UrduBench:ヒューマン・イン・ザ・ループによる文脈的アンサンブル翻訳を用いたウルドゥー語推論ベンチマーク
ウルドゥー語における大規模言語モデルの複雑な推論能力を厳密に評価するため、複数の翻訳システムと人間による検証を組み合わせた高品質なベンチマーク「UrduBench」が構築されました。算術、記号数学、常識、科学的知識を網羅する4つの主要な英語データセットを、文脈の整合性を維持しながらウルドゥー語へ移植することで、従来の機械翻訳手法で課題となっていた意味の断片化や論理的矛盾を解消しています。 評価の結果、思考の連鎖(Chain-of-Thought)プロンプトの導入と言語的一貫性の維持が推論の成功に不可欠であることが示され、モデルの規模以上に多言語学習の質や命令チューニングの精度が重要であることが明らかになりました。本研究は、低リソース言語における標準的な評価手法を提示するだけでなく、他の言語にも応用可能な高品質なデータセット構築のガイドラインを提供しています。 算術推論を測定するMGSM、記号数学を扱うMATH-500、常識的な推論を評価するCommonSenseQA、そして事実知識に基づく科学的推論を問うOpenBookQAという、世界的に広く利用されている4つの英語データセットをウルドゥー語に移植しました。これにより、低リソース言語の評価において最大の障壁となっていた翻訳エラーによるノイズを最小限に抑え、モデルが持つ純粋な推論能力を抽出することが可能になりました。
TL;DR(結論)
ウルドゥー語における大規模言語モデルの複雑な推論能力を厳密に評価するため、複数の翻訳システムと人間による検証を組み合わせた高品質なベンチマーク「UrduBench」が構築されました。算術、記号数学、常識、科学的知識を網羅する4つの主要な英語データセットを、文脈の整合性を維持しながらウルドゥー語へ移植することで、従来の機械翻訳手法で課題となっていた意味の断片化や論理的矛盾を解消しています。 評価の結果、思考の連鎖(Chain-of-Thought)プロンプトの導入と言語的一貫性の維持が推論の成功に不可欠であることが示され、モデルの規模以上に多言語学習の質や命令チューニングの精度が重要であることが明らかになりました。本研究は、低リソース言語における標準的な評価手法を提示するだけでなく、他の言語にも応用可能な高品質なデータセット構築のガイドラインを提供しています。 算術推論を測定するMGSM、記号数学を扱うMATH-500、常識的な推論を評価するCommonSenseQA、そして事実知識に基づく科学的推論を問うOpenBookQAという、世界的に広く利用されている4つの英語データセットをウルドゥー語に移植しました。これにより、低リソース言語の評価において最大の障壁となっていた翻訳エラーによるノイズを最小限に抑え、モデルが持つ純粋な推論能力を抽出することが可能になりました。
なぜこの問題か
大規模言語モデル(LLM)は、英語などの高リソース言語において驚異的な推論能力を示していますが、ウルドゥー語のような低リソース言語においては、その真の能力を測定するための標準化された評価基盤が著しく不足しています。これまでのウルドゥー語に関する評価は、感情分析、基本的な文書分類、あるいは単純な抽出型の質問回答といった一般的な自然言語処理タスクに限定されており、数学的な問題解決や多段階の論理的推論、複雑な常識判断を必要とする高度な知能を評価する仕組みが整っていませんでした。また、既存の英語ベンチマークを機械翻訳によって他言語化する試みは行われてきましたが、ウルドゥー語のような言語では翻訳の精度や感度が評価結果を大きく歪めてしまうという深刻な課題があります。 特に多肢選択式の問題において、質問文と選択肢を個別に翻訳すると、文脈が断片化し、文法的な不整合や意味の乖離が生じやすくなります。その結果、モデルが本来持っている推論能力ではなく、翻訳の不備によるノイズを測定してしまうリスクが指摘されてきました。…
核心:何を提案したのか
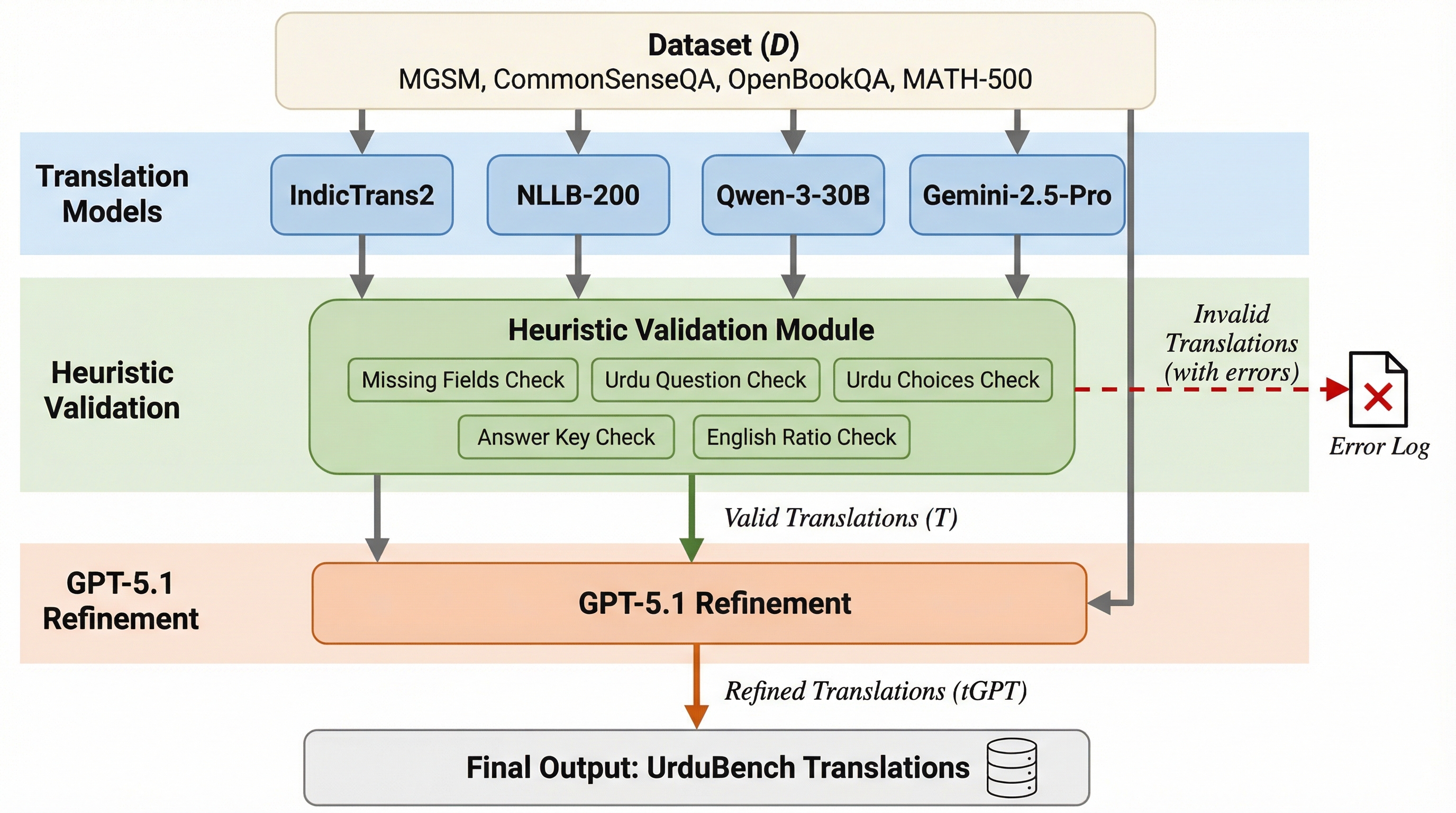
本研究では、ウルドゥー語の推論能力を包括的に評価するための新しいベンチマーク「UrduBench」と、それを構築するための「ヒューマン・イン・ザ・ループ(人間による検証)」を取り入れた文脈的アンサンブル翻訳フレームワークを提案しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related