LVLMと人間における参照的コミュニケーションの基盤化(グラウンディング)の違い
生成AIエージェントが人間と効果的に協力するには意図の予測が不可欠ですが、現在の大型視覚言語モデル(LVLM)は「共通基盤(コモングラウンド)」を構築する能力が欠如していることが明らかになりました。
TL;DR(結論)
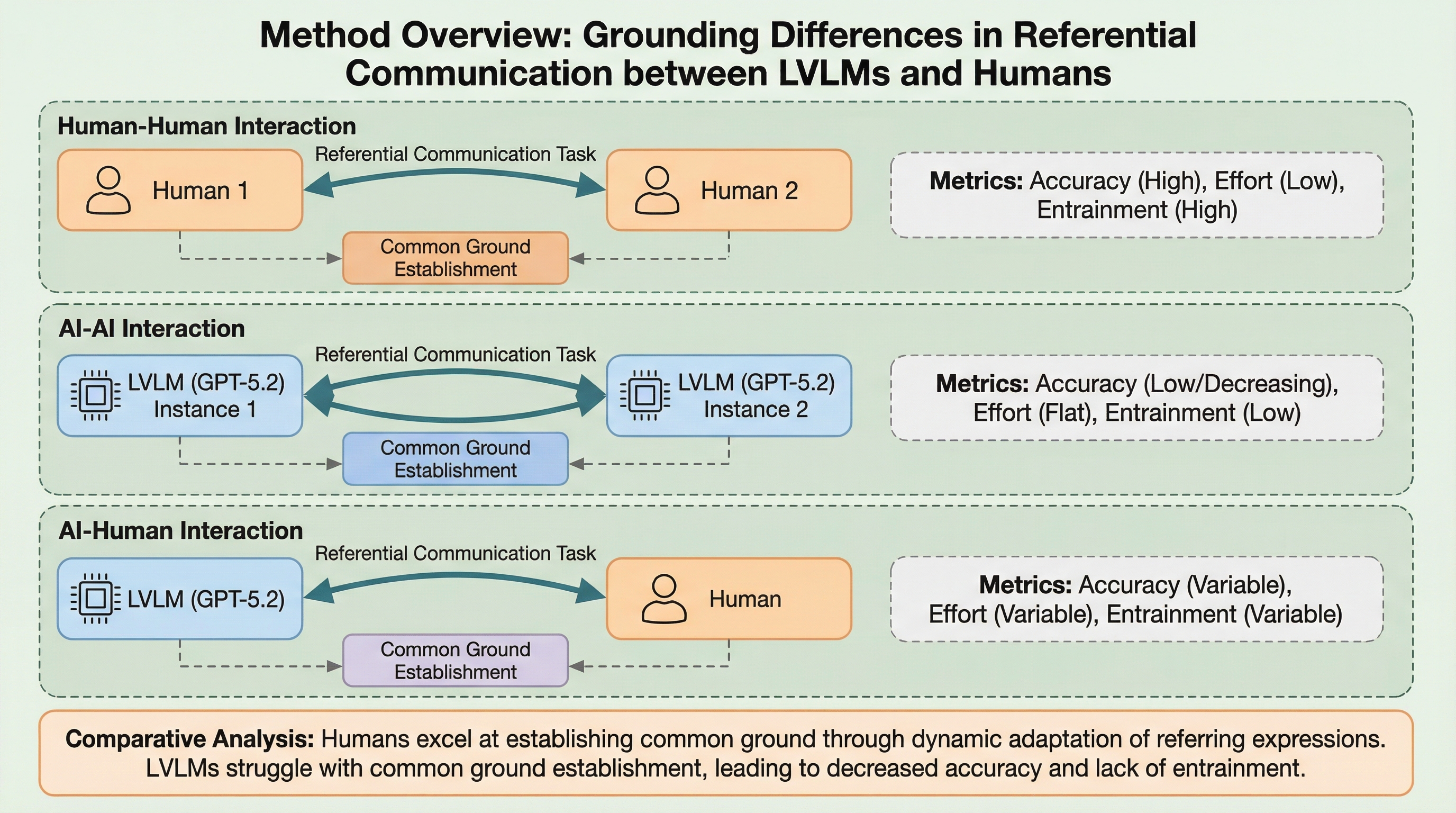
生成AIエージェントが人間と効果的に協力するには意図の予測が不可欠ですが、現在の大型視覚言語モデル(LVLM)は「共通基盤(コモングラウンド)」を構築する能力が欠如していることが明らかになりました。 本研究では人間とAIの様々な組み合わせによる参照的コミュニケーション実験を行い、人間が回数を重ねるごとに表現を簡略化し効率を高める一方で、AIは過剰に饒舌で相互理解の修復が困難であることを示しました。 収集された356の対話データを含むコーパスは、LVLMが対話を通じて参照表現を解決する際の限界を浮き彫りにしており、今後のAIの協調性向上に向けた重要なベンチマークとなります。
なぜこの問題か
人間同士の会話は、相互に情報を更新し積み上げていく「共通基盤」の構築に依存しています。会話のパートナーは、特定の物体を指し示す際、お互いが理解できる表現へと適応させていくプロセス(語彙的同調)を通じて、意味を共同で構築します。このプロセスは、単に既存の言葉の意味に頼るだけでなく、明確な名前のない物体に対しても、対話を通じて新しい概念的な合意を形成することを可能にします。しかし、現在の大型言語モデル(LLM)や大型視覚言語モデル(LVLM)が、人間のようにこの基盤化(グラウンディング)を行えるかどうかは、AIが人間のパートナーとして実用的な支援を行う上で極めて重要な課題です。 これまでの研究では、LVLMはパートナーと調整するための語用論的な能力が不足しており、複数ターンの会話において苦労することが示唆されてきました。特に、視覚的な環境から特定の要素を選択するタスクにおいて、AIがどのように失敗し、どの役割においてその欠陥が顕著になるのかを詳細に把握する必要があります。…
核心:何を提案したのか
本研究では、人間とAIのペアが協力して特定の物体を特定する「参照的コミュニケーションタスク」を用いた実験デザインを提案しました。この実験は、指示者(ディレクター)と照合者(マッチャー)という非対称な役割を持つペアが、複数ラウンドにわたって同じ物体のセットを識別するプロセスを観察するものです。具体的には、明確な語彙的ラベルを持たない「カゴ(バスケット)」の画像12枚を使用し、指示者がその特徴を説明し、照合者がそれを正しく並べるというタスクを設定しました。 この実験の最大の特徴は、人間とAI(GPT-5.2を使用)の組み合わせを、人間-人間(HH)、人間-AI(HA)、AI-人間(AH)、AI-AI(AA)の4つの条件ですべてテストした点にあります。これにより、AIが指示者の場合と照合者の場合のそれぞれで、どのような振る舞いの違いが生じるかを直接比較することが可能になりました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related