DiaDem:マルチモーダル大規模言語モデルのための視聴覚動画キャプション生成における対話記述の高度化
視聴覚動画キャプション生成において、従来のモデルは「誰が何を話したか」という対話の正確な記述、特に複数人による複雑なシーンでの話者特定や発話の書き起こしに大きな課題を抱えていた。 本研究では、対話記述の精度を大幅に向上させた新モデル「DiaDem」と、話者特定(REF)と発話書き起こし(ASR)の正確性を厳密に評価するための初となる専用ベンチマーク「DiaDemBench」を提案した。 高品質な合成データを用いた教師あり微調整(SFT)と、難易度別に分割された二段階のGRPO戦略を組み合わせることで、DiaDemは対話記述の正確性においてGeminiシリーズを上回る性能を達成し、一般的なキャプション生成能力も高い水準で維持している。
TL;DR(結論)
視聴覚動画キャプション生成において、従来のモデルは「誰が何を話したか」という対話の正確な記述、特に複数人による複雑なシーンでの話者特定や発話の書き起こしに大きな課題を抱えていた。 本研究では、対話記述の精度を大幅に向上させた新モデル「DiaDem」と、話者特定(REF)と発話書き起こし(ASR)の正確性を厳密に評価するための初となる専用ベンチマーク「DiaDemBench」を提案した。 高品質な合成データを用いた教師あり微調整(SFT)と、難易度別に分割された二段階のGRPO戦略を組み合わせることで、DiaDemは対話記述の正確性においてGeminiシリーズを上回る性能を達成し、一般的なキャプション生成能力も高い水準で維持している。
なぜこの問題か
視聴覚情報を統合した動画キャプション生成は、視覚情報のみに依存する従来の手法を超え、より包括的で人間に近いテキスト記述を可能にする重要な技術である。音声信号を適切に取り入れることで、モデルは動画内の出来事をより深く理解できるようになり、これは事前学習におけるモダリティ間の整合性を高めるだけでなく、その後の視聴覚理解や生成タスクを支える不可欠な基盤となる。しかし、これまでの研究や評価指標の多くは、記述の網羅性や全体的な完成度を優先するあまり、視聴覚シナリオにおいて極めて重要な「対話記述の正確性」を軽視してきたという実態がある。 具体的には、既存のマルチモーダル大規模言語モデルは「誰が何を言ったか」を正確に把握することに苦労しており、特に複数の人物が登場する対話シーンでは、発話内容と話者の結びつけに失敗することが非常に多い。対話における話者の特定と発話の正確な記録は、登場人物の意図を汲み取り、人間関係のダイナミクスを推論し、物語の論理構造を再構築するために不可欠な要素である。この正確性が欠如していると、動画の内容を真に理解したとは言い難く、情報の信頼性も損なわれてしまう。…
核心:何を提案したのか
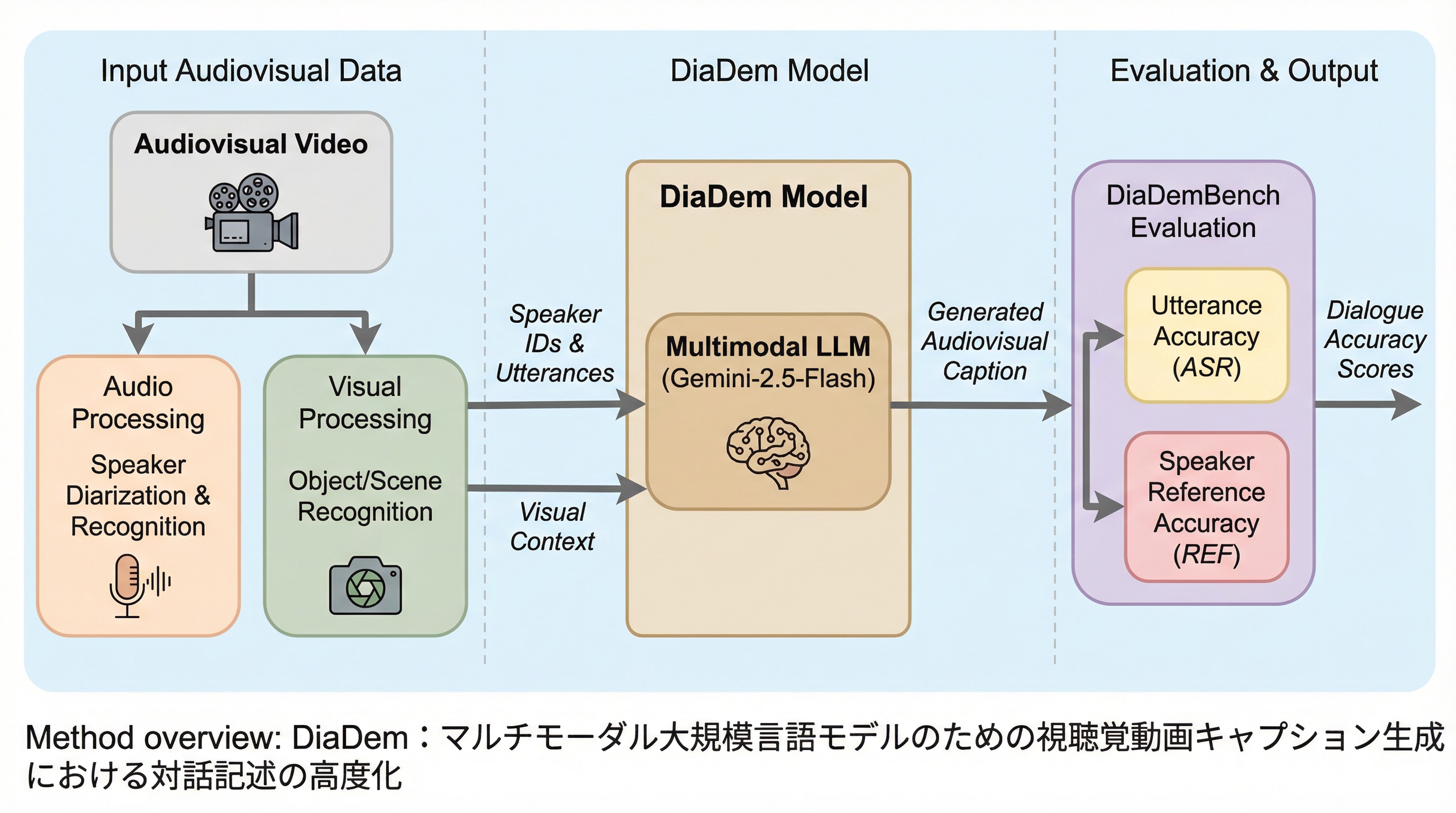
本研究の核心は、対話記述の精度を極限まで高めた視聴覚動画キャプションモデル「DiaDem」と、その能力を多角的に評価するためのベンチマーク「DiaDemBench」を提案したことにある。DiaDemBenchは、1,039本の動画から構成される包括的なテストセットであり、シングルショットからマルチショット、さらには音声が重なり合う困難なシーンまで、多様な対話シナリオを網羅している。このベンチマークは、発話の書き起こし精度(ASR)と話者特定の正確性(REF)という二つの主要な指標を用いて、モデルの対話記述能力を詳細かつ定量的に評価することを可能にした。 モデル開発においては、既存の強力な視聴覚キャプションモデルであるAVoCaDOをベースとし、対話理解を強化するための専用のポストトレーニング戦略を導入している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related