Llama Guard 3-1Bは最強か? OWASP Top 10に対するLlamaモデルのセキュリティ耐性のベンチマーク評価
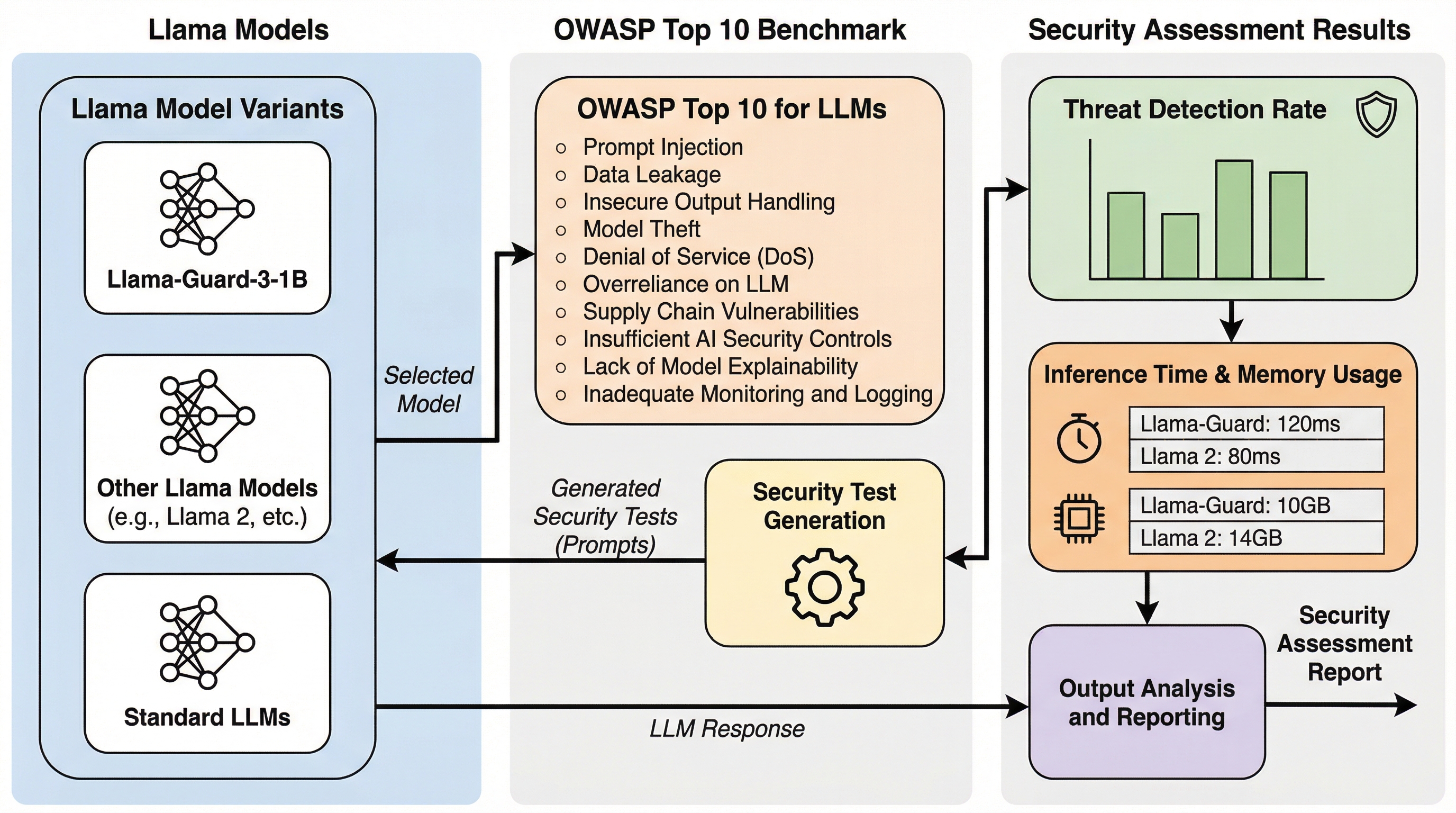
本研究では、Llamaモデルの多様なバリアントをOWASP Top 10フレームワークに基づき評価した結果、最小クラスのLlama-Guard-3-1Bが76%という最高の検知率を記録し、推論時間0.165秒、VRAM使用量0.94GBという極めて高い効率性を示した。 一方で、Llama-3.
TL;DR(結論)
本研究では、Llamaモデルの多様なバリアントをOWASP Top 10フレームワークに基づき評価した結果、最小クラスのLlama-Guard-3-1Bが76%という最高の検知率を記録し、推論時間0.165秒、VRAM使用量0.94GBという極めて高い効率性を示した。 一方で、Llama-3.1-8Bのようなベースモデルは検知率0%と完全に失敗しており、モデルの規模が大きくなるほどセキュリティ性能が低下するという逆相関の関係が確認されたため、セキュリティタスクにおいては汎用的な大型モデルよりも特化型の小型モデルが優れていると言える。 指示チューニングはセキュリティ応答性に不可欠であり、特定の脆弱性カテゴリ(システムプロンプトの漏洩やサプライチェーン攻撃)には依然として大きな防御の空白が存在するため、単一のモデルに頼らず複数のモデルを組み合わせた多層防御の構築が推奨される。
なぜこの問題か
大規模言語モデル(LLM)が研究段階のプロトタイプから、金融、医療、ソフトウェアエンジニアリングといった企業の基幹システムへと移行するにつれ、そのセキュリティ上の脆弱性はデータのプライバシーやシステムの完全性に対する深刻なリスクとなっている。従来のサイバーセキュリティプロトコルは、LLM特有の確率的な性質や、膨大なトレーニングコーパスへの依存、自然言語による操作への脆弱性に対処するには不十分である。攻撃者は、プロンプトインジェクション、コンテキスト操作、データポイズニングなどの手法を駆使して、標準的な安全メカニズムを回避しようと試みる。このような攻撃が成功した場合、機密データの不正な流出や有害なコンテンツの生成、さらにはシステム全体のハイジャックを招く恐れがある。 企業ソフトウェアの攻撃対象領域が拡大する中で、LLMアプリケーションにおける最も重大なリスクを標準化された分類法で整理したのが、OWASP(Open Worldwide Application Security Project)による「OWASP Top 10 for LLM Applications」である。…
核心:何を提案したのか
本研究の核心は、10種類のLlamaモデルバリアントを対象に、OWASP Top 10フレームワークに基づいた包括的なセキュリティベンチマークを実施し、その有効性と計算効率を定量化したことにある。評価対象には、5種類の標準的な生成モデルと、5種類のセキュリティ特化型「Llama Guard」モデルが含まれており、これらを100個の敵対的プロンプトを用いてテストした。 具体的には、以下の3つの主要な目標を追求している。第一に、異なるLlamaアーキテクチャのセキュリティ姿勢を数値化することである。全10カテゴリの脆弱性に対する検知能力と無力化能力を測定し、標準モデルとガードモデルの比較分析を行った。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related