視覚生成はマルチモーダル世界モデルを通じて人間のような推論能力を解き放つ
本研究は、統一マルチモーダルモデル(UMM)における視覚生成が、物理的・空間的推論を必要とするタスクにおいて「世界モデル」として機能し、従来の言語のみの推論(CoT)を大幅に上回る性能を発揮することを理論と実験の両面から明らかにしました。
TL;DR(結論)
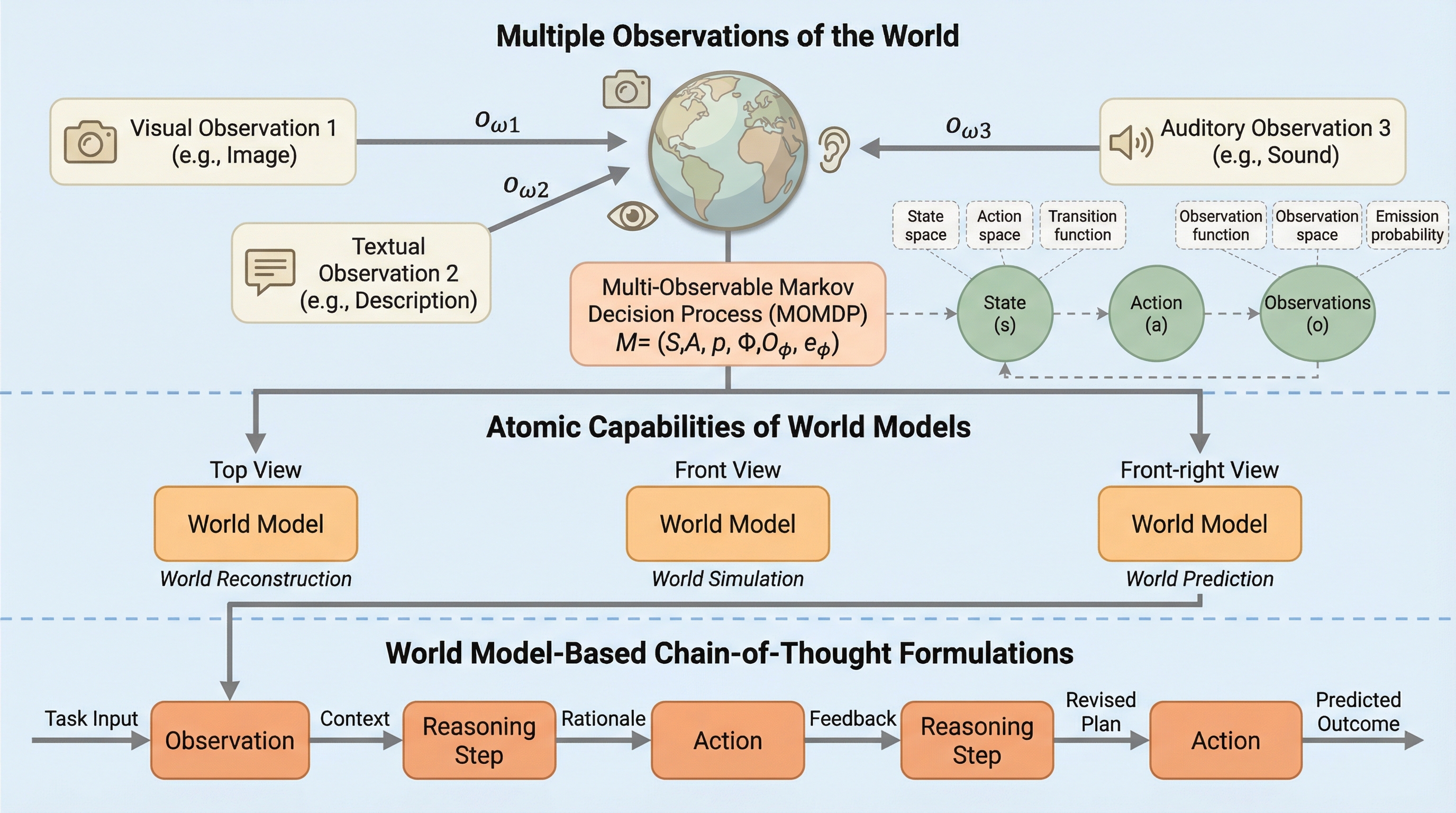
本研究は、統一マルチモーダルモデル(UMM)における視覚生成が、物理的・空間的推論を必要とするタスクにおいて「世界モデル」として機能し、従来の言語のみの推論(CoT)を大幅に上回る性能を発揮することを理論と実験の両面から明らかにしました。 研究チームは、世界モデルの能力を「世界再構成」と「世界シミュレーション」として定式化し、視覚的推論が言語的推論の限界を補完するという「視覚的優位性仮説」を提唱するとともに、新たな評価スイートであるVisWorld-Evalを構築してその有効性を検証しました。 実験の結果、物理世界に根ざした複雑なタスクでは視覚と言語を交互に行う推論が有効である一方、迷路や倉庫番のような単純な状態空間を持つタスクでは明示的な視覚生成の優位性が限定的であるという、視覚生成の適用境界を明確に示しました。
なぜこの問題か
人間は外部世界を理解する際、頭の中にオブジェクトやその関係性、動作メカニズムを表現する「内部メンタルモデル(世界モデル)」を構築しています。このモデルを用いることで、例えばテーブルに水がこぼれた際に「水が床に滴り落ちる」といった未来の出来事を精神的にシミュレーションし、実際に起こる前に行動を決定することができます。こうした能力は物理的な事象だけでなく、数学や論理学といった抽象的な領域にも拡張されており、人間知能の根幹をなすものと考えられてきました。 近年の人工知能、特に大規模言語モデル(LLM)における「思考の連鎖(Chain-of-Thought, CoT)」の進展は、こうした人間の推論プロセスを近似するものとして注目されています。現在のAIシステムは、数学やプログラミングといった形式的・抽象的なドメインでは専門家レベルの性能を達成していますが、物理的・空間的な知能が求められる領域では依然として人間に大きく遅れをとっています。これは、現在のシステムの多くが言語的な情報処理経路に依存しており、物理世界の豊かな表現や事前知識を十分に活用できていないためだと考えられます。…
核心:何を提案したのか
本研究の核心は、視覚生成が特定のタスクにおいて言語的な世界モデルよりも自然で強力な「世界モデル」として機能するという「視覚的優位性仮説(Visual Superiority Hypothesis)」の提唱と検証にあります。研究チームは、世界モデルをマルチモーダルな視点から再定義し、AIが人間のように物理世界をシミュレーションしながら推論するための理論的枠組みを構築しました。 具体的には、まず世界モデルの内部的な働きを、タスクの背後にある「多観測マルコフ決定過程(MOMDP)」を近似するものとして定式化しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related