推論に重要なニューロンの特定と転移:アクティベーションステアリングによるLLM推論の信頼性向上
大規模言語モデル(LLM)の内部には、推論の正誤と強く相関する「推論重要ニューロン(RCN)」が少数存在することを発見し、これを利用した軽量な介入フレームワーク「AdaRAS」を提案しました。 この手法は、正解と不正解の推論軌跡における活性化パターンの差からRCNを特定し、推論の失敗が予測される場合にのみ適応的にニューロンの活性化を調整することで、追加学習なしで推論の信頼性を向上させます。 数学やコード生成の10個のベンチマークで一貫した性能向上を確認し、特に難易度の高いAIME-24およびAIME-25では13%以上の精度向上を達成するとともに、異なるデータセットやモデル間での高い転移性も示しました。
TL;DR(結論)
大規模言語モデル(LLM)の内部には、推論の正誤と強く相関する「推論重要ニューロン(RCN)」が少数存在することを発見し、これを利用した軽量な介入フレームワーク「AdaRAS」を提案しました。 この手法は、正解と不正解の推論軌跡における活性化パターンの差からRCNを特定し、推論の失敗が予測される場合にのみ適応的にニューロンの活性化を調整することで、追加学習なしで推論の信頼性を向上させます。 数学やコード生成の10個のベンチマークで一貫した性能向上を確認し、特に難易度の高いAIME-24およびAIME-25では13%以上の精度向上を達成するとともに、異なるデータセットやモデル間での高い転移性も示しました。
なぜこの問題か
近年の大規模言語モデルは、数学的推論やコード生成といった複雑なタスクにおいて驚異的な能力を発揮していますが、その推論プロセスが常に信頼できるわけではありません。特に難易度の高い問題では、モデルが論理的な飛躍や誤った前提に基づいた推論を行ってしまうことが頻繁にあります。現在、この信頼性を向上させるための主なアプローチは、教師あり微調整(SFT)や強化学習(RLHF)といった事後学習、あるいは推論時に大量の回答を生成して多数決をとるサンプリング戦略に依存しています。しかし、事後学習には膨大な計算リソースと高品質なデータが必要であり、サンプリング戦略は推論コストを劇的に増大させるという課題があります。また、これらの手法の多くはモデルをブラックボックスとして扱うため、なぜ推論が失敗するのか、あるいは成功するのかという内部的なメカニズムについての洞察をほとんど提供しません。 一方で、モデルの内部状態を直接操作するアクティベーション・エンジニアリングという手法が注目を集めています。…
核心:何を提案したのか
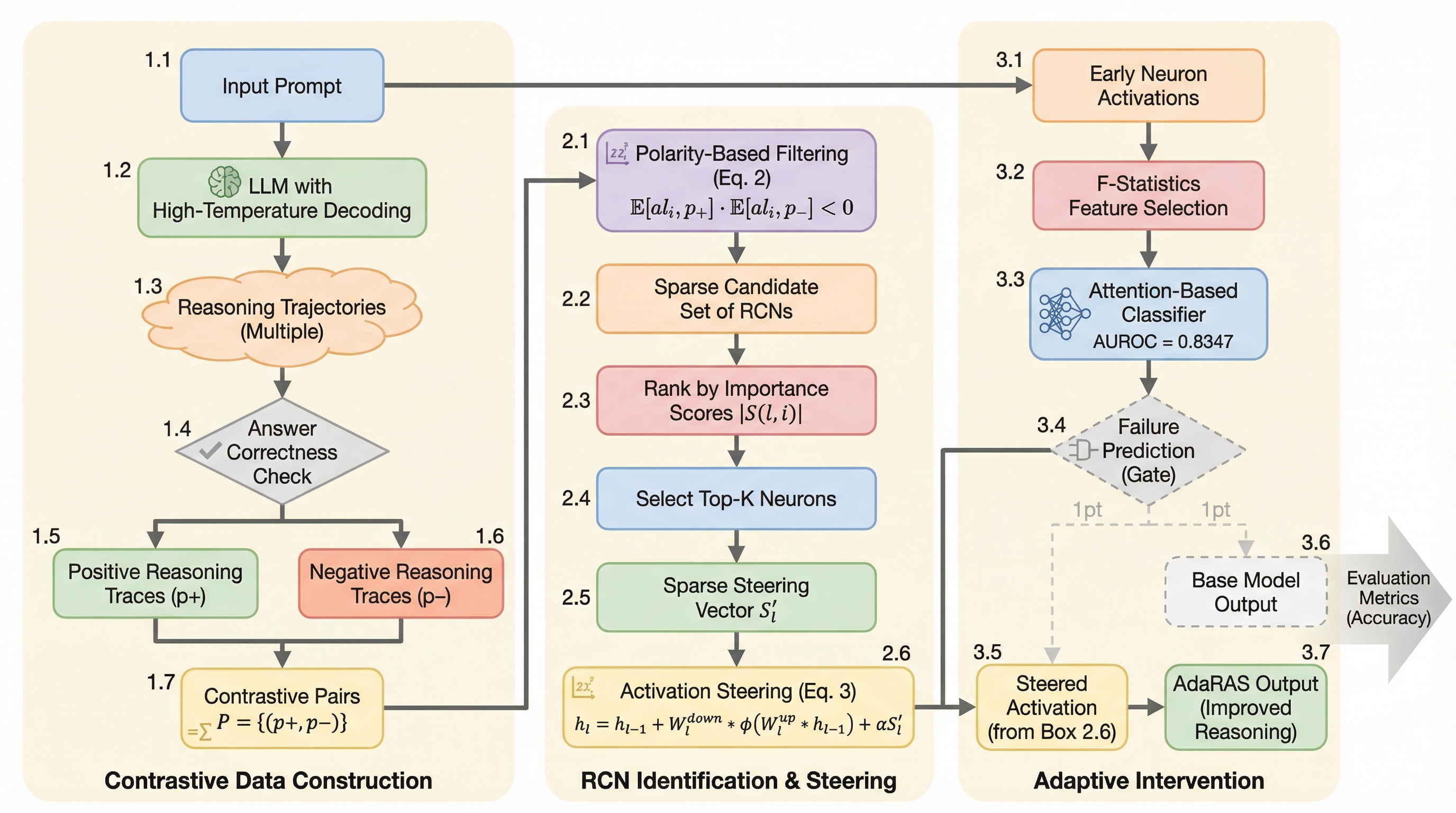
本論文では、大規模言語モデルの推論信頼性を向上させるための新しい軽量なテスト時フレームワーク「AdaRAS(Adaptive Reasoning Activation Steering)」を提案しています。この手法の核心的なアイデアは、モデル内部の全ニューロンの中から、推論の成功に直接的に寄与する「推論重要ニューロン(RCN)」を特定し、その活性化を動的に制御することにあります。研究チームは、同じ問題に対してモデルが生成した「正解の推論軌跡」と「不正解の推論軌跡」を比較分析することで、特定のニューロンが推論の正誤に応じて極めて対照的な活性化パターンを示すことを突き止めました。 AdaRASは、これらのRCNを特定するために、平均活性化値の差(Mean Difference)を指標として用い、さらに正誤によって活性化の正負(極性)が反転するニューロンを優先的に選択する「極性認識フィルタリング」を導入しています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related