対話型推薦における長期的ユーザー満足度のためのLLM強化型強化学習
対話型推薦システムが陥りやすいフィルターバブルや内容の均質化という課題に対し、大規模言語モデル(LLM)の論理的計画能力と強化学習(RL)の適応力を組み合わせた階層型フレームワーク「LERL」を開発した。
TL;DR(結論)
対話型推薦システムが陥りやすいフィルターバブルや内容の均質化という課題に対し、大規模言語モデル(LLM)の論理的計画能力と強化学習(RL)の適応力を組み合わせた階層型フレームワーク「LERL」を開発した。 高レベルのLLMプランナーがユーザー履歴から意味的に多様なカテゴリを選択し、低レベルのRLポリシーがその制限内で具体的なアイテムを推薦することで、探索空間を絞り込みつつ長期的な満足度を最適化する仕組みを構築した。 実世界のデータセットを用いたシミュレーション実験の結果、提案手法は既存の最新手法と比較して、ユーザーの飽きを防ぎながら長期的なエンゲージメントを有意に向上させることが確認され、多様性と精度の両立に成功した。
なぜこの問題か
現代のオンラインプラットフォームにおいて、対話型推薦システムはユーザーのフィードバックにリアルタイムで適応し、パーソナライズされた体験を提供する重要な役割を担っている。しかし、多くのシステムはユーザーの短期的な好みに過剰に適合してしまう傾向があり、その結果として意味的に類似したアイテムばかりを繰り返し提示する内容の均質化が問題となっている。このような現象はフィルターバブル効果を助長し、ユーザーが過去の行動や視点に合致するコンテンツのみにさらされることで、長期的には満足度が低下する要因となる。既存の研究では多様性を高めるための再ランキングや表現学習などが提案されているが、その多くは静的な設定に留まっており、ユーザーの関心が時間の経過とともにどのように進化するかという動的な側面を十分に考慮できていない。 強化学習は逐次的な意思決定プロセスをモデル化し、長期的な累積報酬を最適化するための有力な枠組みを提供するが、推薦システムへの適用には特有の困難が伴う。…
核心:何を提案したのか
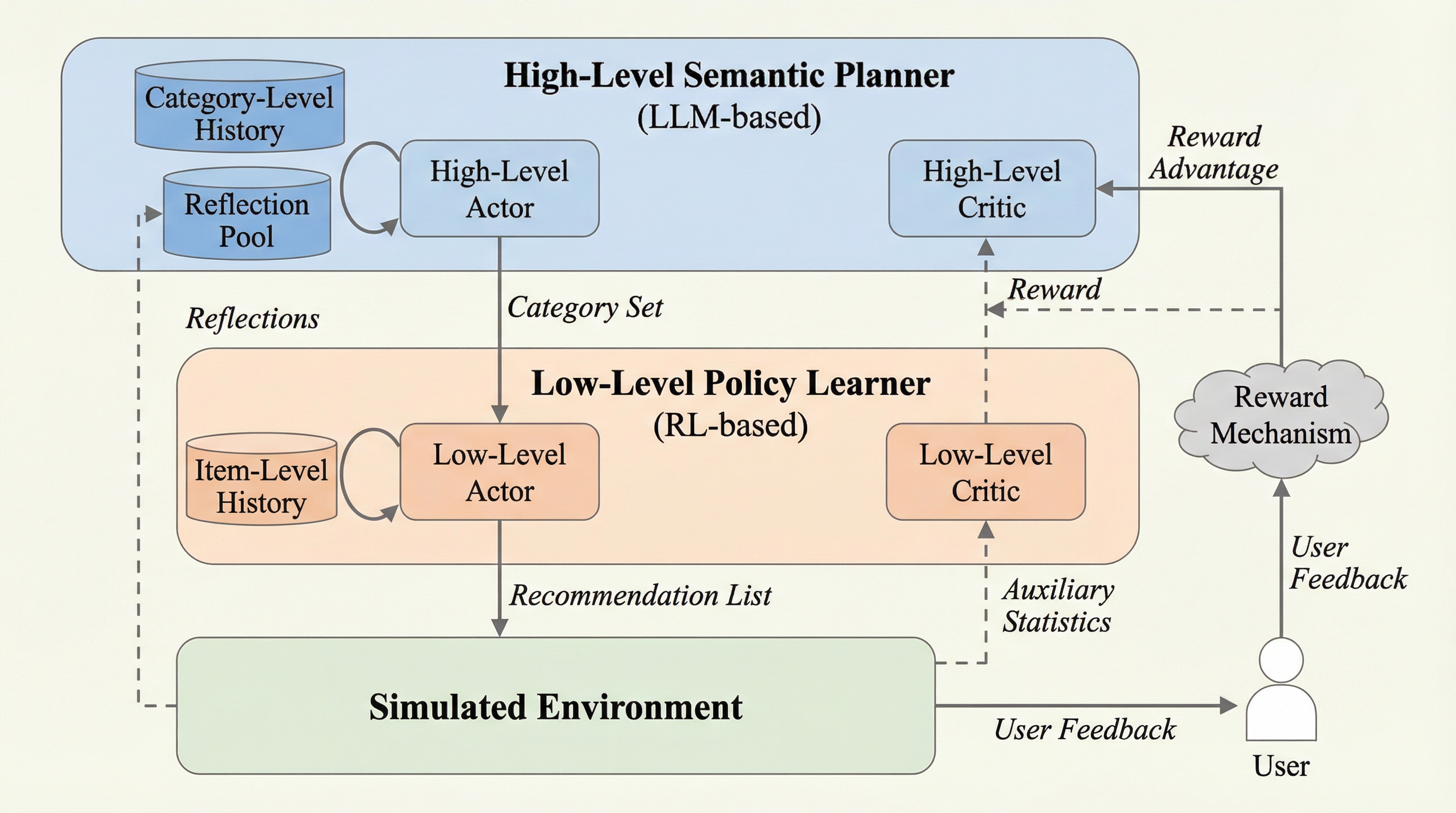
本研究では、大規模言語モデルによる意味的な計画能力と、強化学習によるきめ細かな適応力を統合した新しい階層型推薦フレームワークである「LERL(LLM-Enhanced Reinforcement Learning)」を提案した。このフレームワークの核心は、推薦プロセスを二つの異なる階層に分解し、それぞれのモデルが得意とする役割を分担させる設計にある。高レベルの階層では、LLMを活用したセマンティックプランナーがユーザーのインタラクション履歴を分析し、意味的に多様なコンテンツカテゴリのサブセットを選択する役割を担う。このプランナーは、最近過剰に露出されたコンテンツタイプを避け、多様性を優先することでフィルターバブルの発生を抑制する戦略的な意思決定を行う。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related