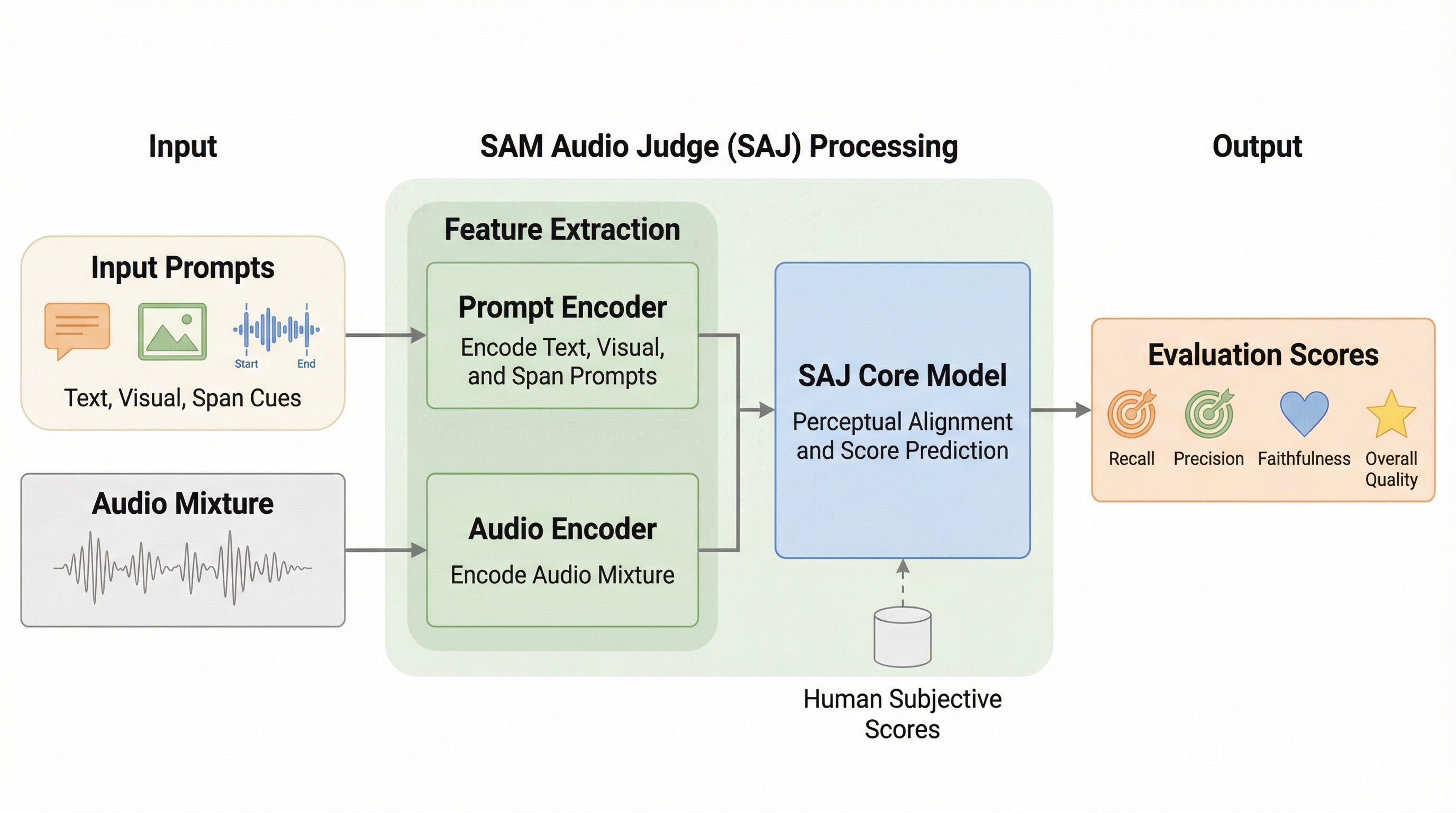
SAM Audio Judge:音源分離の知覚的評価のための統合マルチモーダルフレームワーク
従来の音源分離評価で主流だったSDRなどの指標は、正解信号への依存や人間の知覚との乖離という大きな課題を抱えていましたが、本研究では正解信号を必要とせず、人間の知覚と高度に一致する新しい客観的評価指標「SAM Audio Judge(SAJ)」を開発しました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
従来の音源分離評価で主流だったSDRなどの指標は、正解信号への依存や人間の知覚との乖離という大きな課題を抱えていましたが、本研究では正解信号を必要とせず、人間の知覚と高度に一致する新しい客観的評価指標「SAM Audio Judge(SAJ)」を開発しました。
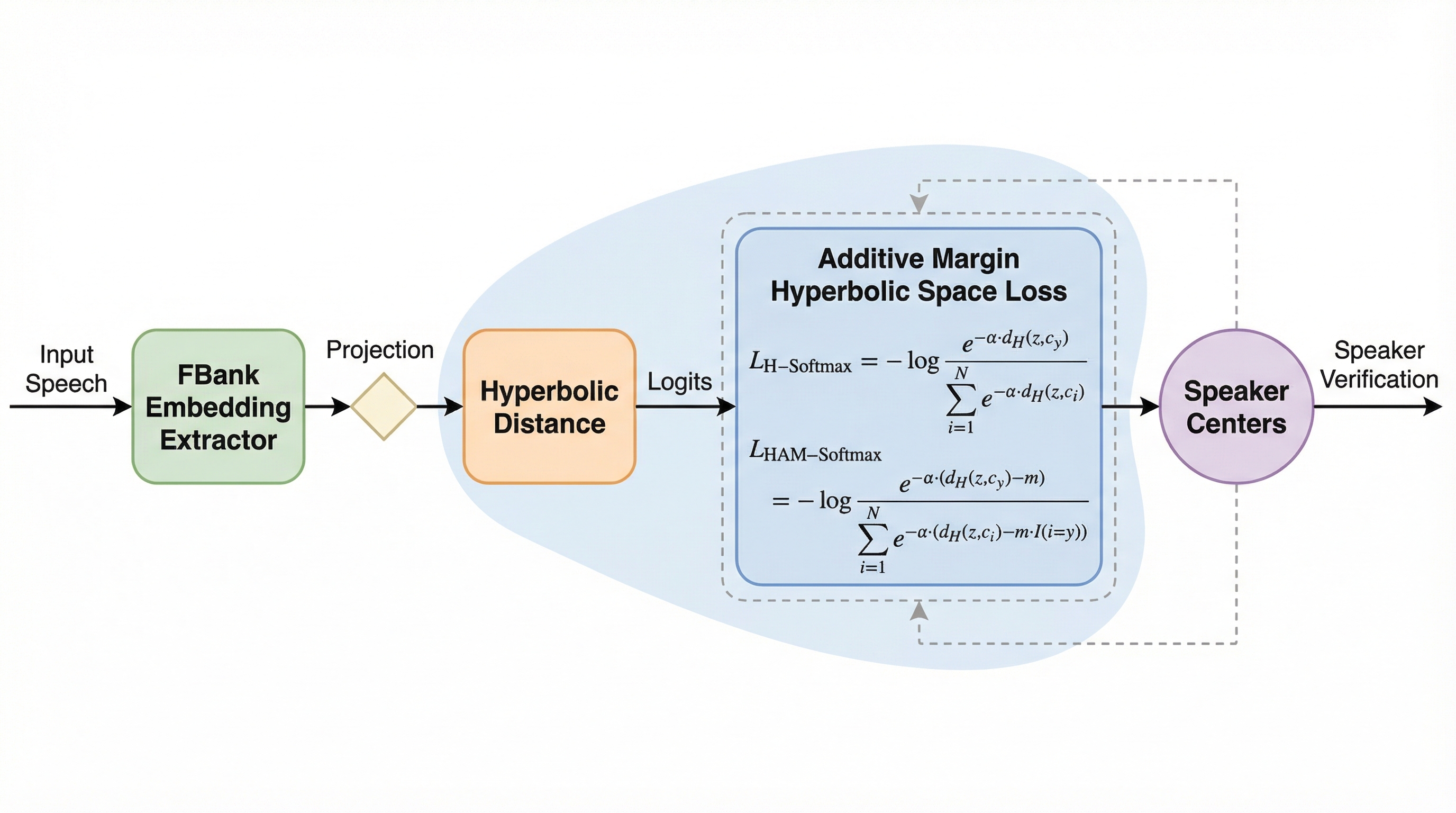
従来の話者照合はユークリッド空間での学習が主流であったが、基本周波数やフォルマント構造といった話者特徴が持つ木構造のような階層的な情報を十分に表現できないという課題があった。本研究では、負の曲率を持ち有限の体積内で指数関数的なデータ配置が可能な双曲空間(ポアンカレ球モデル)を導入し、階層構造を効率的にモデル化するH-Softmaxと、クラス間の分離性を高めるマージン制約を加えたHAM-Softmaxを提案した。実験の結果、VoxCelebやCNCeleb等のデータセットにおいて、従来のSoftmaxやAM-Softmaxと比較して等価誤り率(EER)を大幅に削減することに成功し、特に複雑なクロスドメインデータにおいて高い性能と階層情報の保持能力を示した。
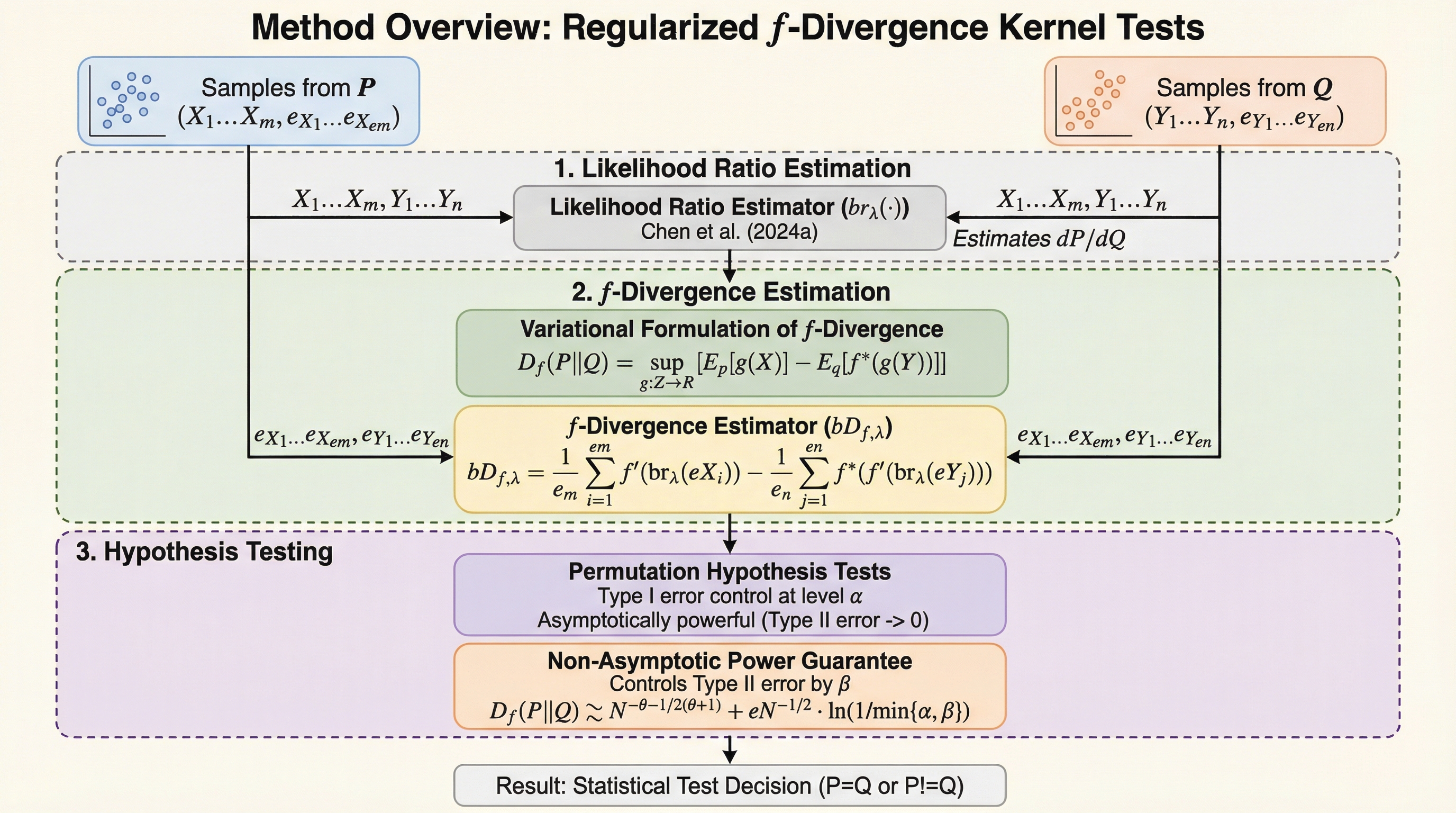
本研究は、$f$-ダイバージェンスの族に基づく新しいカーネル二標本検定の枠組みを提案し、正則化された変分表現とカーネル法による尤度比推定を組み合わせることで、多様な分布間の差異を統計的に検出可能にしました。
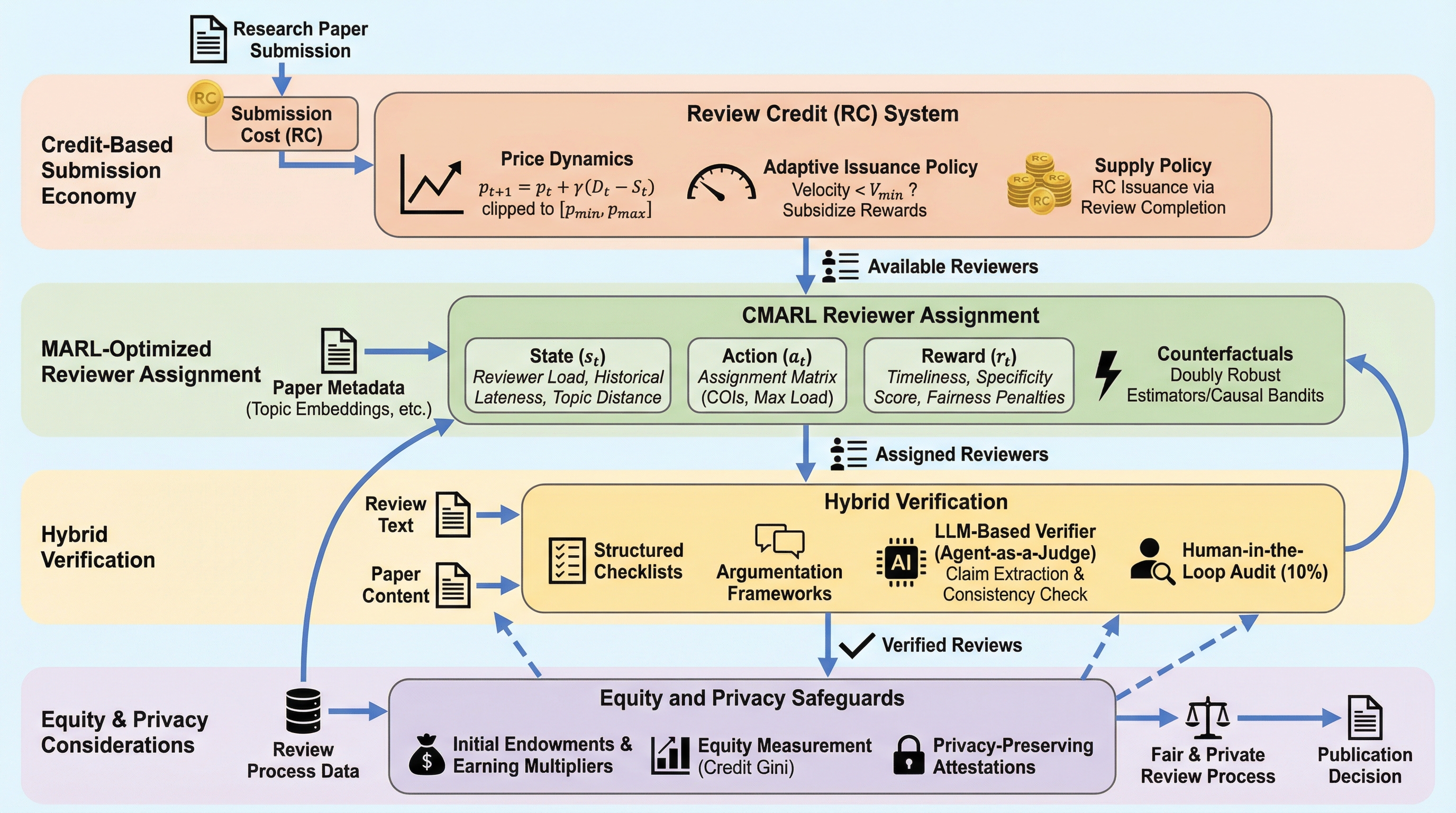
現在の学術論文査読システムは、投稿数の急増と査読者のインセンティブ不一致により「共有地の悲劇」に直面しており、査読結果の不一致や大規模言語モデル(LLM)による質の低下が深刻な問題となっています。
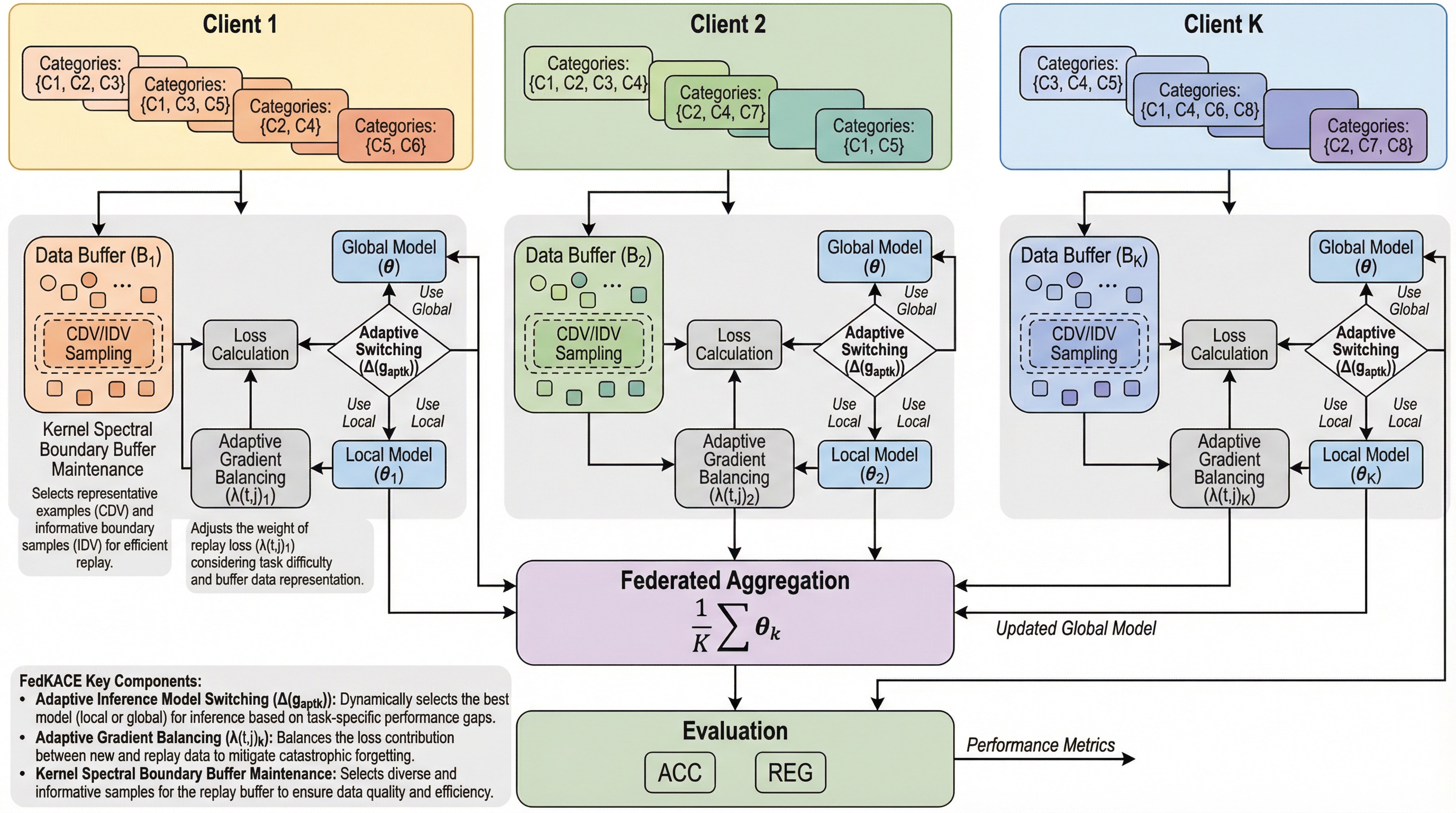
連合学習において、データが連続的に流入し、かつ新旧データ間でカテゴリが重複しながらもタスクの境界を示す識別子(タスクID)が存在しないという、極めて実世界に近い「ストリーミング連合継続学習」の設定を定義し、その特有の課題である知識の混乱や忘却の問題を明確化しました。
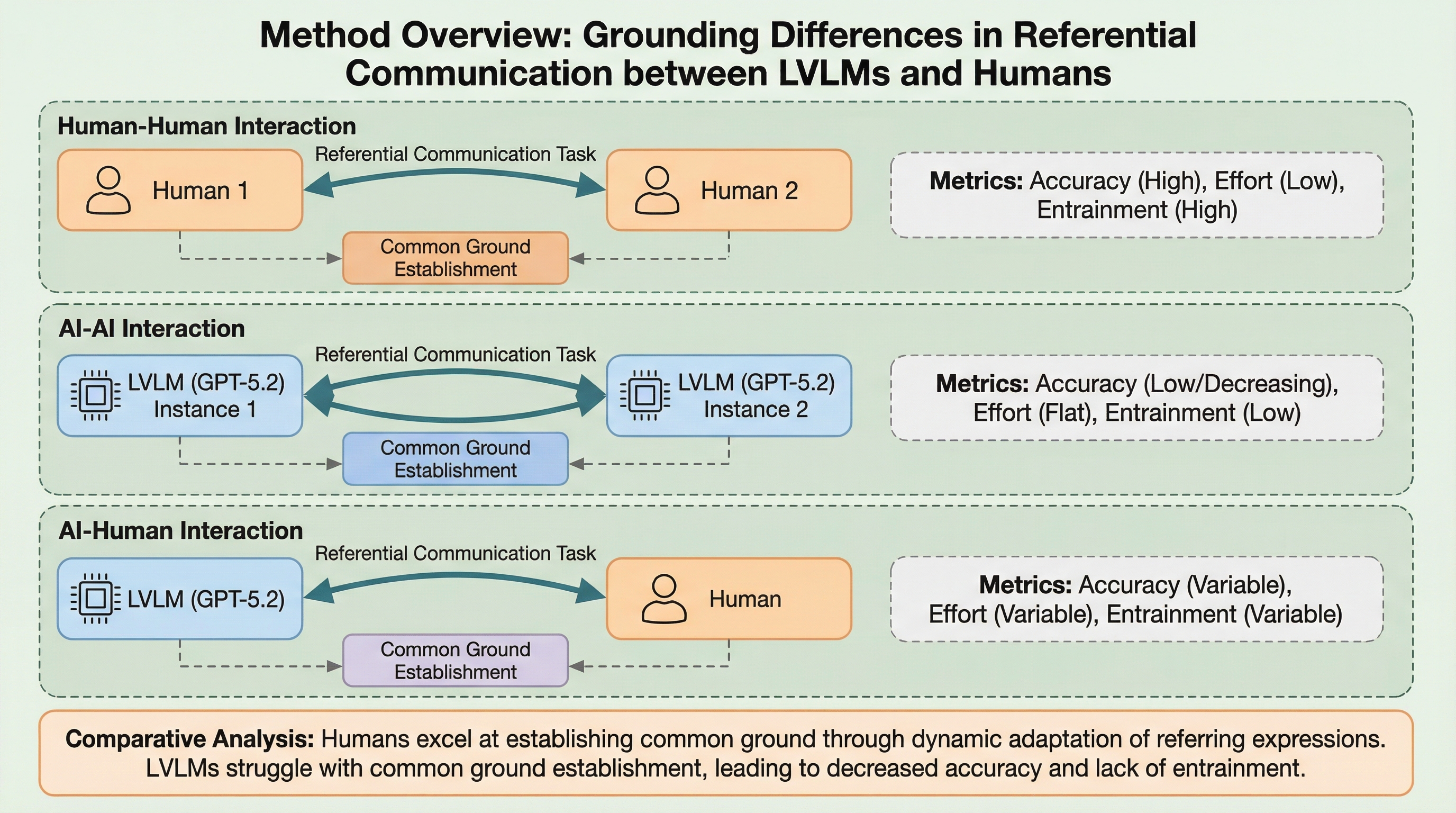
生成AIエージェントが人間と効果的に協力するには意図の予測が不可欠ですが、現在の大型視覚言語モデル(LVLM)は「共通基盤(コモングラウンド)」を構築する能力が欠如していることが明らかになりました。
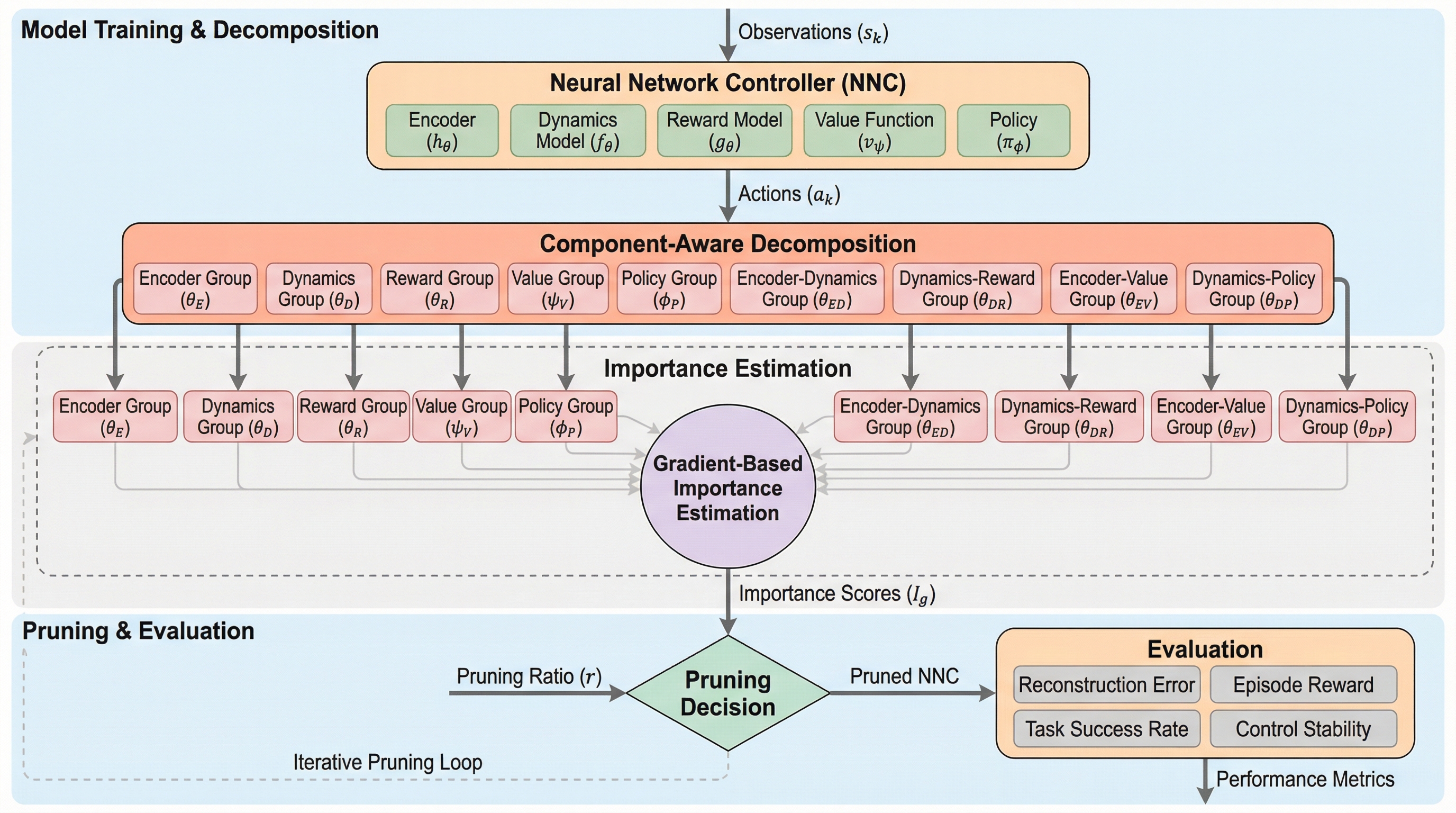
従来のニューラルネットワーク制御器の圧縮手法は、重みの絶対値に基づく静的な指標に依存しており、複数のコンポーネント間の複雑な依存関係や機能的な重要性を十分に考慮できていないため、過酷な圧縮条件下で制御性能や安定性が著しく低下するという課題がありました。
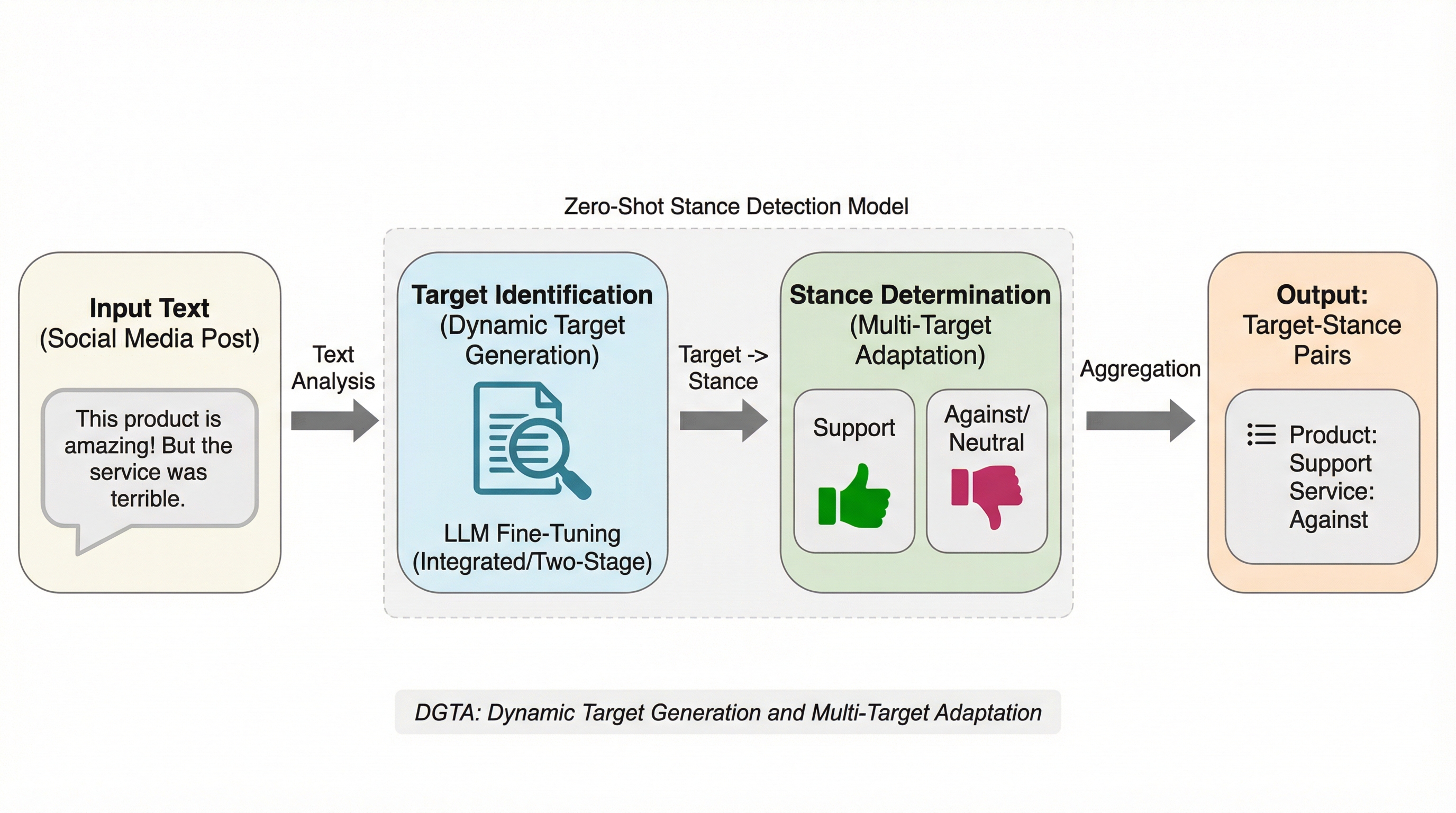
従来の立場検出はあらかじめ定義されたターゲットに依存していましたが、現実のソーシャルメディアではターゲットが動的で複雑であるため、未知のターゲットを自動特定し立場を判定する新タスク「DGTA」が提案されました。
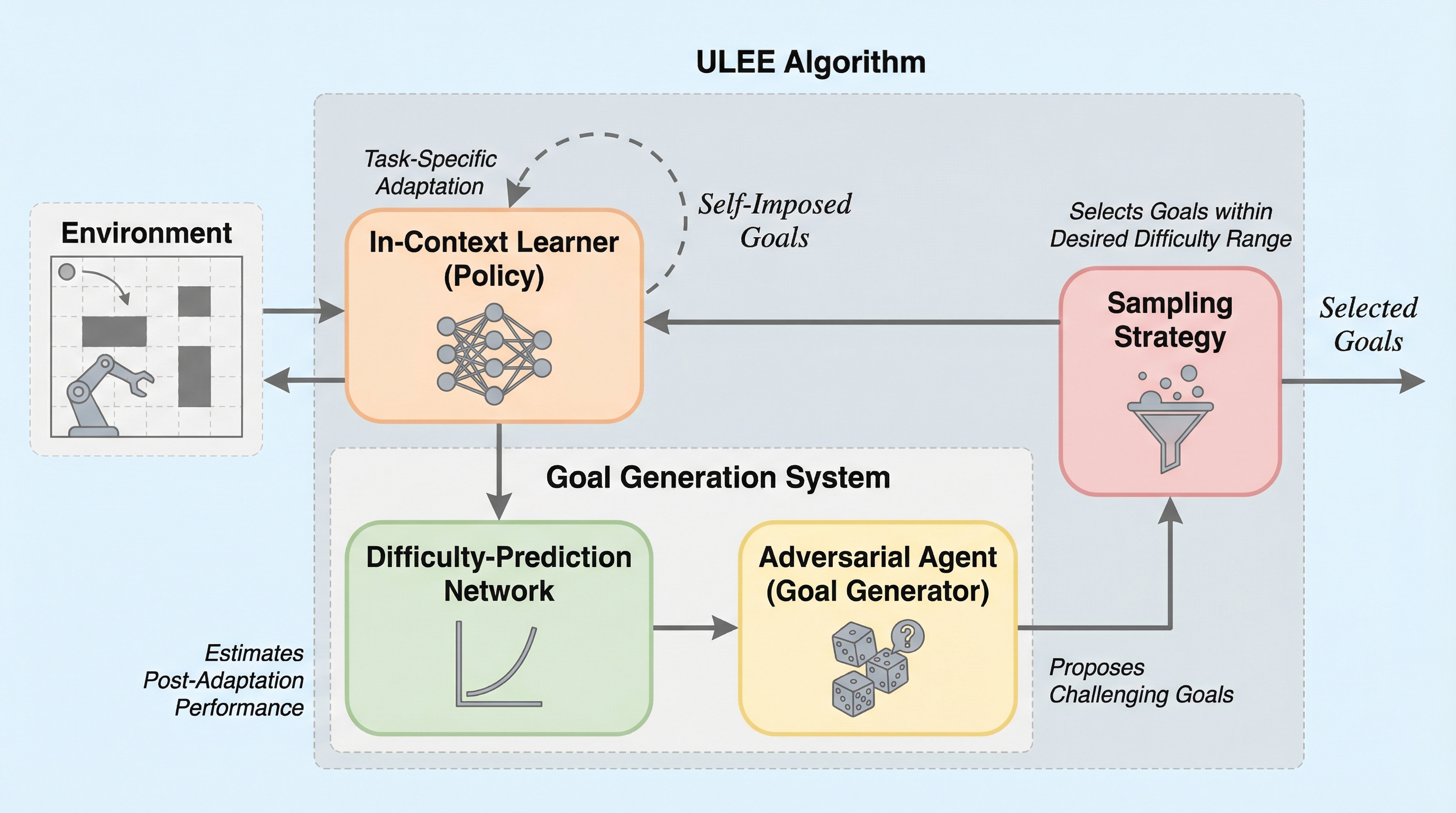
本研究は、外部報酬のない環境でエージェントが自律的に目標を設定し、効率的な探索と適応能力を習得するための教師なしメタ学習フレームワーク「ULEE」を提案しました。 従来の「現在の達成しやすさ」に基づくカリキュラムとは異なり、ULEEは「一定期間の適応後に達成可能な性能」を予測し、能力の境界にある適切な難易度の目標を敵対的に生成する仕組みを導入しています。 検証の結果、ULEEで事前学習されたエージェントは、未知の目的や環境構造、動特性に対しても優れた適応能力を示し、従来の学習手法を大幅に上回る汎用性を実証しました。
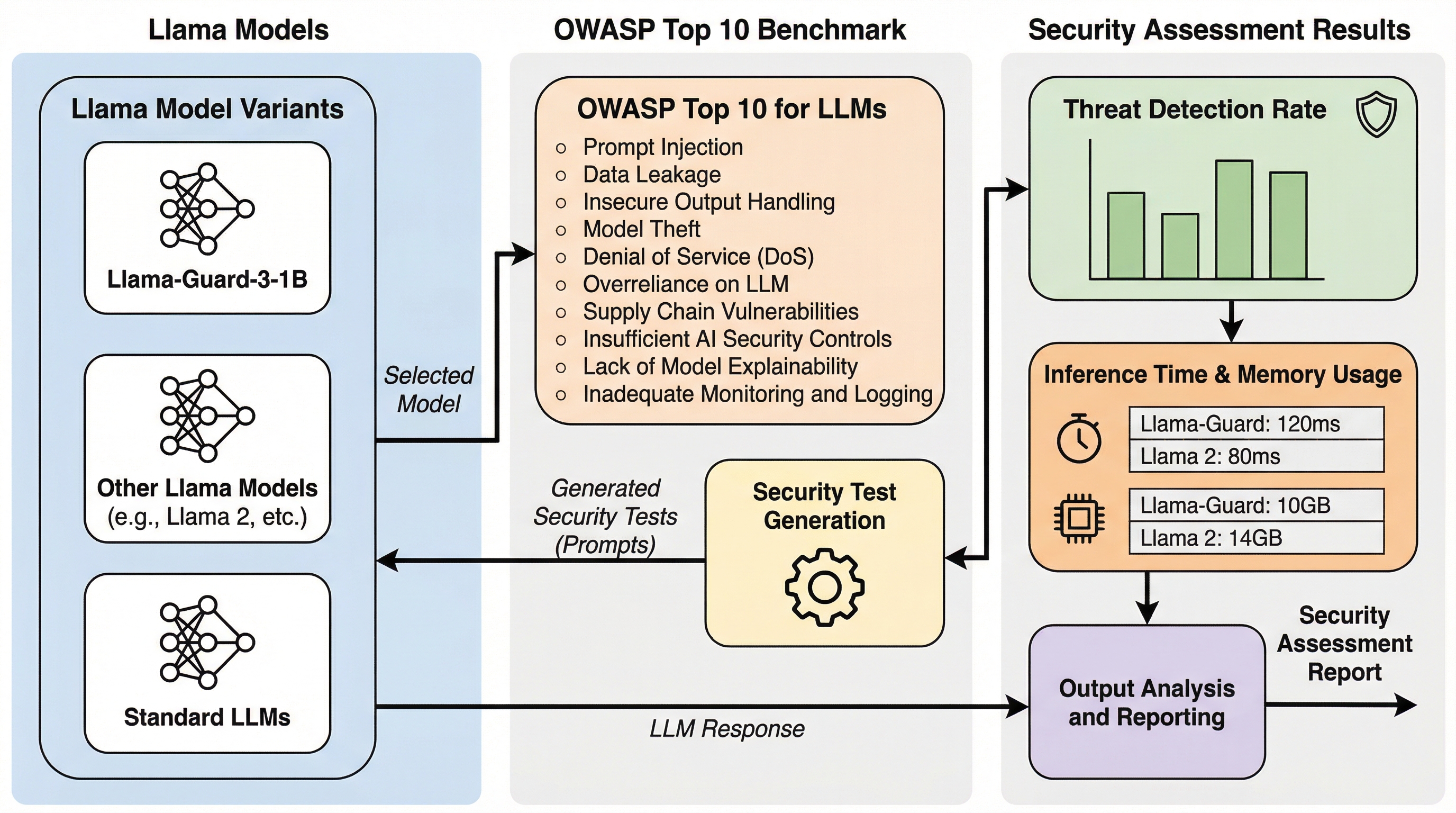
本研究では、Llamaモデルの多様なバリアントをOWASP Top 10フレームワークに基づき評価した結果、最小クラスのLlama-Guard-3-1Bが76%という最高の検知率を記録し、推論時間0.165秒、VRAM使用量0.94GBという極めて高い効率性を示した。 一方で、Llama-3.