学習可能なプロジェクションによるLLMベースの音声認識におけるプロンプト感度の低減
大規模言語モデル(LLM)を用いた音声認識(ASR)において、人間が手動で設計する固定プロンプトの文言や配置が、単語誤り率(WER)などの性能に極めて大きな影響を与え、データセットごとに最適解が異なるという深刻な不安定性を引き起こしていることが本研究の体系的な調査によって明らかになりました。
TL;DR(結論)
大規模言語モデル(LLM)を用いた音声認識(ASR)において、人間が手動で設計する固定プロンプトの文言や配置が、単語誤り率(WER)などの性能に極めて大きな影響を与え、データセットごとに最適解が異なるという深刻な不安定性を引き起こしていることが本研究の体系的な調査によって明らかになりました。 この課題を解決するために、音声信号をLLMの入力空間にマッピングする手法から着想を得て、プロンプトの埋め込みをLLMがより効果的に処理できる領域へと変換する軽量な学習可能モジュール「プロンプト・プロジェクター」を提案し、既存のモデル構成を一切変更することなく、プロンプトの選択に対する感度を大幅に低減することに成功しました。 4つの多様なデータセットを用いた広範な検証の結果、提案手法はプロンプトの差異による性能のばらつきを劇的に抑えるだけでなく、人間が試行錯誤して選んだ最良のプロンプトを使用した場合の精度を一貫して上回り、さらにLoRAなどの追加の微調整手法とも高い相乗効果を発揮してシステムの堅牢性を飛躍的に向上させることが証明されました。
なぜこの問題か
音声基礎モデルと大規模言語モデル(LLM)を接続するLLMベースの音声認識システムは、従来の音声認識の枠を超えた高い性能を示すアプローチとして急速に普及しています。一般的にこれらのシステムでは、学習時と推論時の両方において、人間が手動で定義した「Transcribe speech to text.」のような固定のテキストプロンプトを使用する設計が標準的に採用されてきました。この設計は、多様な実用シナリオへの適用を可能にし、モデルの性能を最大限に引き出すためのガイドとして機能すると考えられてきましたが、実際にはプロンプトのデザインが音声認識の精度にどのような影響を与えるかについては、これまで体系的な調査が行われてきませんでした。本論文では、複数のデータセットを用いて一般的に使用されるプロンプトを包括的に分析した結果、プロンプトの選択が音声認識の性能に極めて大きな影響を及ぼし、システムに深刻な不安定性をもたらしている現状を明らかにしました。…
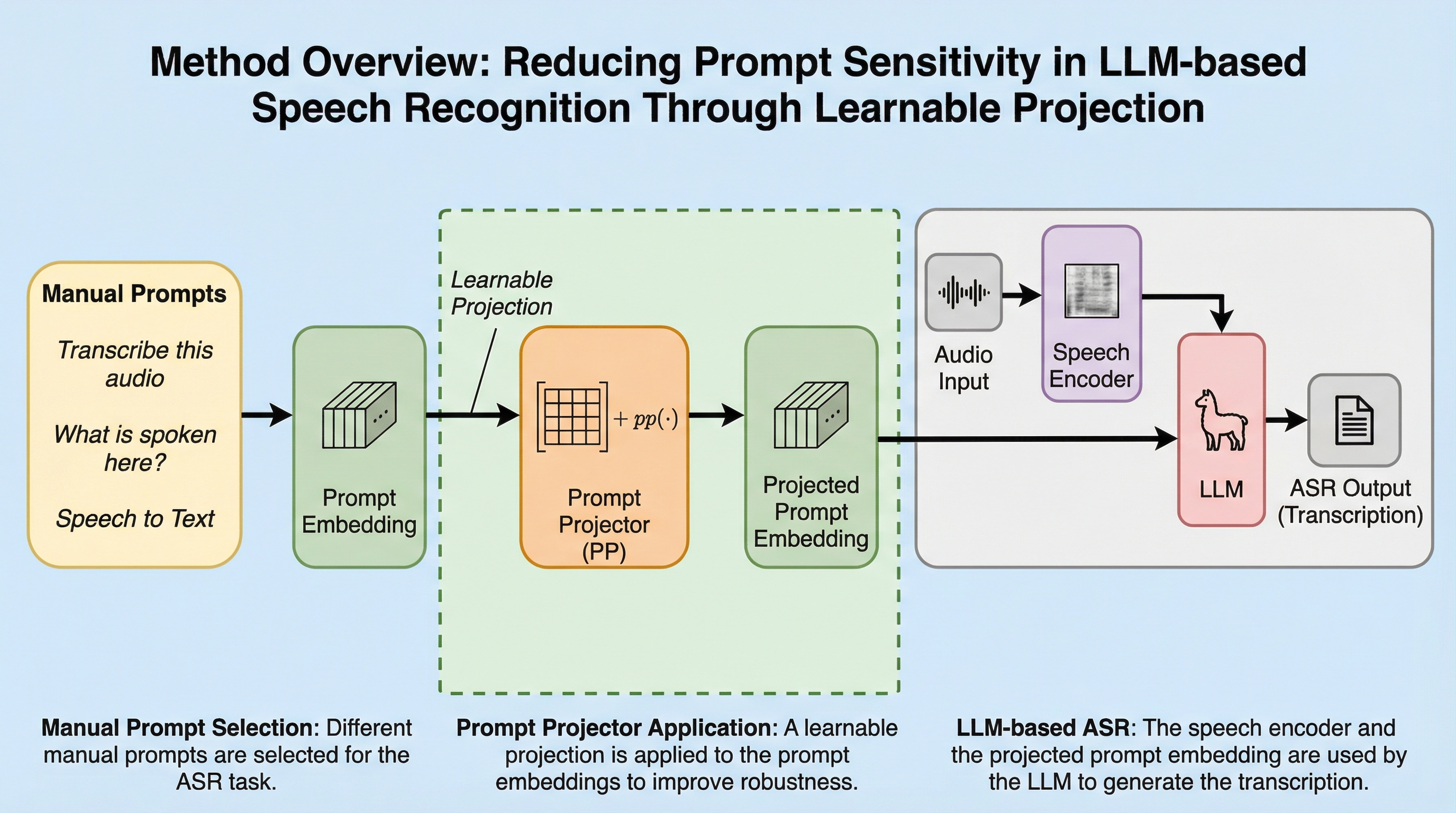
核心:何を提案したのか
本研究では、プロンプトの選択に対する感度を低減し、音声認識の精度を安定させるための画期的な解決策として、「プロンプト・プロジェクター(Prompt Projector)」という新しいモジュールを提案しています。このモジュールは、音声信号をLLMの入力空間にマッピングする「音声プロジェクター」の成功から着想を得て設計された、シンプルかつモデルに依存しない拡張機能です。プロンプト・プロジェクターの主な役割は、元のプロンプトの埋め込みベクトルを、LLMが内部的に最も効果的に処理できる入力空間内の特定の領域へと投影することにあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related