ベンチマークが漏洩するとき:LLMのための推論時における汚染除去
大規模言語モデルの評価において、テストデータが訓練データに混入する「データ汚染」が性能を不当に高く見せる問題に対し、推論時に埋め込み空間へ微小な摂動を加えることで記憶によるショートカットを抑制する手法「DeconIEP」が提案されました。
TL;DR(結論)
大規模言語モデルの評価において、テストデータが訓練データに混入する「データ汚染」が性能を不当に高く見せる問題に対し、推論時に埋め込み空間へ微小な摂動を加えることで記憶によるショートカットを抑制する手法「DeconIEP」が提案されました。 この手法は、モデルのパラメータやベンチマークの問題文自体を変更することなく、比較的汚染の少ない参照モデルを用いて学習した生成器により、汚染されたサンプルに対する過剰な適合を抑え、モデル本来の推論能力を引き出すことを可能にします。 複数のオープンウェイトモデルを用いた実験の結果、既存の手法と比較して、汚染による性能の誇張を効果的に低減させつつ、汚染されていないクリーンなタスクにおける性能低下を最小限に抑えることができることが確認されました。
なぜこの問題か
大規模言語モデル(LLM)の急速な発展に伴い、その能力を客観的に評価するためのベンチマークの重要性はかつてないほど高まっています。MMLUやTruthfulQAといった標準的なベンチマークでのスコアは、モデルの推論能力や知識量を示す決定的な証拠として扱われ、モデルの選択やデプロイの意思決定、さらには科学的な比較における標準的な指標となっています。しかし、これらの評価の信頼性は「テストセットの汚染(Data Contamination)」という深刻な問題によって脅かされています。これは、テストサンプルやその類似バリエーションが意図的または不注意に訓練データに含まれてしまう現象を指します。汚染が発生すると、モデルは真の汎化能力ではなく、単なる記憶によって高いスコアを出してしまい、報告される性能が実世界の能力を正しく反映しなくなります。 特にオープンウェイトモデルの普及により、この問題はさらに複雑化しています。オープンウェイトモデルは自由にダウンロード、微調整、マージが可能であるため、訓練パイプラインが極めて分散化されています。…
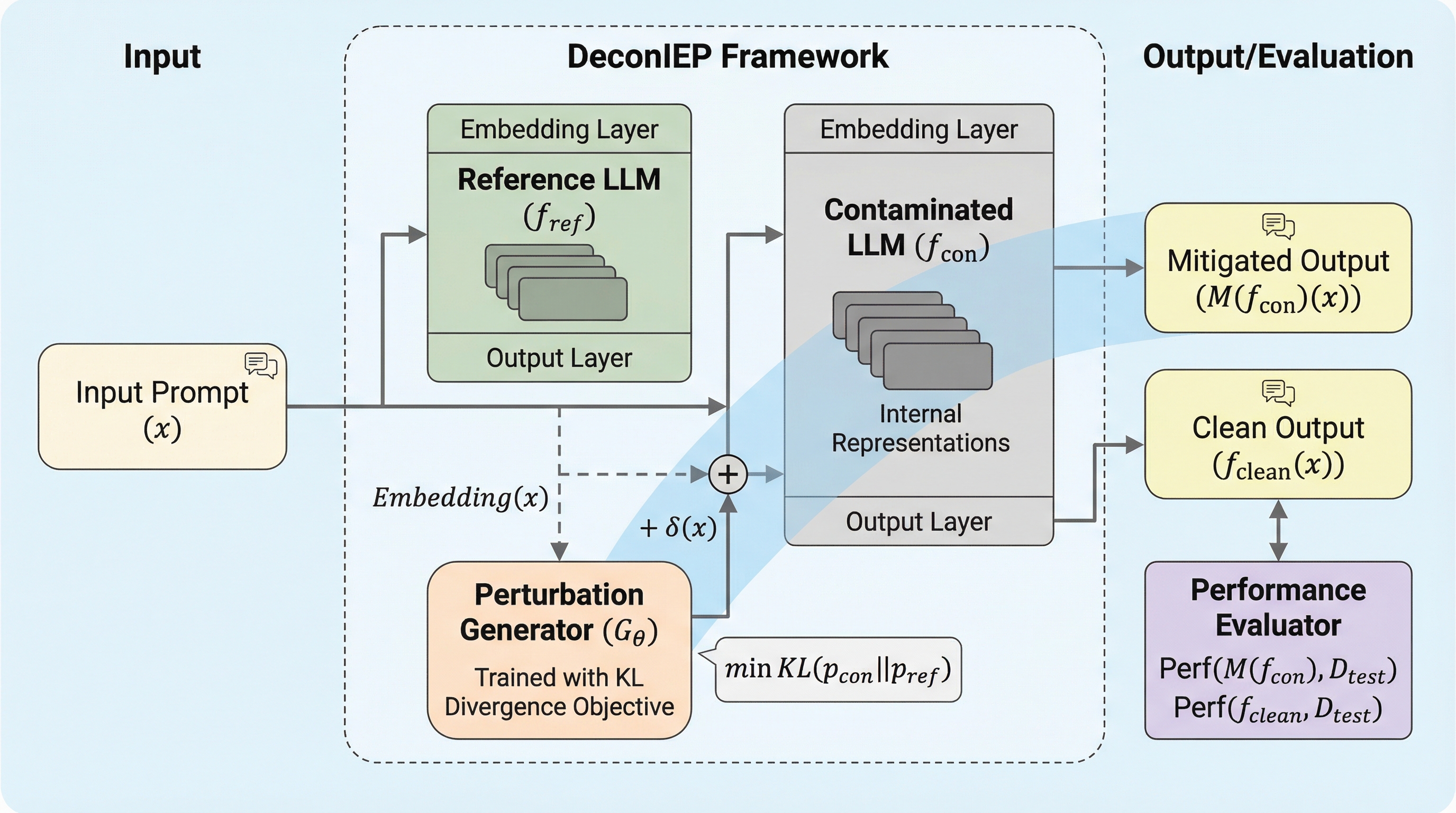
核心:何を提案したのか
本論文では、推論時に埋め込み空間へ摂動を加えることで汚染の影響を緩和する新しいフレームワーク「DeconIEP(Decontamination via Inference-time Embedding Perturbation)」を提案しています。この手法の根底にあるのは、データ汚染がモデル内部の予測プロセスを根本的に変化させるという重要な観察結果です。クリーンなサンプルに対して、モデルは多くの入力に共通する汎用的な推論機能を用いて予測を行いますが、汚染されたサンプルに対しては、記憶に依存した「ショートカット・ニューロン」や特定の「検索経路」を利用して出力を生成する傾向があります。つまり、汚染されたモデルは本来の推論プロセスをバイパスして、記憶から答えを直接引き出しているのです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related