選択的ステアリング:識別的な層選択を通じたノルム保存制御
大規模言語モデル(LLM)の安全性を高めるための「アクティベーション・ステアリング」において、従来の回転手法がモデルの内部状態(ノルム)を歪ませ、特に7B未満の小規模モデルで生成崩壊を引き起こす問題を特定しました。
TL;DR(結論)
大規模言語モデル(LLM)の安全性を高めるための「アクティベーション・ステアリング」において、従来の回転手法がモデルの内部状態(ノルム)を歪ませ、特に7B未満の小規模モデルで生成崩壊を引き起こす問題を特定しました。 本論文が提案する「Selective Steering(選択的ステアリング)」は、数学的に厳密なノルム保存回転と、特徴が明確に現れる層のみを動的に選択する手法を組み合わせることで、モデルの本来の能力を損なうことなく高度な行動制御を実現します。 実験では、既存手法と比較して攻撃成功率(ASR)を最大5.5倍向上させつつ、標準的なベンチマークでの性能維持率100%と、生成の安定性を示すパープレキシティの異常値ゼロを同時に達成したことが示されました。
なぜこの問題か
大規模言語モデル(LLM)の安全性を確保するために、RLHF(人間からのフィードバックによる強化学習)などの手法が用いられてきましたが、依然として「脱獄(ジェイルブレイク)」や有害な行動を誘発する攻撃に対して脆弱であるという課題があります。従来の調整手法は膨大な再学習コストがかかる上、特定のタスクでの性能低下を招くことが少なくありません。これに対する代替案として、推論時にモデルの内部表現を直接操作する「アクティベーション・ステアリング」が注目されています。 しかし、既存のアクティベーション・ステアリング手法には重大な欠陥が存在します。例えば、特定のベクトルを加算する手法(Activation Addition)は、係数の微調整が困難であり、層ごとのノルムの変化に敏感すぎます。また、特定の方向の成分を完全に削除する手法(Directional Ablation)は、オンかオフかの二値的な制御しかできず、きめ細かな調整が不可能です。…
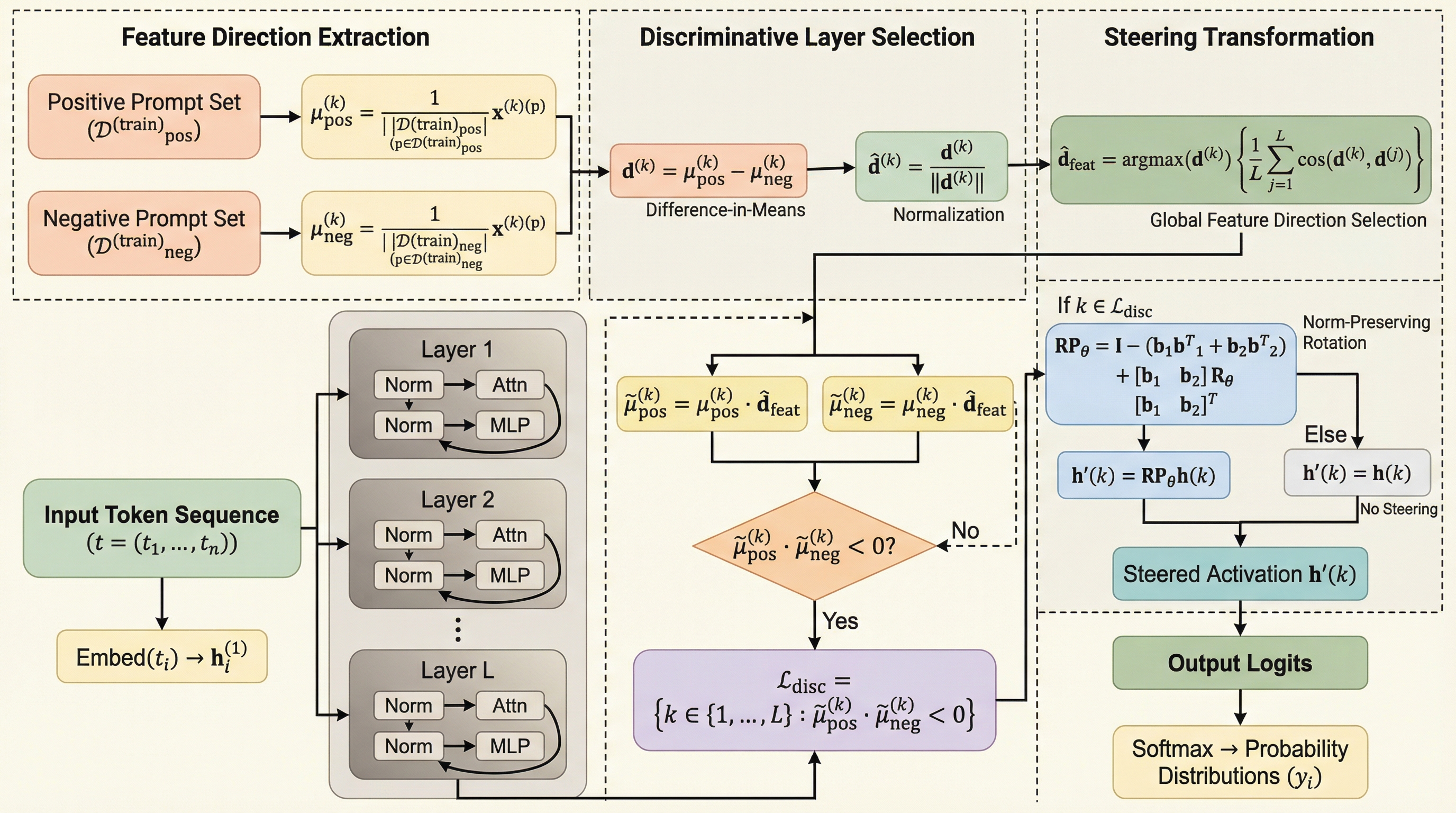
核心:何を提案したのか
本論文は、LLMの内部表現を安定かつ効果的に制御するための新手法「Selective Steering(SS:選択的ステアリング)」を提案しています。この手法の核心は、大きく分けて2つの革新的なアプローチにあります。 第一に、数学的に厳密な「ノルム保存回転(Norm-Preserving Rotation)」の導入です。従来の手法では、回転行列の適用時に計算上の不備があり、アクティベーションのベクトル長(ノルム)が変化してしまっていました。SSでは、直交射影と回転を組み合わせた厳密な定式化を用いることで、回転操作後もベクトルのノルムが完全に維持されることを数学的に証明し、実装しました。これにより、モデル内の正規化層(LayerNormやRMSNorm)との整合性が保たれ、分布のシフトや生成の不安定化を防ぐことができます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related