ニューラル・ニューラルスケーリング則
従来のべき乗則やロジスティック関数に基づくスケーリング則は、平均検証損失という単一の指標に依存しており、下流タスクで見られる「逆スケーリング」や「性能の停滞」といった多様な挙動を正確に予測できないという根本的な課題を抱えていました。
TL;DR(結論)
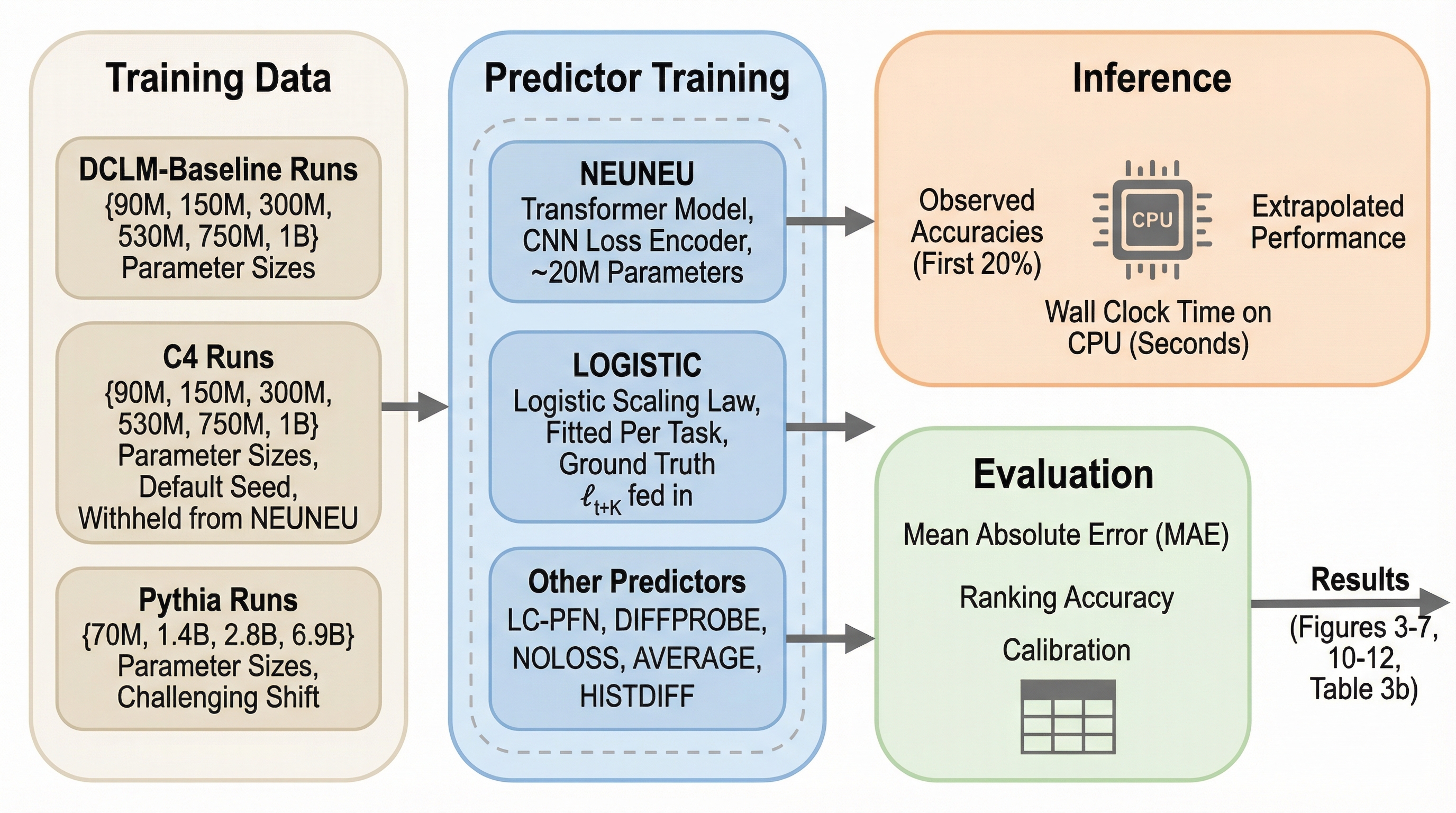
従来のべき乗則やロジスティック関数に基づくスケーリング則は、平均検証損失という単一の指標に依存しており、下流タスクで見られる「逆スケーリング」や「性能の停滞」といった多様な挙動を正確に予測できないという根本的な課題を抱えていました。 本研究が提案する「NEUNEU(Neural Neural Scaling Laws)」は、平均化される前のトークンレベルの損失分布と過去の精度推移を時系列データとして扱うニューラルネットワークであり、従来のロジスティック法と比較して予測誤差(MAE)を38%削減し、2.04%という極めて高い精度を達成しました。 このモデルは、学習時に一度も見ていない未知のモデルファミリーやパラメータ数、さらには未知の下流タスクに対してもゼロショットで適応可能であり、大規模な計算資源を投入する前にモデルの最終的な優劣を75.6%の確率で正しく判定できる実用的な意思決定支援ツールとなります。
なぜこの問題か
言語モデルの開発において、計算量やデータ量、パラメータ数の増加に伴ってモデルの性能がどのように向上するかを記述する「スケーリング則」は、限られた計算資源を最適に配分するための羅針盤として不可欠な存在です。しかし、これまでの研究で広く用いられてきたべき乗則などの単純な関数形式は、主に訓練損失や検証損失といった集約された指標の予測に特化しており、実際の運用で重要となる「下流タスクでの精度」を予測するには限界がありました。検証損失自体はモデルの規模に応じて滑らかな曲線を描いて改善していく一方で、個別のタスクに目を向けると、規模に応じて精度が向上するものもあれば、ある地点で成長が止まるもの、さらには規模が大きくなるほど精度が悪化する「逆スケーリング」現象を示すものまで存在し、その挙動は極めて多様です。 著者らは、従来の予測手法が抱える問題として二つの大きな仮説を立てています。第一に、従来の指標である「平均検証損失」は、無数のトークンレベルの損失を平均化する過程で、将来の性能予測に役立つはずの重要な信号を削ぎ落としてしまう「任意のボトルネック」になっているという点です。…
核心:何を提案したのか
本論文では、スケーリング則の予測を特定の関数へのフィッティングではなく、データ駆動型の「時系列の補外(エキストラポレーション)」問題として再定義する、ニューラルネットワークを用いた新しいアプローチ「Neural Neural Scaling Laws(NEUNEU)」を提案しています。NEUNEUの最大の特徴は、べき乗則やロジスティック関数のような特定の数式を事前に一切仮定せず、膨大なオープンソースのモデル訓練軌跡からスケーリングのパターンを直接学習する点にあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related