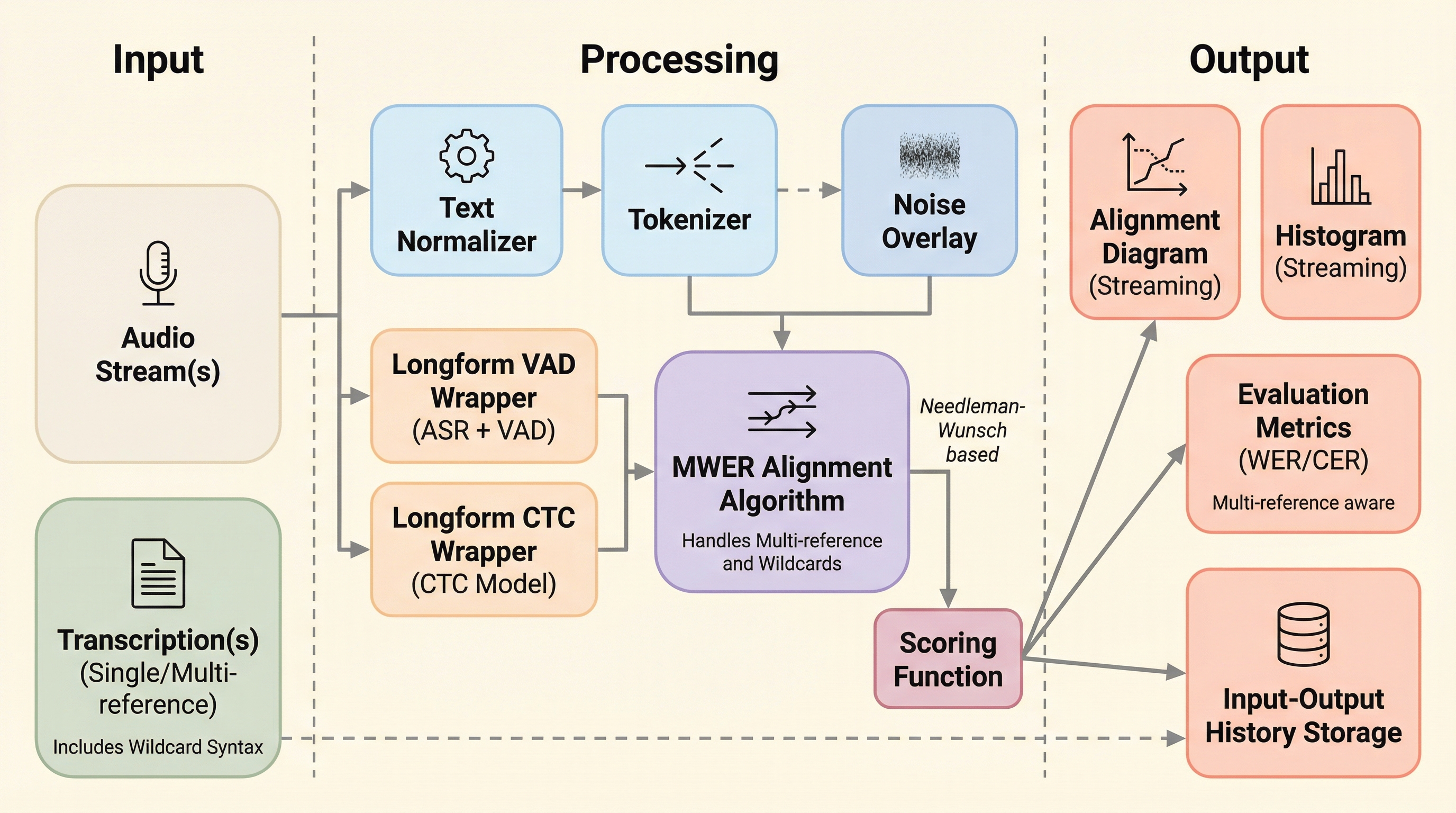
音声認識(ASR)の評価において、表記揺れや聞き取り困難な箇所を柔軟に扱うための新アルゴリズム「MWER」と、包括的な評価ライブラリ「asr_eval」が提案されました。 MWERは、複数の正解候補を波括弧で記述するマルチリファレンス構文、任意の挿入を許容するワイルドカード、ハルシネーションによる指標の歪みを抑える緩和ペナルティを導入し、より人間に近い評価を実現します。 ロシア語の長尺データセットを用いた検証では、従来のテキスト正規化に頼る評価が、モデルが特定の表記規則に過剰適合することで生じる「指標の錯覚」を引き起こし、真の性能向上を誤認させるリスクがあることが示されました。
ウルドゥー語における大規模言語モデルの複雑な推論能力を厳密に評価するため、複数の翻訳システムと人間による検証を組み合わせた高品質なベンチマーク「UrduBench」が構築されました。算術、記号数学、常識、科学的知識を網羅する4つの主要な英語データセットを、文脈の整合性を維持しながらウルドゥー語へ移植することで、従来の機械翻訳手法で課題となっていた意味の断片化や論理的矛盾を解消しています。 評価の結果、思考の連鎖(Chain-of-Thought)プロンプトの導入と言語的一貫性の維持が推論の成功に不可欠であることが示され、モデルの規模以上に多言語学習の質や命令チューニングの精度が重要であることが明らかになりました。本研究は、低リソース言語における標準的な評価手法を提示するだけでなく、他の言語にも応用可能な高品質なデータセット構築のガイドラインを提供しています。 算術推論を測定するMGSM、記号数学を扱うMATH-500、常識的な推論を評価するCommonSenseQA、そして事実知識に基づく科学的推論を問うOpenBookQAという、世界的に広く利用されている4つの英語データセットをウルドゥー語に移植しました。これにより、低リソース言語の評価において最大の障壁となっていた翻訳エラーによるノイズを最小限に抑え、モデルが持つ純粋な推論能力を抽出することが可能になりました。