自動ポストエディットにおいて、LLMは本当により長いコンテキストから恩恵を受けているのか?
商用大型言語モデル(LLM)は、単純なプロンプト操作のみで人間と同等の自動ポストエディット(APE)品質を達成可能ですが、ドキュメント全体のコンテキストを追加しても翻訳品質に統計的に有意な向上は見られず、長文コンテキストの活用の難しさが浮き彫りになりました。
TL;DR(結論)
商用大型言語モデル(LLM)は、単純なプロンプト操作のみで人間と同等の自動ポストエディット(APE)品質を達成可能ですが、ドキュメント全体のコンテキストを追加しても翻訳品質に統計的に有意な向上は見られず、長文コンテキストの活用の難しさが浮き彫りになりました。 オープンウェイトモデルは長大なコンテキストやノイズに対して非常に脆弱であり、データポイズニング攻撃のような状況下で性能が著しく低下する一方で、商用モデルは高い堅牢性を示すものの、文書レベルのコンテキストを修正に効果的に活用できていないという機能的な限界を抱えています。 ドキュメントレベルの自動ポストエディットは、商用モデルにおいて膨大なトークン消費と遅延を発生させるため実用的な導入にはコスト面での障壁が高く、また既存の自動評価指標では質的な改善を正確に測定できないため、依然として人間による詳細な評価が不可欠であると結論付けられています。
なぜこの問題か
機械翻訳(MT)の技術は飛躍的に向上しており、文単位の評価においては人間による翻訳と同等、あるいはそれを上回る精度に達したという報告も散見されます。しかし、実際の翻訳現場では依然として誤りが残ることが多く、人間がゼロから翻訳を行う作業は非常に時間がかかり、認知的な負担も大きいという課題があります。専門の翻訳者が1時間に処理できる文数は約503文程度と推定されていますが、最新のGPT-4oのようなモデルであれば、同じ分量をわずか数秒で処理できる圧倒的な速度を持っています。この効率性の差を埋めるために、機械翻訳の誤りを人間が修正するポストエディット(PE)という手法が普及してきましたが、これには「翻訳調」の不自然な表現が残る、あるいは文レベルの翻訳では文書全体の整合性が保たれないといった「ポストエディット特有の不自然さ」が生じるリスクがあります。 特に、文単位の機械翻訳では文脈の不一致や用語の揺れが生じやすく、人間がそれを修正する際には文書全体を読み直して一貫性を確認するための追加の認知的努力が必要となります。…
核心:何を提案したのか
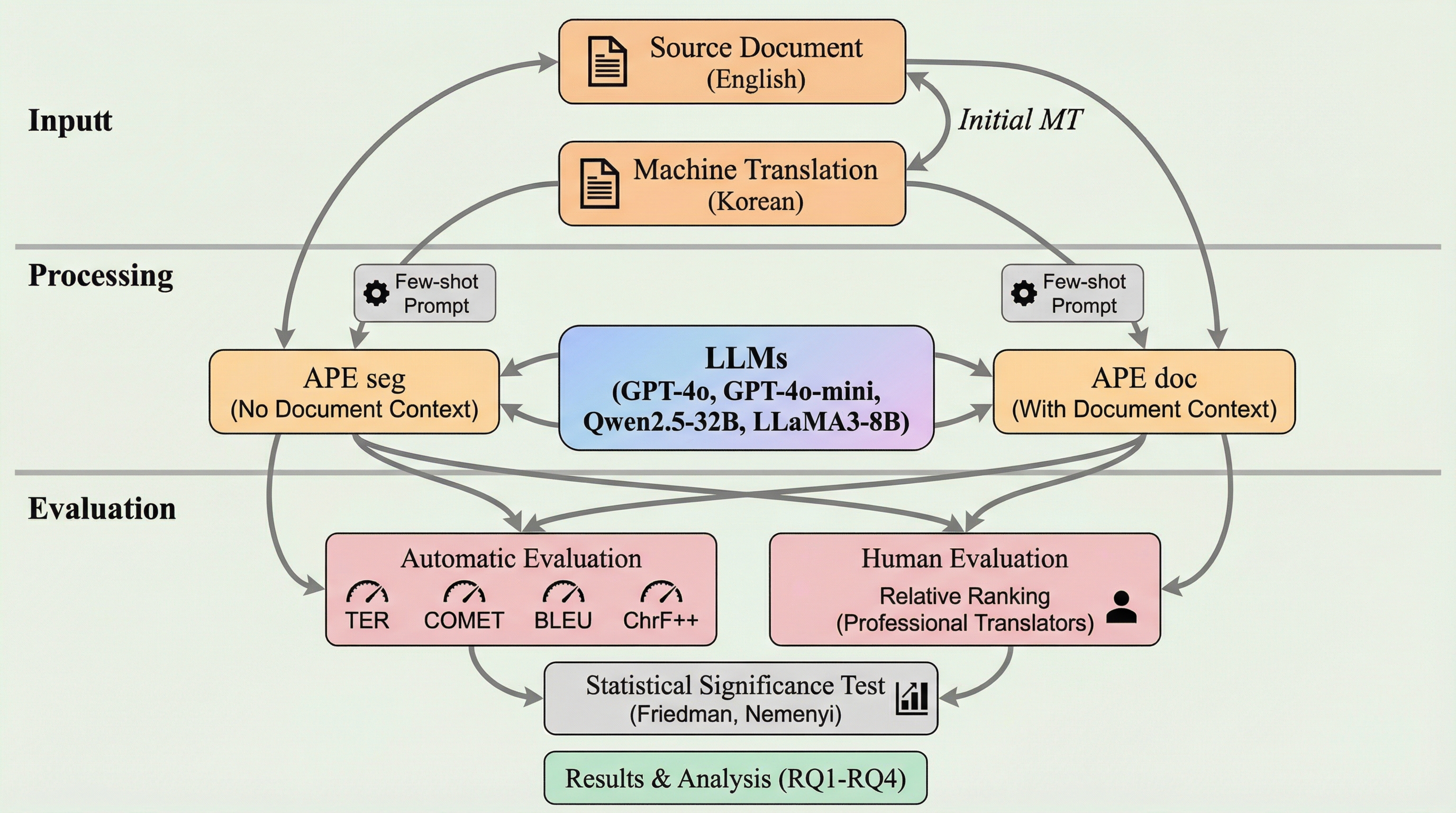
本研究では、商用LLMとオープンウェイトLLMを対象に、文書レベルのコンテキストを活用した自動ポストエディット(APE)の性能を体系的に比較・分析する枠組みを提案しました。具体的には、従来の文単位での修正(APE seg)と、文書全体の情報をプロンプトに含めた修正(APE doc)の二つの設定を用意し、それらが翻訳品質にどのような影響を与えるかを多角的に検証しています。この比較を通じて、モデルが文書レベルの情報をどの程度「理解」し、それを「修正」という具体的なタスクに反映できているのかを明らかにしようと試みました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related