LLM推論のためのグループ分布ロバスト最適化駆動型強化学習
大規模言語モデル(LLM)の推論学習において、従来の強化学習手法が抱えていた「全問題を一律に扱う非効率性」を解消するため、問題の難易度に応じて学習の重みと計算資源を動的に配分する「マルチ敵対的GDROフレームワーク」が提案されました。
TL;DR(結論)
大規模言語モデル(LLM)の推論学習において、従来の強化学習手法が抱えていた「全問題を一律に扱う非効率性」を解消するため、問題の難易度に応じて学習の重みと計算資源を動的に配分する「マルチ敵対的GDROフレームワーク」が提案されました。 この手法は、モデルの正答率から難易度をリアルタイムで判定する「オンライン難易度分類器」を導入し、難問を優先的にサンプリングする「Prompt-GDRO」と、限られた計算予算内で探索回数を最適化する「Rollout-GDRO」という2つの独立した最適化機構を備えています。 Qwen3モデルを用いた検証では、数学的推論ベンチマークにおいて従来のGRPO手法を大幅に上回る性能向上を達成しており、学習の進展に合わせて「推論の最前線」へとリソースを自動的にシフトさせる創発的なカリキュラム学習が実現されていることが確認されました。
なぜこの問題か
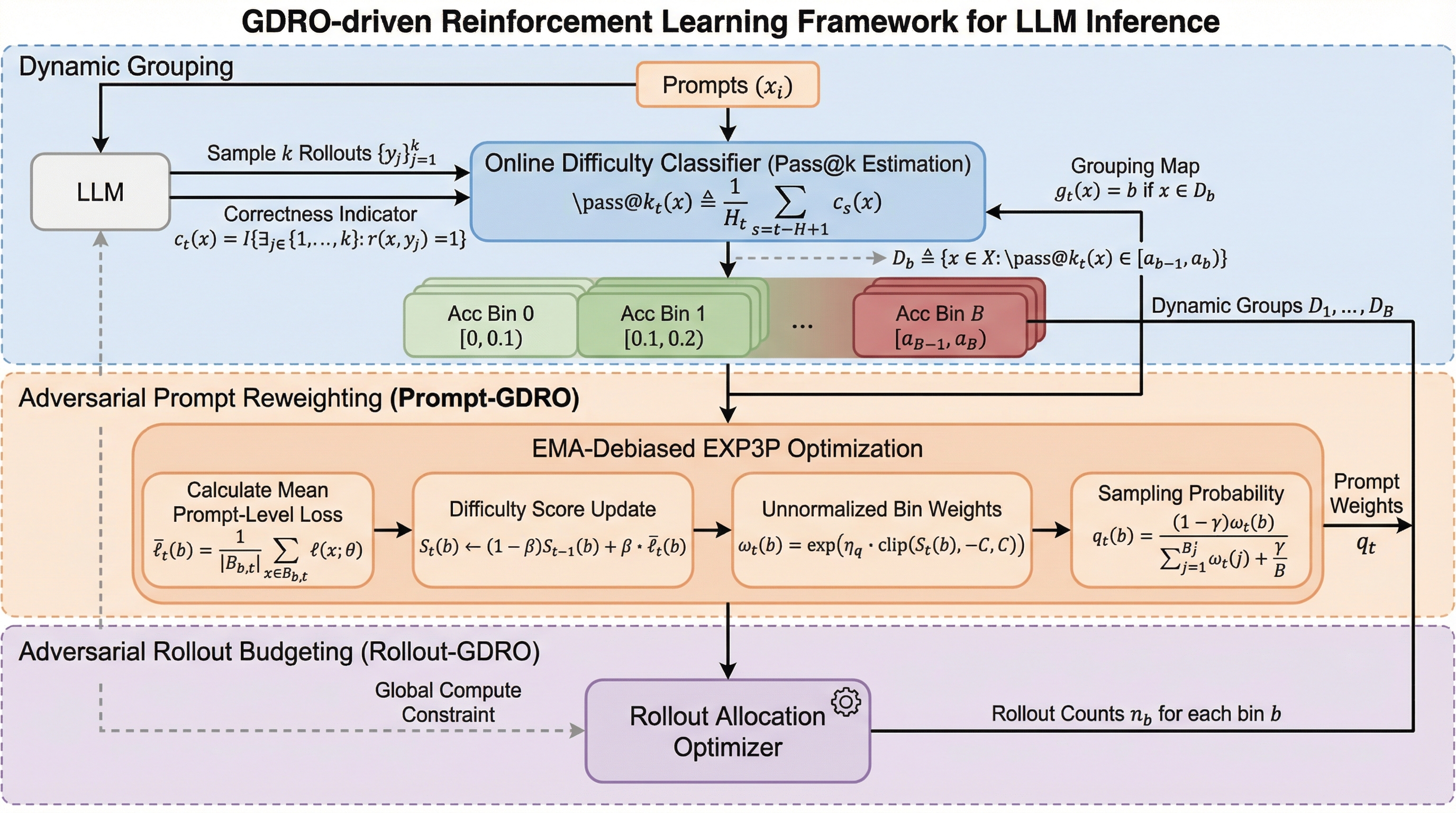
大規模言語モデル(LLM)の複雑な推論能力を向上させる鍵は、モデルのアーキテクチャそのものよりも、事後学習における損失関数の設計やアライメント戦略にあるという視点が強まっています。現在、数学的問題解決やコード生成の分野では、近接方策最適化(PPO)やグループ相対方策最適化(GRPO)といった強化学習手法が標準的に用いられています。しかし、これらの既存手法には「静的な一様性」という根本的な制約が存在します。具体的には、トレーニングセット内のすべてのプロンプトを一律の頻度でサンプリングし、各プロンプトに対して固定された回数のロールアウト(回答生成と検証)を割り当てるという運用がなされています。 推論タスクのデータセットは本質的に不均一であり、初等的な代数から高度な数論まで、難易度の分布は非常に重い裾(ヘビーテイル)を持っています。このようなデータに対して一様な学習を行うと、モデルはすでに解法を習得した簡単な問題に計算資源を浪費し続ける一方で、真に学習が必要な難易度の高い問題(ロングテイル部分)に対して十分な学習信号を得られないという構造的な非効率が生じます。…
核心:何を提案したのか
本研究では、上述の静的な一様性を打破するために、グループ分布ロバスト最適化(GDRO)の理論を応用した「マルチ敵対的GDROフレームワーク」を提案しています。このフレームワークの最大の特徴は、学習プロセスを「学習者(LLM)」と、その弱点を突こうとする「複数の敵対者(アドバーサリ)」との間のゼロサムゲームとして定式化している点にあります。具体的には、モデルの現在の習熟度に基づいてプロンプトを動的にグループ化し、それらのグループ間で学習の重みと計算資源を最適に配分する2つの独立した敵対的メカニズムを導入しました。 第一の柱は、データの配分を司る「Prompt-GDRO」です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related