LLM支援型論理ルール学習:時系列異常検知における人間の専門知識の拡張
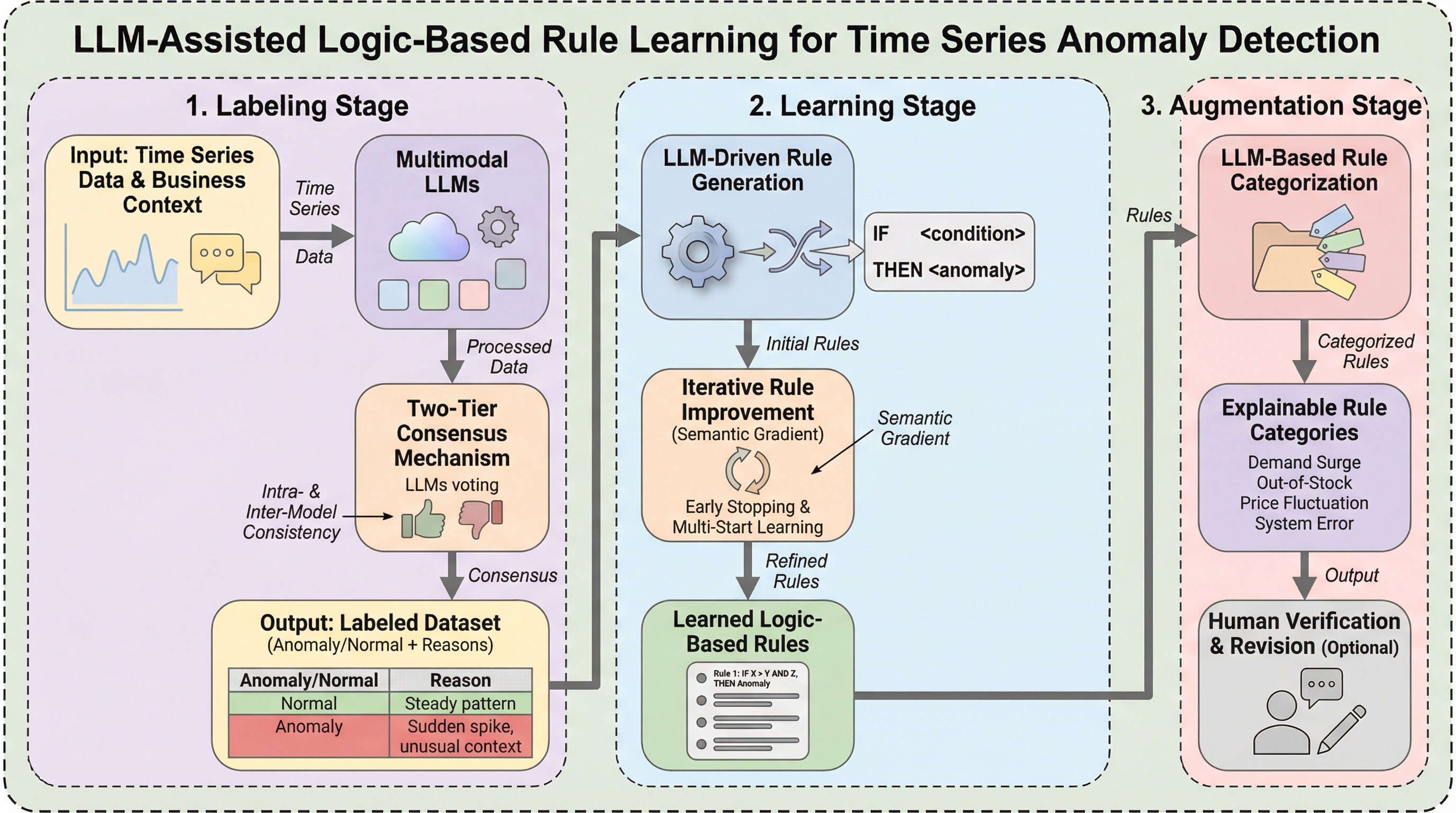
アマゾンのサプライチェーンにおける膨大な製品数の異常検知を効率化するため、人間の専門知識を大規模に拡張する新しいフレームワークが提案されました。従来の教師なし学習手法ではビジネス文脈の反映が難しく、一方で人間による手動の分析や大規模言語モデル(LLM)の直接的な運用には、コストや遅延、非決定性といった実用上の大きな課題が存在していました。 本手法は、マルチモーダルLLMを用いたデータのラベル付け、LLMによる論理ルールの自動生成と反復的な最適化、そしてビジネス上の解釈性を高めるルールの拡張という3つの段階で構成されています。特に、LLMを「セマンティックな勾配」として利用し、ルールの振る舞い分析に基づいて論理構造を修正する仕組みを導入することで、機械学習のような体系的な学習プロセスを実現しています。 実験の結果、提案手法は従来の教師なし学習を精度と解釈性の両面で上回り、LLMを直接運用する場合と比較して、低コストかつ低遅延で決定論的な結果を提供できることが確認されました。これにより、ブラックボックスではない透明性の高いルールを本番環境にデプロイすることが可能となり、専門家による検証や修正も容易な、実用的な異常検知システムが構築されました。