DART:高速なLLM推論のための拡散モデルに着想を得た投機的デコーディング
DARTは、拡散モデルの並列生成能力を投機的デコーディングに導入することで、従来のドラフトモデルが抱えていた自己回帰的な逐次処理による遅延を根本から解消する新しい推論加速フレームワークです。 ターゲットモデルの中間状態を再利用する極めて軽量な設計と、単一のフォワードパスで複数の未来トークンを同時に予測する仕組みにより、ドラフト作成時間を大幅に短縮しつつ、ターゲットモデルとの高い整合性を維持することに成功しました。 実験では、標準的な推論に対して最大3.44倍の高速化を達成し、既存の最先端手法であるEAGLE3を平均で30%上回る圧倒的なパフォーマンスを実証しており、大規模言語モデルの推論効率を実用的なレベルで新たな次元へと引き上げます。
TL;DR(結論)
DARTは、拡散モデルの並列生成能力を投機的デコーディングに導入することで、従来のドラフトモデルが抱えていた自己回帰的な逐次処理による遅延を根本から解消する新しい推論加速フレームワークです。 ターゲットモデルの中間状態を再利用する極めて軽量な設計と、単一のフォワードパスで複数の未来トークンを同時に予測する仕組みにより、ドラフト作成時間を大幅に短縮しつつ、ターゲットモデルとの高い整合性を維持することに成功しました。 実験では、標準的な推論に対して最大3.44倍の高速化を達成し、既存の最先端手法であるEAGLE3を平均で30%上回る圧倒的なパフォーマンスを実証しており、大規模言語モデルの推論効率を実用的なレベルで新たな次元へと引き上げます。
なぜこの問題か
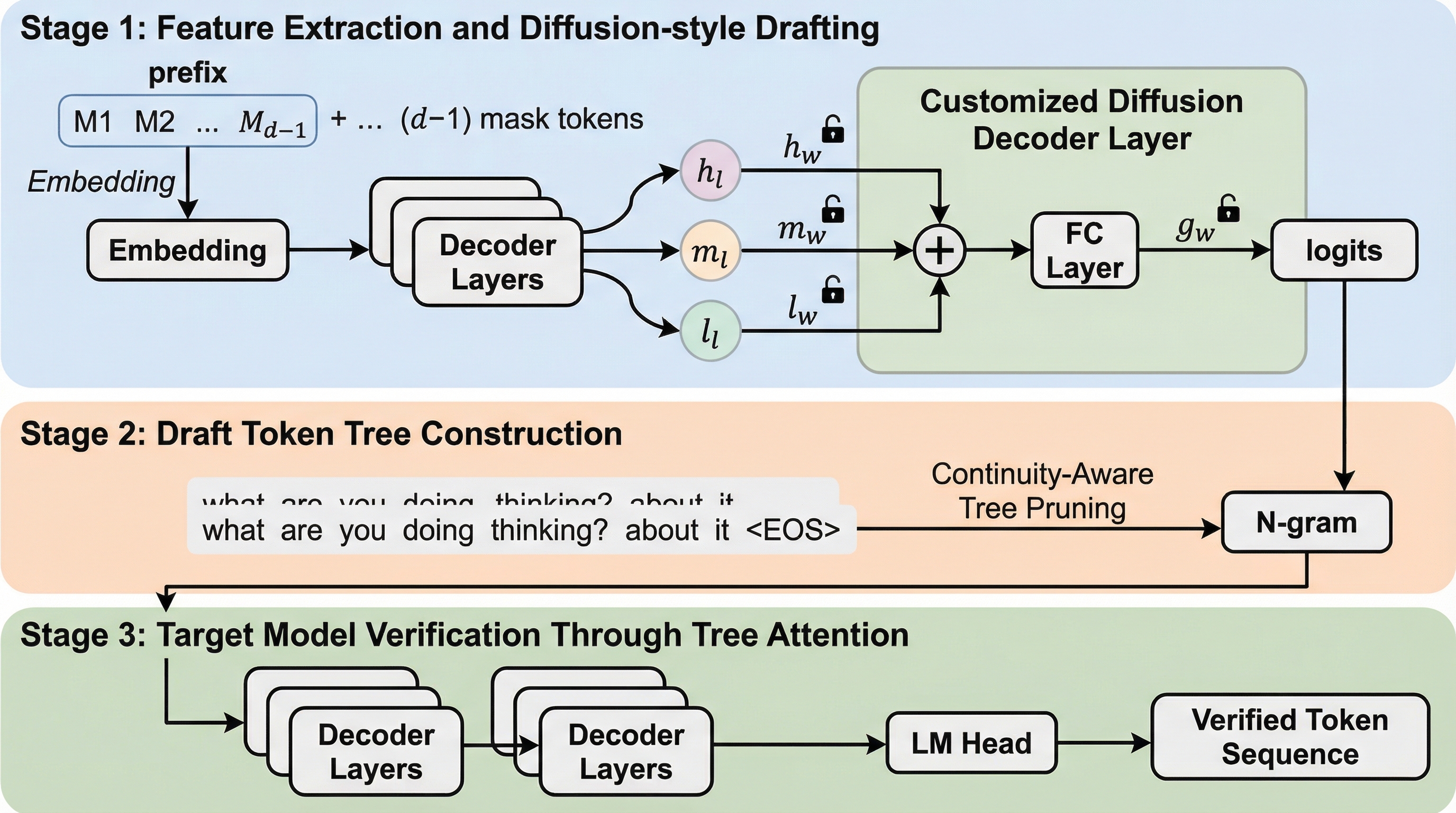
大規模言語モデル(LLM)の推論を高速化する手法として、投機的デコーディングは非常に有力なアプローチですが、実用化において「ドラフト作成のオーバーヘッド」という大きな壁に直面しています。この手法は、軽量なドラフトモデルが先に複数のトークンを予測し、それを巨大なターゲットモデルが一括で検証することで、1ステップあたりの生成トークン数を増やす仕組みです。しかし、EAGLE3に代表される既存の高精度なドラフトモデルは、それ自体が自己回帰的にトークンを1つずつ生成するため、ドラフト作成段階で無視できない遅延が発生します。具体的には、Qwen3-1.7BをドラフトモデルとしてQwen3-14Bや32Bを加速させる場合、推論時間全体の60%から75%がドラフト作成に費やされることがあり、ドラフト工程そのものが新たなボトルネックとなっています。一方で、N-gramや検索ベースの手法はドラフト作成の遅延こそ小さいものの、予測精度が低いためにターゲットモデルでの承認率が上がらず、十分な加速効果が得られません。…
核心:何を提案したのか
本研究では、拡散モデルの並列予測能力に着想を得つつ、投機的デコーディングの制約に最適化された新しいフレームワーク「DART」を提案しました。DARTの核心的なアイデアは、自己回帰的なロールアウトを完全に排除し、単一のフォワードパスで複数の未来のトークンに対するロジットを並列に予測することにあります。これにより、ドラフトの長さに関わらずドラフト作成の遅延を一定かつ極めて低く抑えることが可能になりました。DARTは、ターゲットモデルと密に結合した非常に軽量な設計を採用しています。具体的には、ターゲットモデルの中間層から得られる隠れ状態を再利用し、その上にカスタマイズされた単一のトランスフォーマーデコーダー層を追加するだけで構成されています。この設計により、ドラフトモデルを独立して動かす場合の計算コストや、トークナイザーの不一致といった実務上の問題を回避しています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related