DeepSearchQA: 深層リサーチエージェントのための網羅性評価ベンチマーク
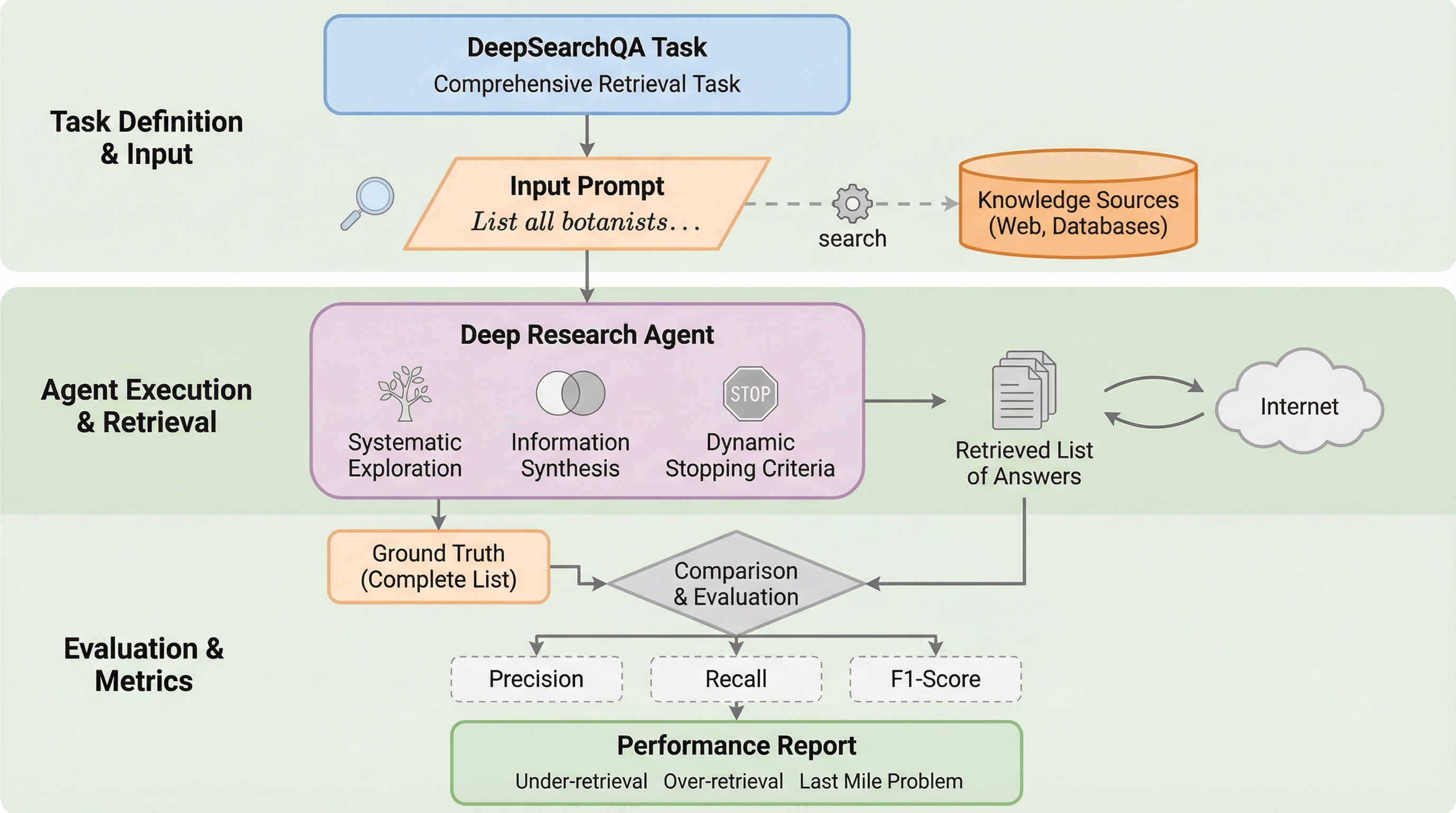
DeepSearchQAは、AIエージェントが複雑な多段階の調査を行い、考えられるすべての正解を漏れなくリストアップする「網羅性」を評価するための新しいベンチマークである。従来の評価手法が単一の事実回答(適合率)に偏っていたのに対し、本手法は17分野にわたる900の難解なプロンプトを通じて、情報の体系的な収集、重複排除、探索の終了判断という3つの高度な能力を厳格に測定する。検証の結果、最新のAIモデルでも高い再現率と適合率の両立に苦戦しており、探索の早期打ち切りや、自信のない回答を並べて網羅性を偽装する「ヘッジ行動」といった特有の失敗パターンが明らかになった。これにより、次世代のリサーチエージェントが克服すべき具体的な課題が浮き彫りとなり、より堅牢な自律型システムの開発に向けた重要な診断ツールとして機能する。
TL;DR(結論)
DeepSearchQAは、AIエージェントが複雑な多段階の調査を行い、考えられるすべての正解を漏れなくリストアップする「網羅性」を評価するための新しいベンチマークである。従来の評価手法が単一の事実回答(適合率)に偏っていたのに対し、本手法は17分野にわたる900の難解なプロンプトを通じて、情報の体系的な収集、重複排除、探索の終了判断という3つの高度な能力を厳格に測定する。検証の結果、最新のAIモデルでも高い再現率と適合率の両立に苦戦しており、探索の早期打ち切りや、自信のない回答を並べて網羅性を偽装する「ヘッジ行動」といった特有の失敗パターンが明らかになった。これにより、次世代のリサーチエージェントが克服すべき具体的な課題が浮き彫りとなり、より堅牢な自律型システムの開発に向けた重要な診断ツールとして機能する。
なぜこの問題か
人工知能の分野は、静的な大規模言語モデル(LLM)から、特定の目標を達成するために動的で複雑な環境と相互作用する自律的なウェブエージェントへとパラダイムシフトを遂げている。この「エージェント革命」においては、計画立案、メモリ管理、ツールの活用といった洗練された能力が不可欠となる。しかし、エージェントの能力開発が急速に進む一方で、その評価手法がボトルネックとなっている。既存のベンチマークの多くは、すでに性能が飽和しているか、現実世界のユーザーニーズを反映するにはあまりに不自然な設計となっている。これまでの評価パラダイムは、主に「単一回答の検証」に依存してきた。例えば、TruthfulQA、HaluEval、SimpleQAといったベンチマークは、事実性や「フランスの首都は何か」といった単一の回答を導き出すタスクにおいて厳格な基準を確立した。この形式は、自動採点のコストを抑え、客観性を確保する上では非常に効果的であった。 しかし、このアプローチは「針の穴を通すような正確さ」を重視するあまり、現実の調査業務で求められる「網羅的な情報の収集」という側面を軽視している。…
核心:何を提案したのか
本論文は、AIエージェントの評価軸を「適合率ベースの検索」から「網羅的な回答セットの生成」へと転換させる新しいベンチマーク、DeepSearchQAを提案している。このベンチマークは、エージェントが自律的にウェブを閲覧し、与えられたクエリに対して検証可能なすべての正解セットを生成する能力をテストするように設計されている。DeepSearchQAは、政治、政府、金融、経済、科学、健康、歴史、地理、メディアなど、17の異なる分野にわたる900のプロンプトで構成されている。これにより、特定のドメインに対する過学習を防ぎ、広範なウェブ構造やコンテンツタイプに対する汎用的な対応能力を測定することが可能となる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related