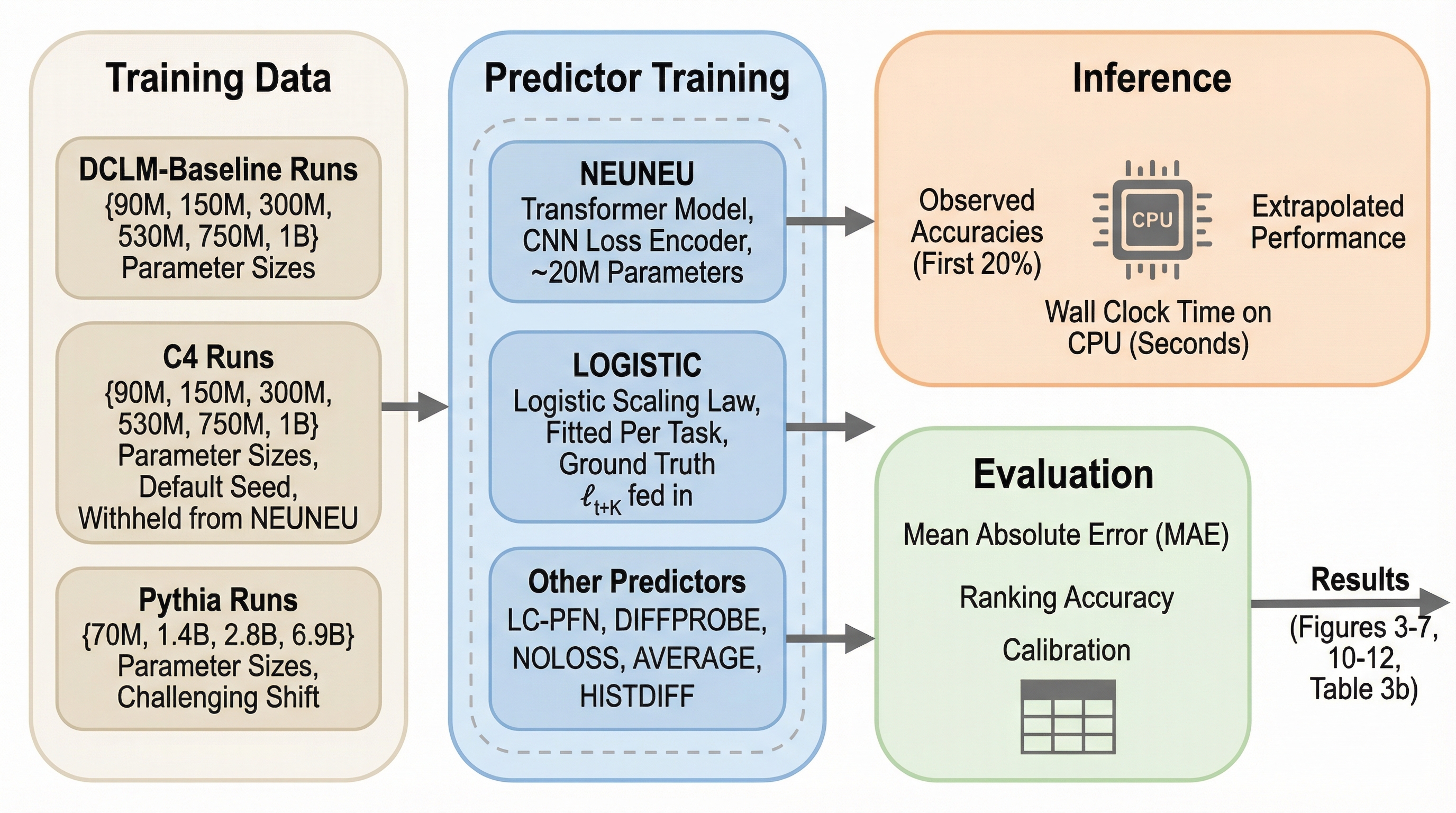
ニューラル・ニューラルスケーリング則
従来のべき乗則やロジスティック関数に基づくスケーリング則は、平均検証損失という単一の指標に依存しており、下流タスクで見られる「逆スケーリング」や「性能の停滞」といった多様な挙動を正確に予測できないという根本的な課題を抱えていました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
従来のべき乗則やロジスティック関数に基づくスケーリング則は、平均検証損失という単一の指標に依存しており、下流タスクで見られる「逆スケーリング」や「性能の停滞」といった多様な挙動を正確に予測できないという根本的な課題を抱えていました。
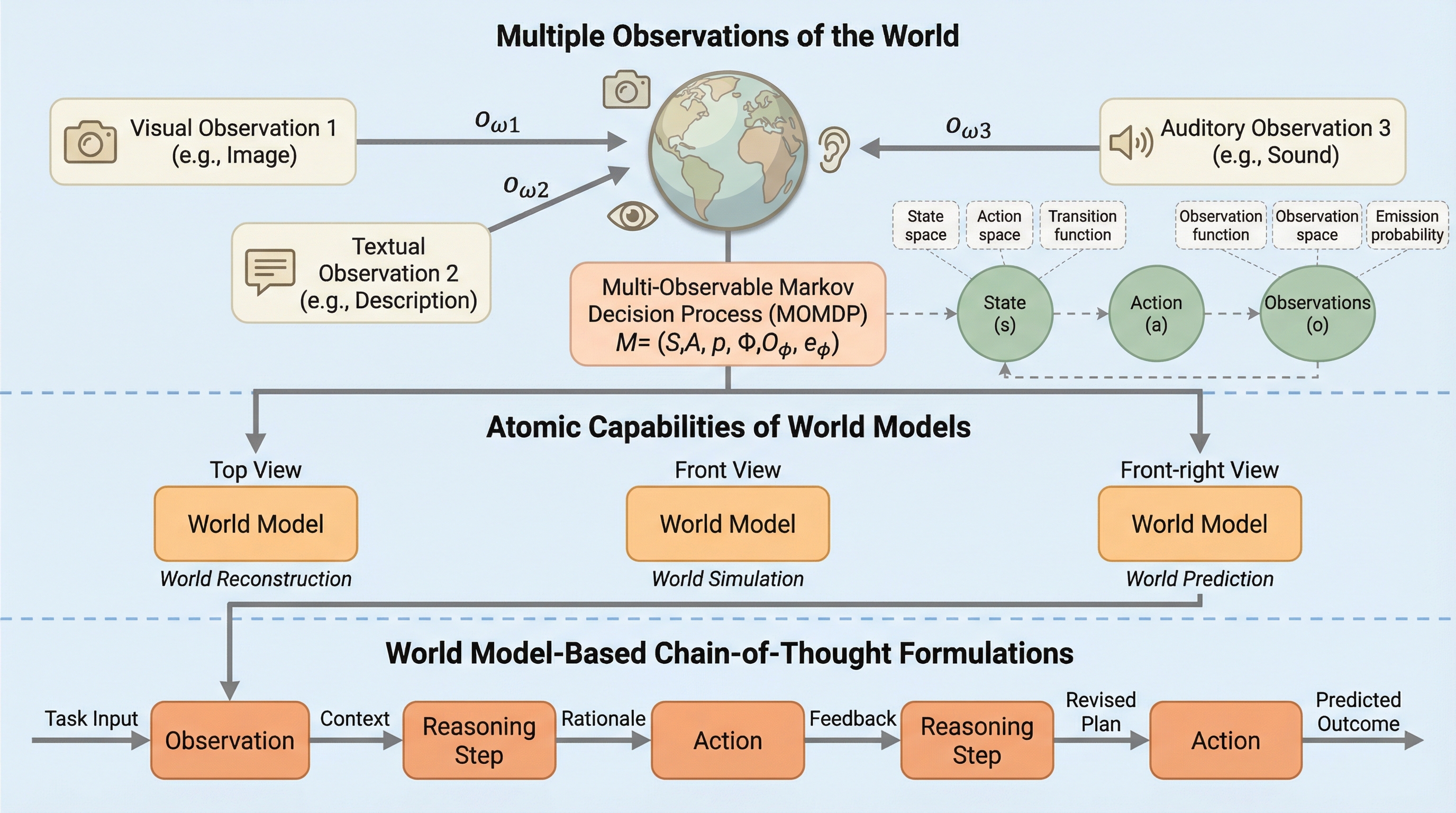
本研究は、統一マルチモーダルモデル(UMM)における視覚生成が、物理的・空間的推論を必要とするタスクにおいて「世界モデル」として機能し、従来の言語のみの推論(CoT)を大幅に上回る性能を発揮することを理論と実験の両面から明らかにしました。
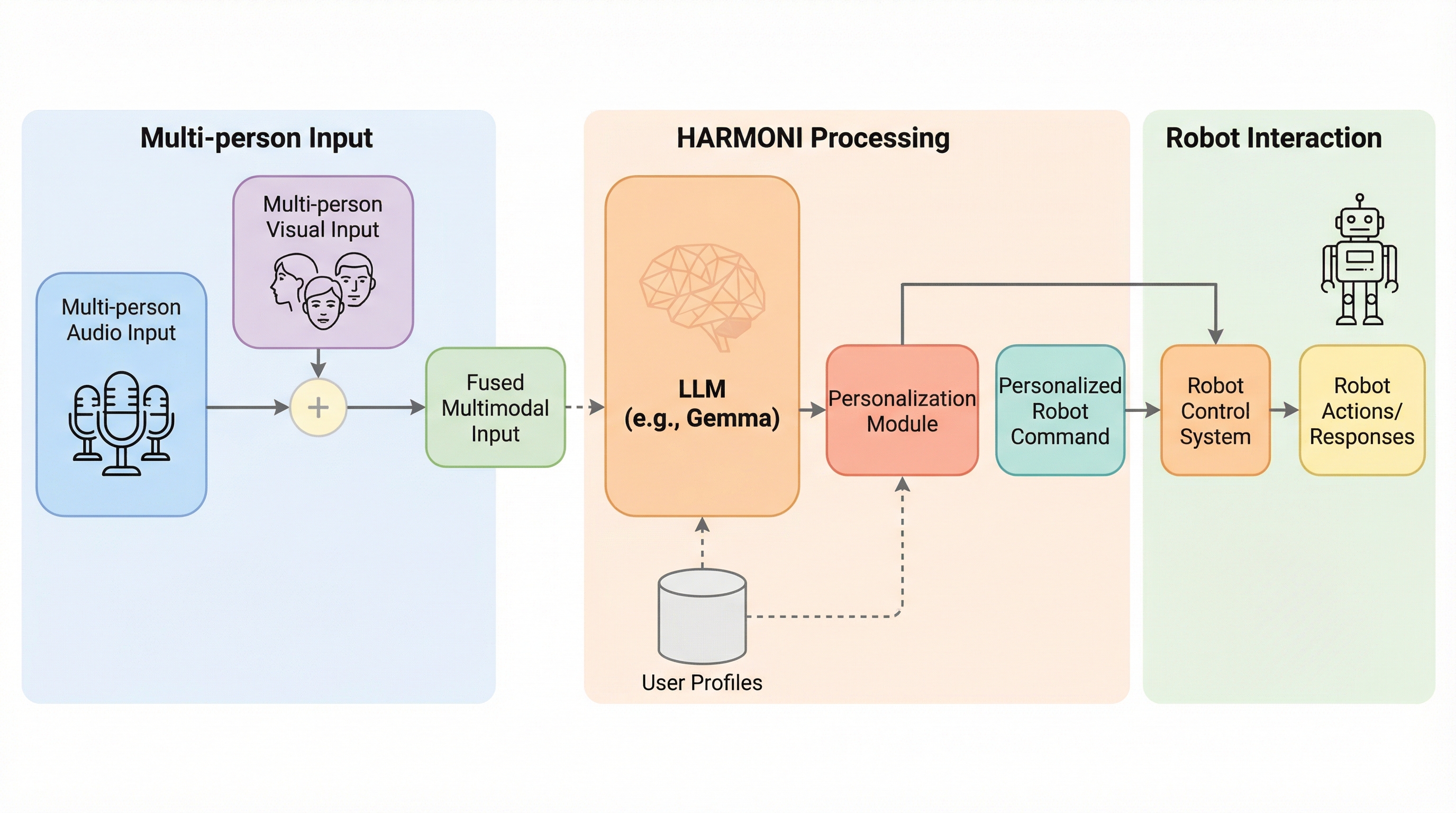
HARMONIは、介護施設のような多人数が同時に存在する複雑な環境において、大規模言語モデル(LLM)の能力を最大限に引き出し、個々のユーザーに対する長期的なパーソナライズを実現するための革新的なマルチモーダル・フレームワークである。
isiZuluやisiXhosaといった低リソース言語の機械翻訳において、限定的な学習データに起因する誤訳や情報の欠落、意味の歪みを解決するため、モデルが自らの出力を批判的に評価し修正する「内省的翻訳(Reflective Translation)」フレームワークが提案されました。 この手法は、GPT-3.
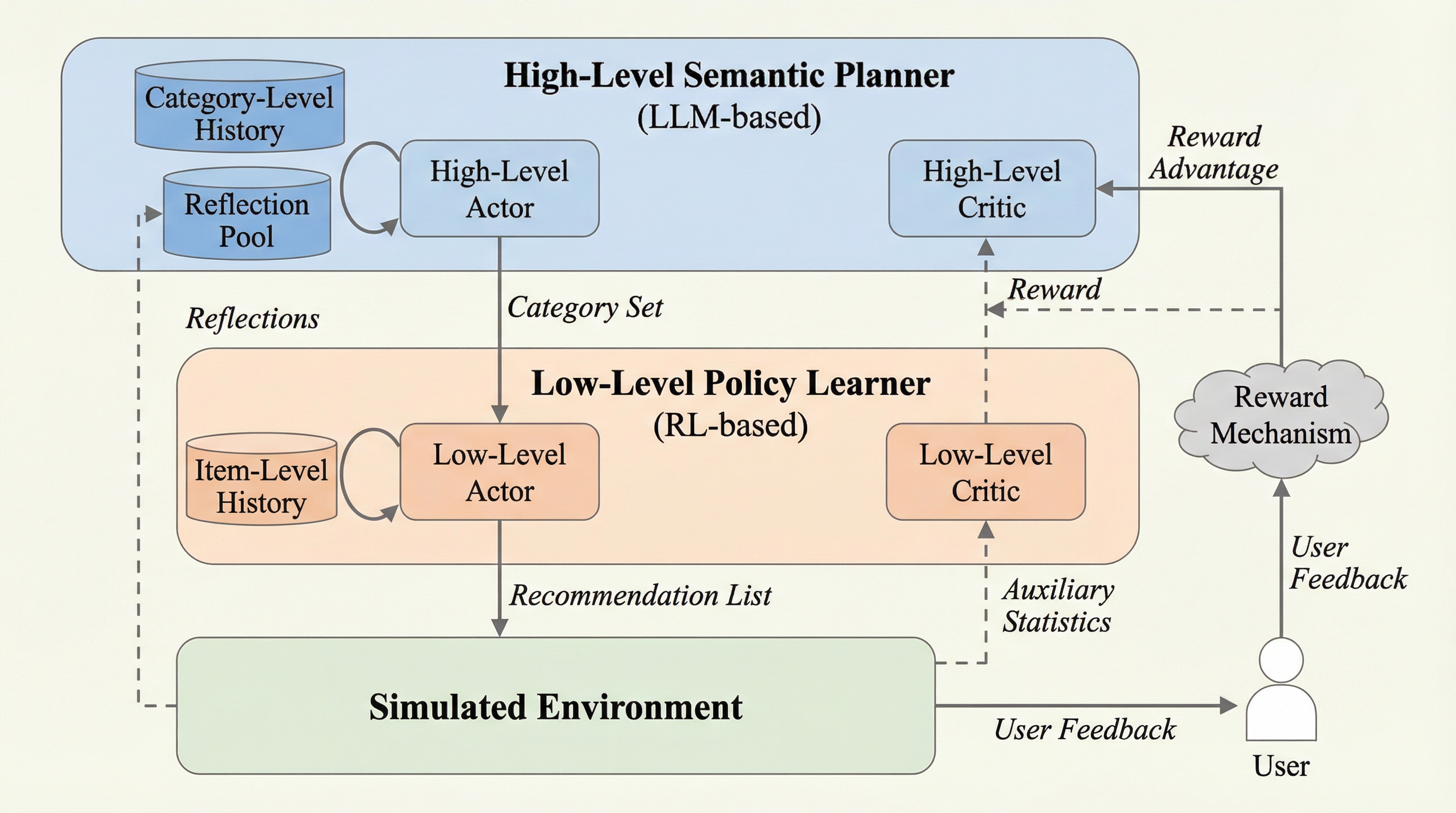
対話型推薦システムが陥りやすいフィルターバブルや内容の均質化という課題に対し、大規模言語モデル(LLM)の論理的計画能力と強化学習(RL)の適応力を組み合わせた階層型フレームワーク「LERL」を開発した。
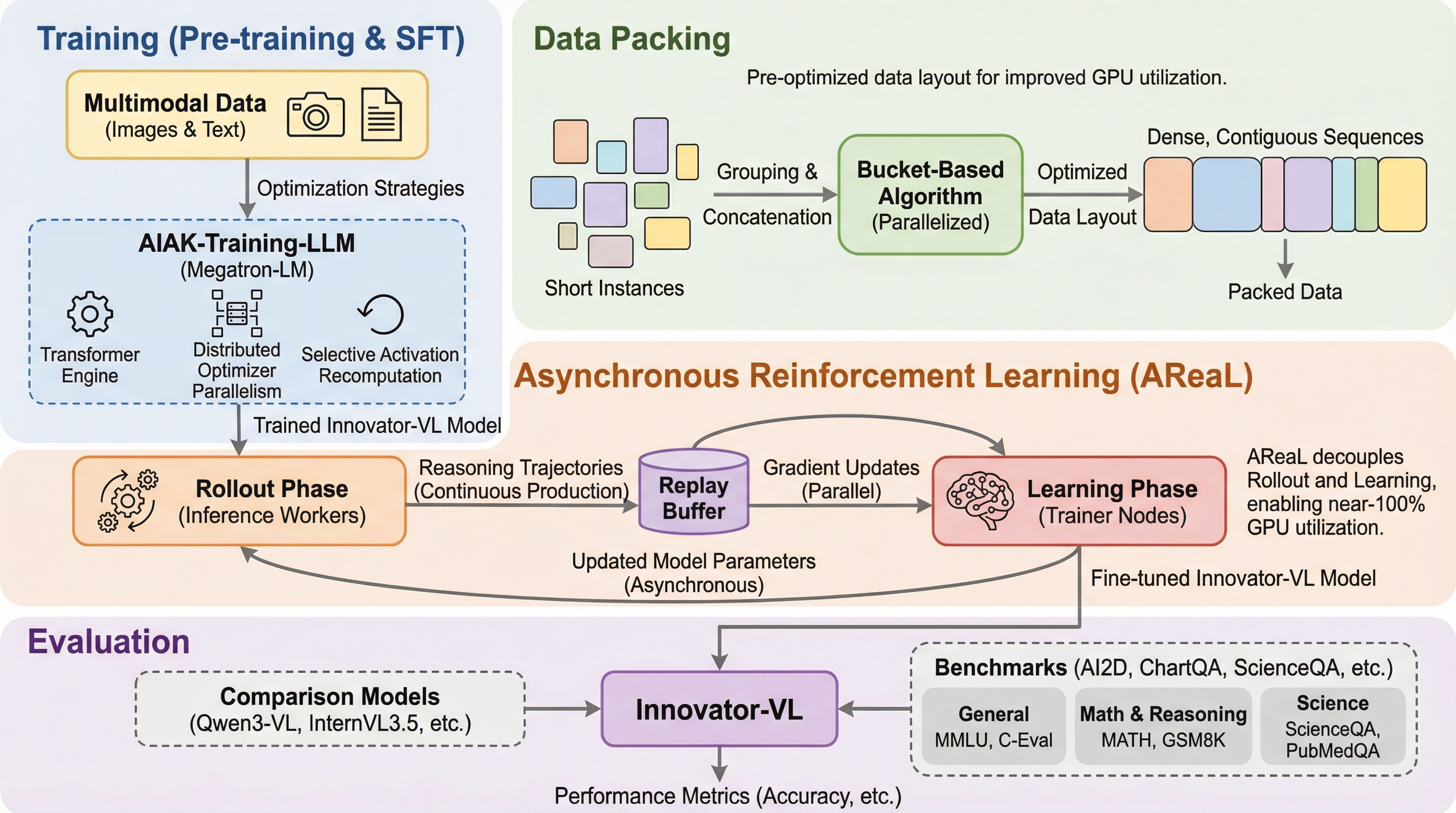
Innovator-VLは、科学的ドメインにおける高度な理解と推論を実現するために開発された、透明性の高いマルチモーダル大規模言語モデル(MLLM)であり、科学的タスクでの卓越した性能と一般的な視覚タスクでの汎用性を高い次元で両立させています。
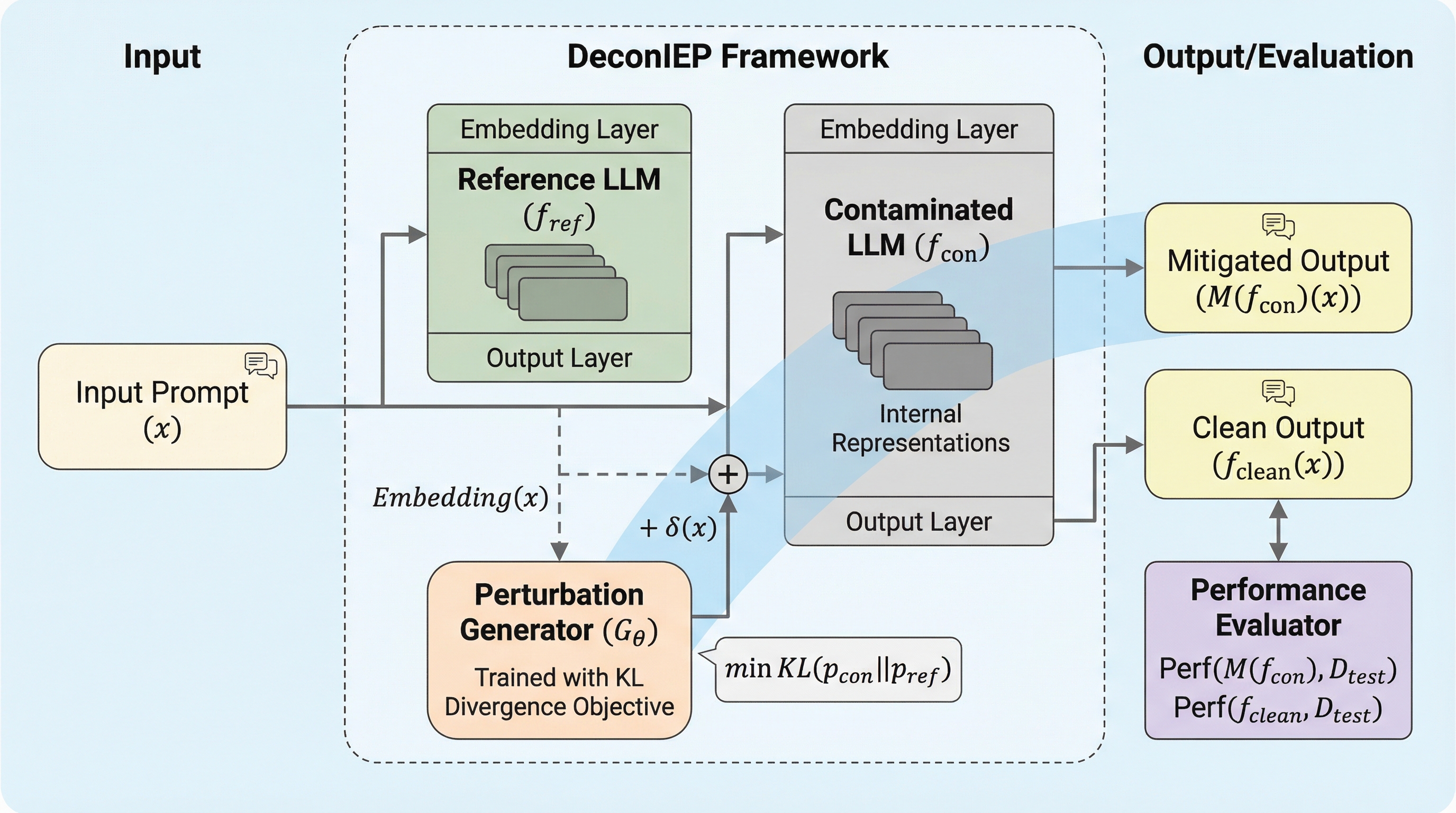
大規模言語モデルの評価において、テストデータが訓練データに混入する「データ汚染」が性能を不当に高く見せる問題に対し、推論時に埋め込み空間へ微小な摂動を加えることで記憶によるショートカットを抑制する手法「DeconIEP」が提案されました。
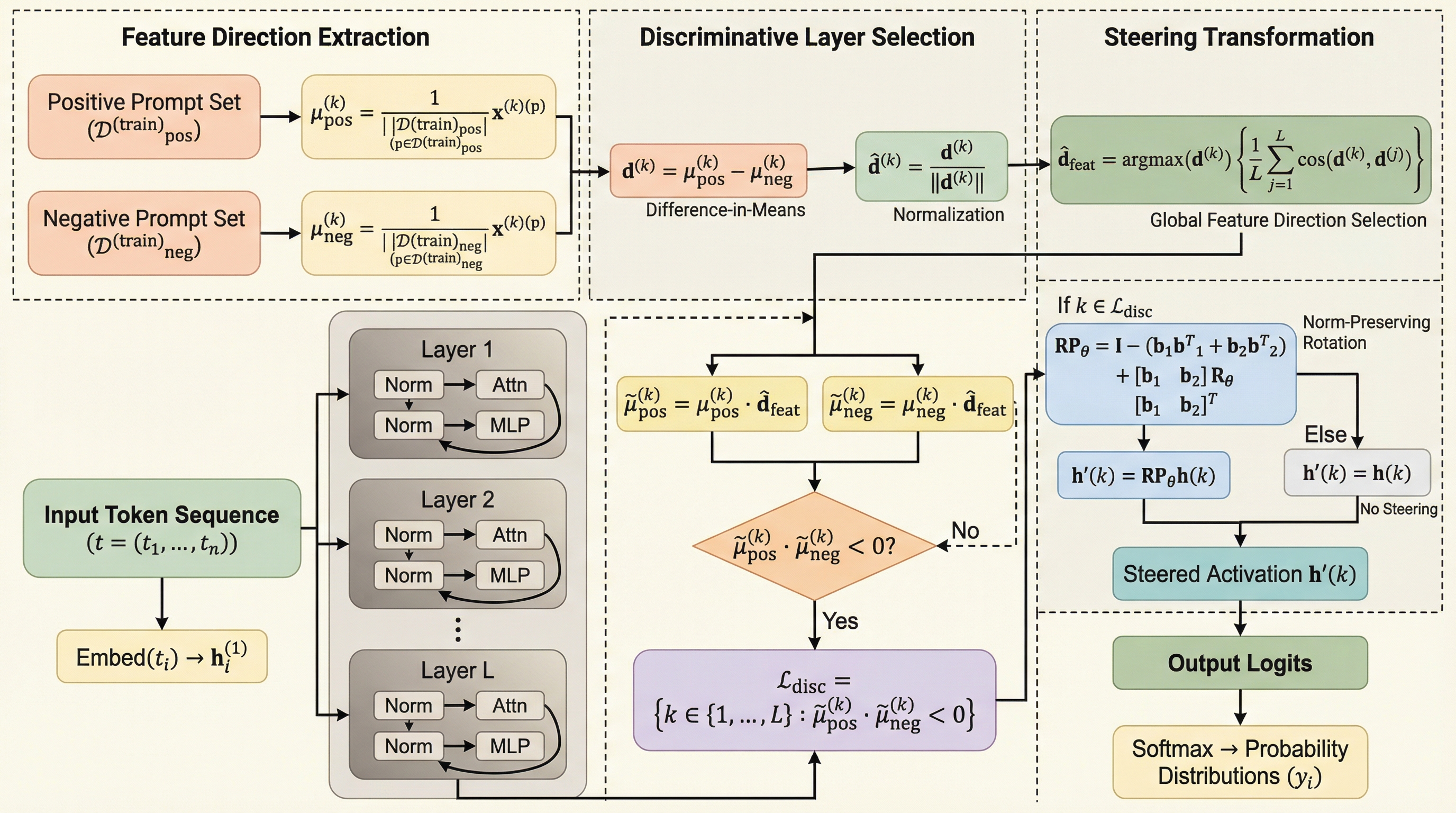
大規模言語モデル(LLM)の安全性を高めるための「アクティベーション・ステアリング」において、従来の回転手法がモデルの内部状態(ノルム)を歪ませ、特に7B未満の小規模モデルで生成崩壊を引き起こす問題を特定しました。
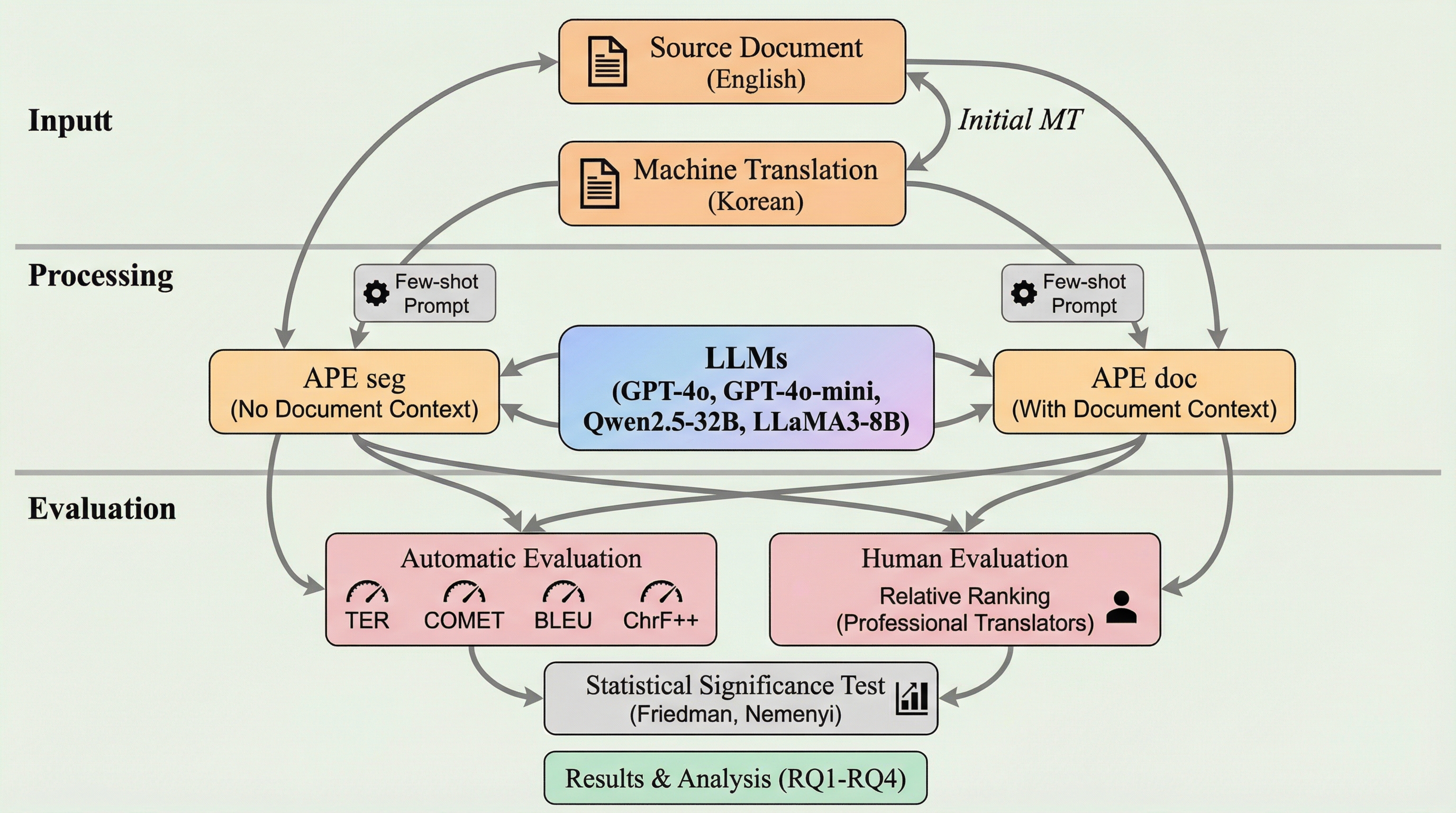
商用大型言語モデル(LLM)は、単純なプロンプト操作のみで人間と同等の自動ポストエディット(APE)品質を達成可能ですが、ドキュメント全体のコンテキストを追加しても翻訳品質に統計的に有意な向上は見られず、長文コンテキストの活用の難しさが浮き彫りになりました。
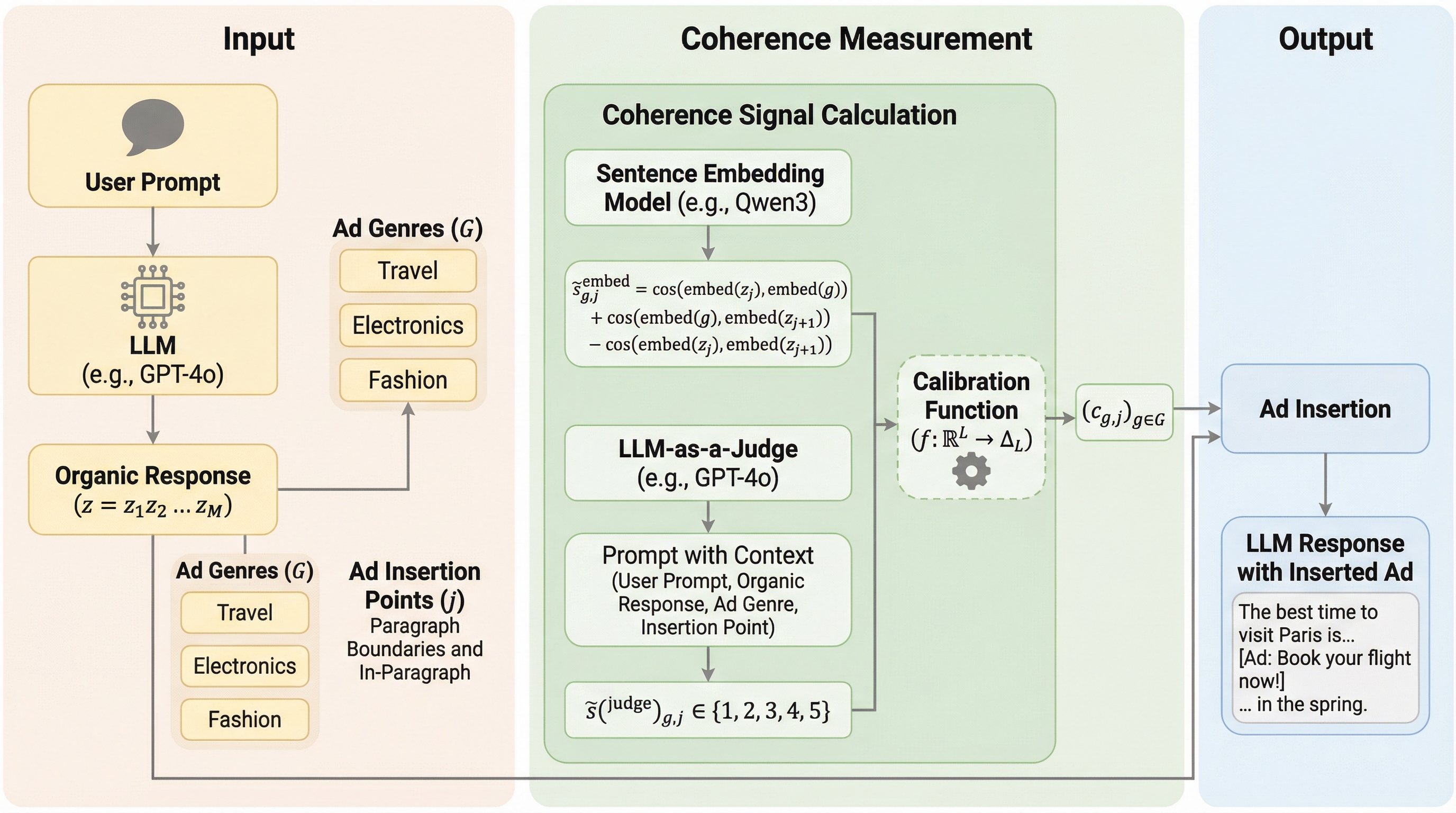
大規模言語モデル(LLM)の持続可能な収益化に向け、広告挿入を応答生成から分離し、広告主が特定のクエリではなく「ジャンル」という抽象的なカテゴリに対して事前に入札を行う新しい広告枠組みを提案する。