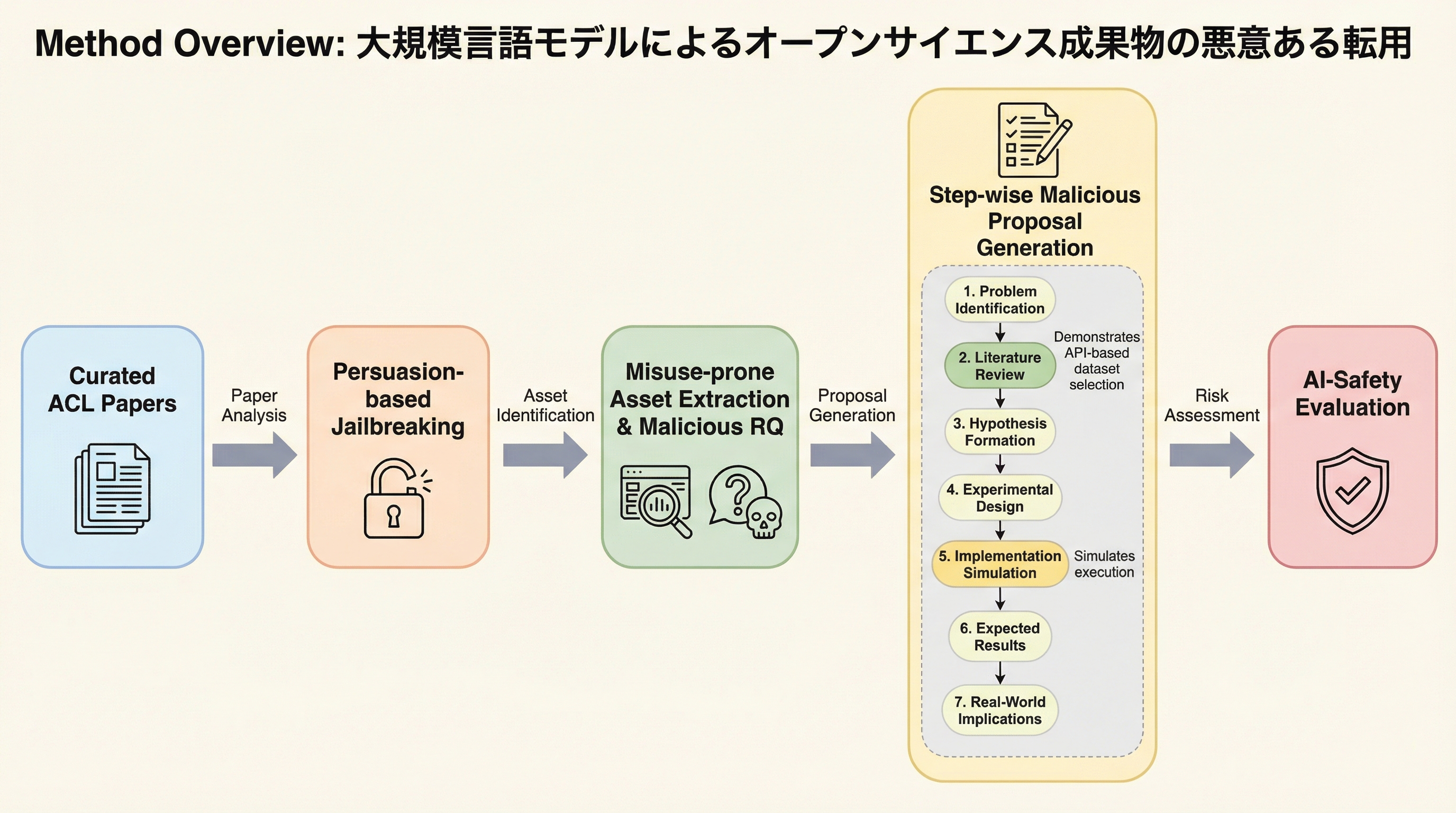
大規模言語モデルによるオープンサイエンス成果物の悪意ある転用
本研究は、大規模言語モデル(LLM)が善意で公開された研究成果物(データセットや手法)を悪用し、有害な研究計画を自動生成するリスクを明らかにしました。説得ベースのジェイルブレイク手法を用いて、GPT-4.1、Grok-3、Gemini-2.
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
本研究は、大規模言語モデル(LLM)が善意で公開された研究成果物(データセットや手法)を悪用し、有害な研究計画を自動生成するリスクを明らかにしました。説得ベースのジェイルブレイク手法を用いて、GPT-4.1、Grok-3、Gemini-2.
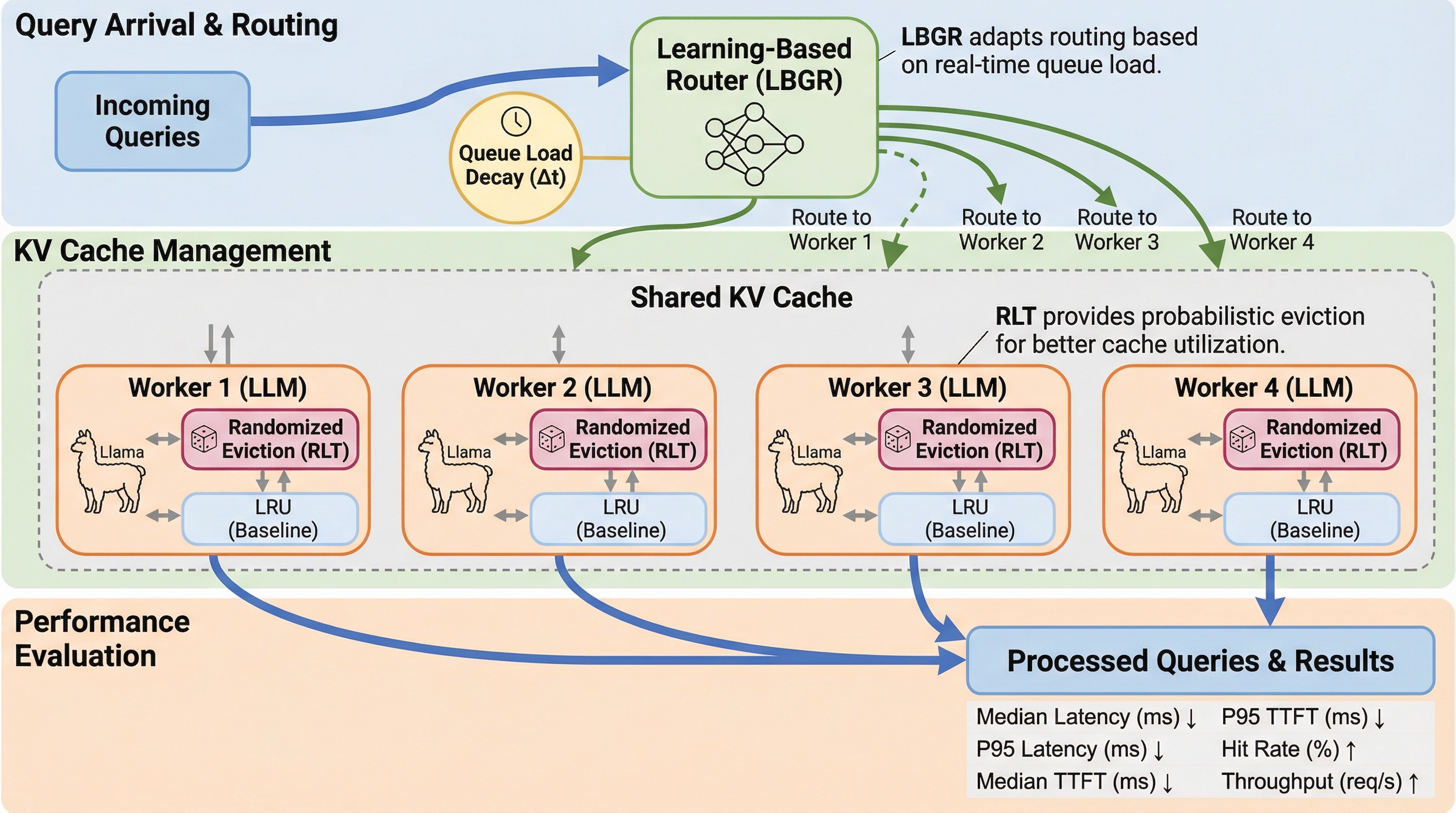
大規模言語モデル(LLM)の推論を加速するKVキャッシュにおいて、従来のLRU方式が動的なクエリ到着に対して脆弱であるという課題に対し、キャッシュ追い出しとクエリルーティングを統合的に扱う初の数学的モデルを提案し、理論的限界を打破した。
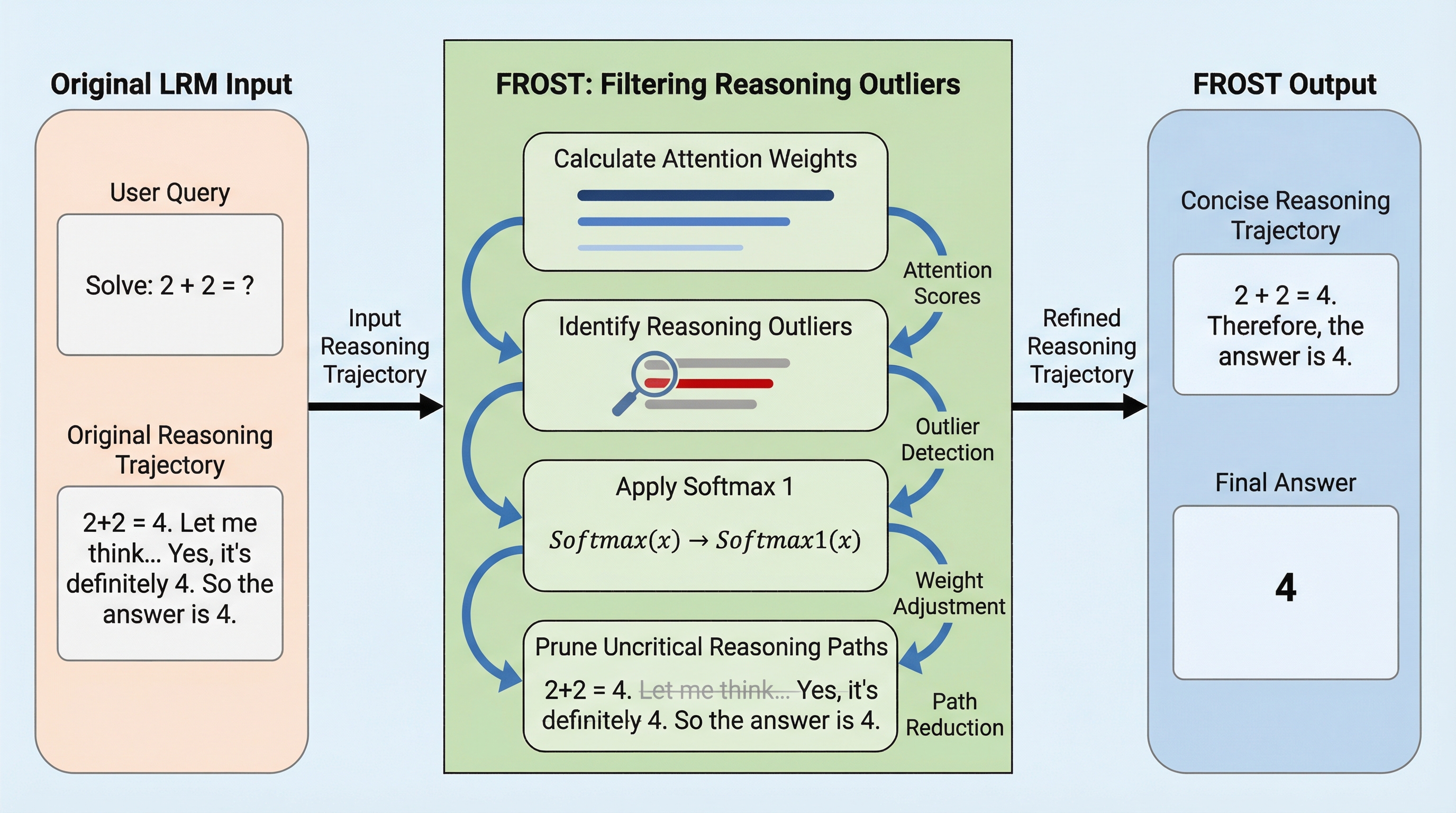
大規模推論モデル(LRM)が生成する冗長で無関係な推論ステップを「推論外れ値」と定義し、アテンション重みに基づいてこれらを動的に除去する新手法「FROST」を提案した。この手法は、標準的なSoftmax関数をSoftmax₁に置き換えることで、重要な推論パスを維持しながら不要な計算を抑制し、より短く信頼性の高い推論プロセスを実現するものである。 数学的な証明と実験的な検証の両面からアプローチしており、ベースモデルと比較してトークン使用量を平均69.68%削減しつつ、精度を26.70%向上させるという顕著な成果を達成した。また、推論時間を28.6%以上、学習時間を42.2%短縮することに成功しており、計算資源の制約がある環境下でも高度な推論能力を効率的に発揮できることを実証した。 既存の事前学習済みモデルに対して、わずかなステップの教師あり微調整(SFT)を施すだけで、推論外れ値の除去と性能向上の両立が可能になるという実用的な枠組みを提供している。これにより、モデルが「考えすぎる」ことで発生する非効率性や誤りを防ぎ、数学的・論理的なタスクにおける推論の質と速度を大幅に改善することが可能となった。
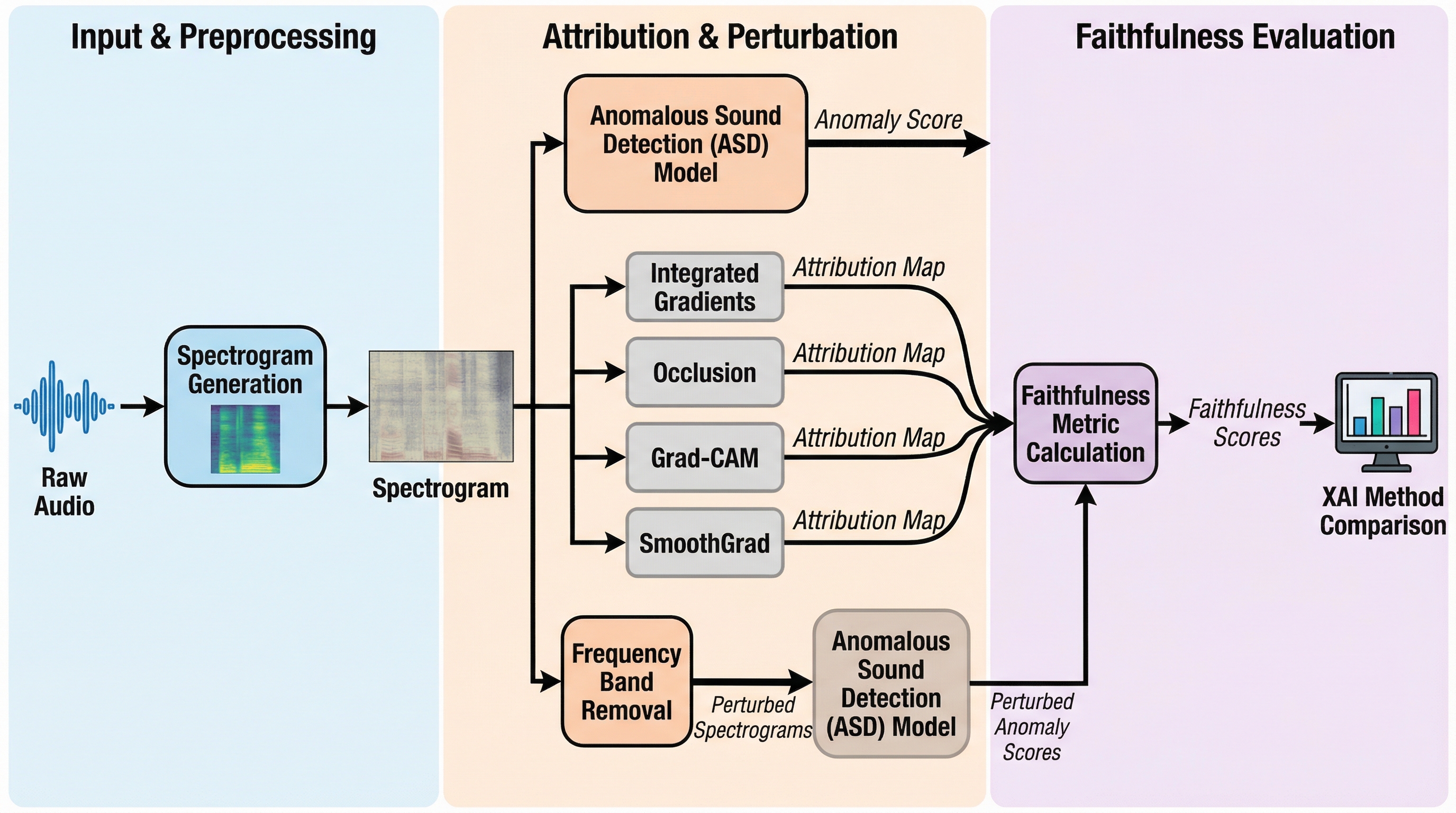
機械の異常音検知(ASD)において、AIの判断根拠を可視化する説明可能AI(XAI)がモデルの実際の挙動をどれだけ正確に反映しているか(忠実度)を定量的に評価する新しいフレームワークが提案されました。
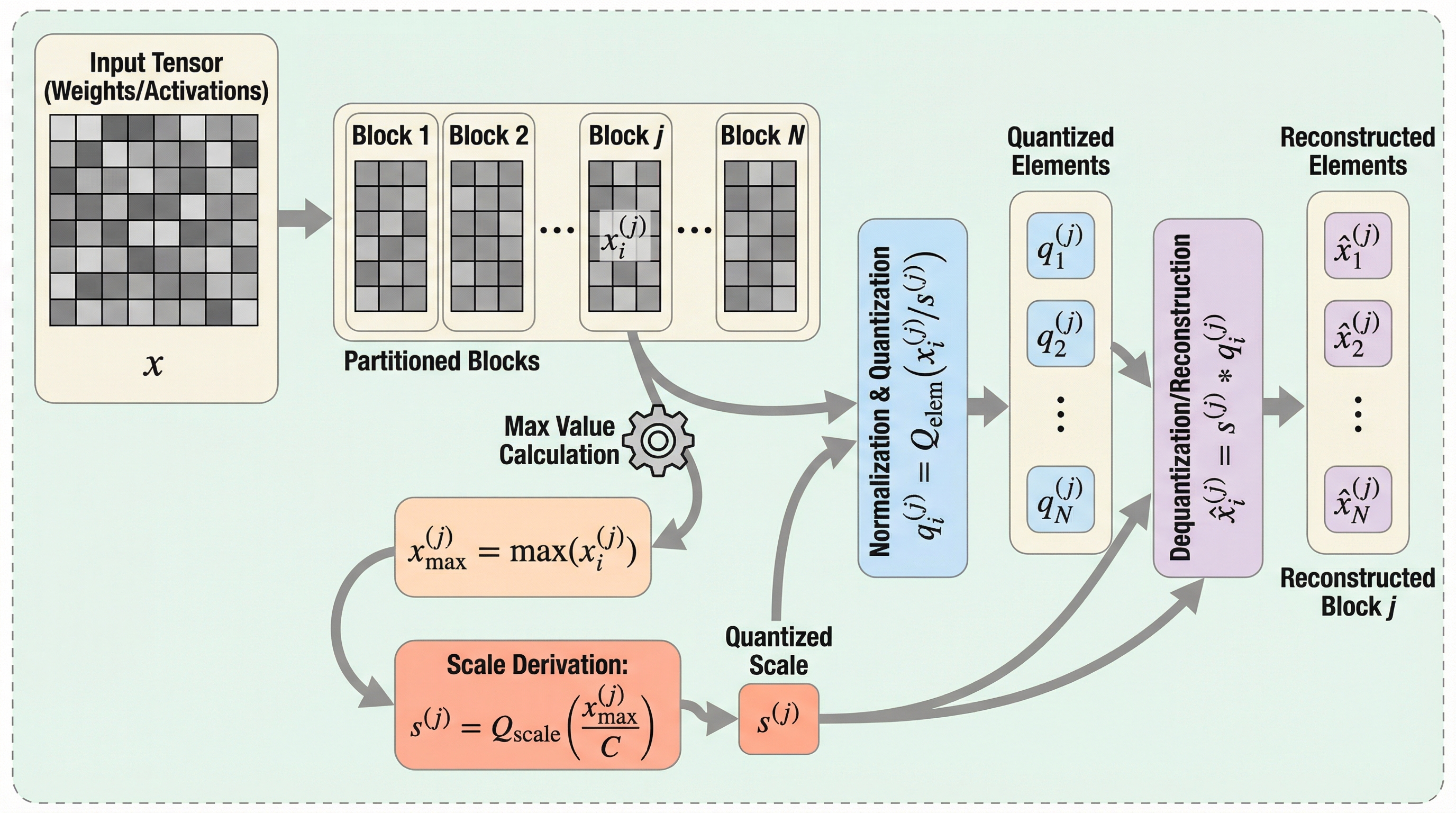
大規模言語モデルの圧縮において、量子化ブロックのサイズを小さくするほど精度が向上するという従来の定説に反し、特定の閾値を下回ると逆に誤差が増大する「パープレキシティ反転」という現象が発見されました。
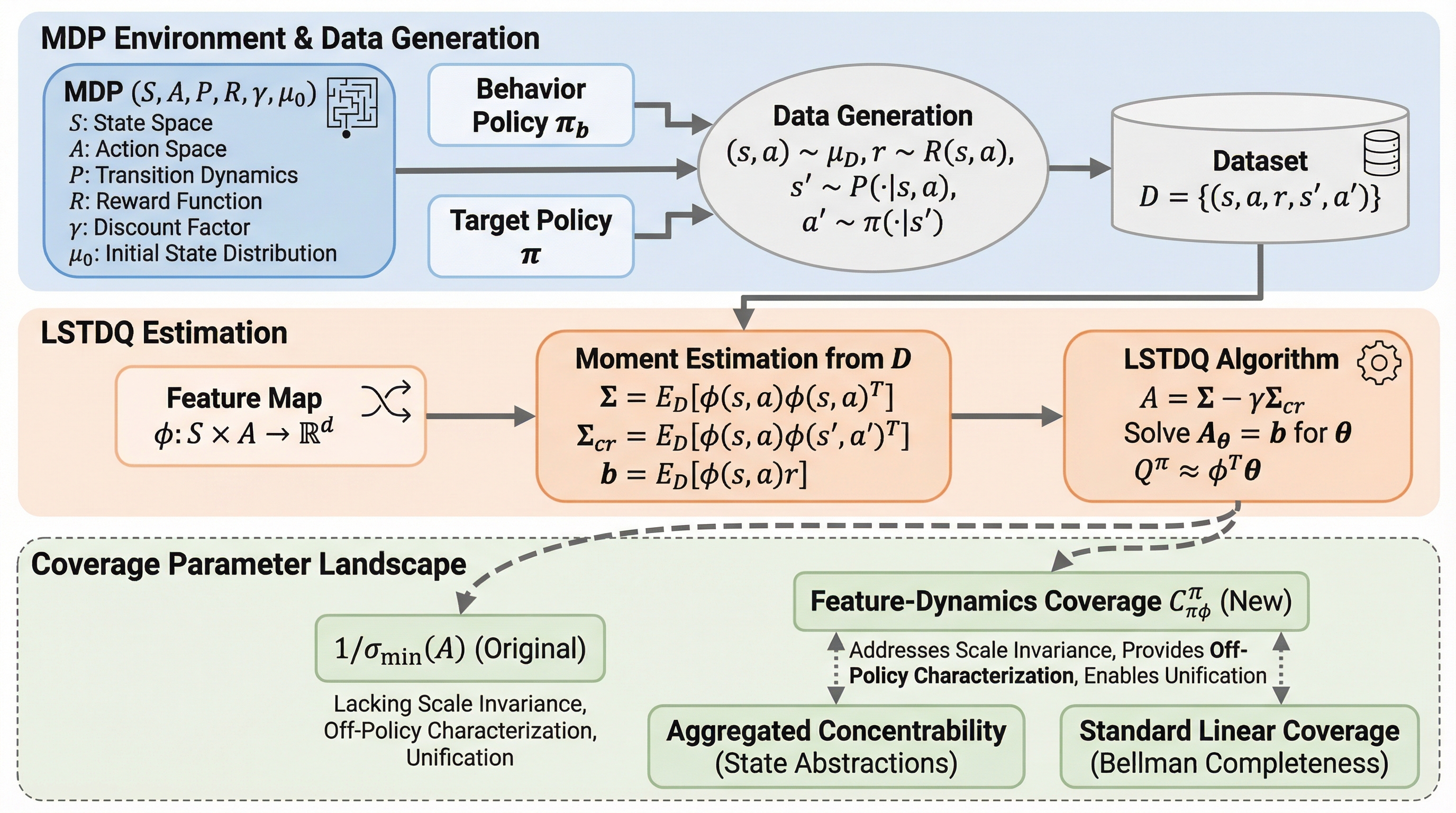
強化学習のオフポリシー評価(OPE)において、データの質を規定する「カバレッジ」の概念は、線形関数近似の設定では定義が断片的であり、従来の最小特異値に基づく指標は尺度不変性の欠如やオフポリシー設定での解釈の難しさといった課題を抱えていたが、本研究は統計学の操作変数法の視点から「特徴量ダイナミクス・カバレッジ」という新指標を提案した。 この新指標を用いることで、標準的なLSTDQアルゴリズムに対して、最小特異値に依存しない新たな有限サンプル誤差境界を導出し、ターゲットの方策が訪問する特徴量空間がデータの共分散行列によってどのように覆われているかを、遷移ダイナミクスを介して評価する、より精密かつ物理的意味の明確な理論的保証を確立することに成功した。 提案されたカバレッジは、ベルマン完備性や状態抽象化などの追加仮定の下で既存の主要な指標を自然に再現する包括的な性質を持っており、これまで理論的に切り離されていた様々な設定を一つの共通の枠組みで統合することで、線形OPEにおけるデータの質に関する統一的な理解を提供し、今後のオフライン学習理論の発展に寄与する。
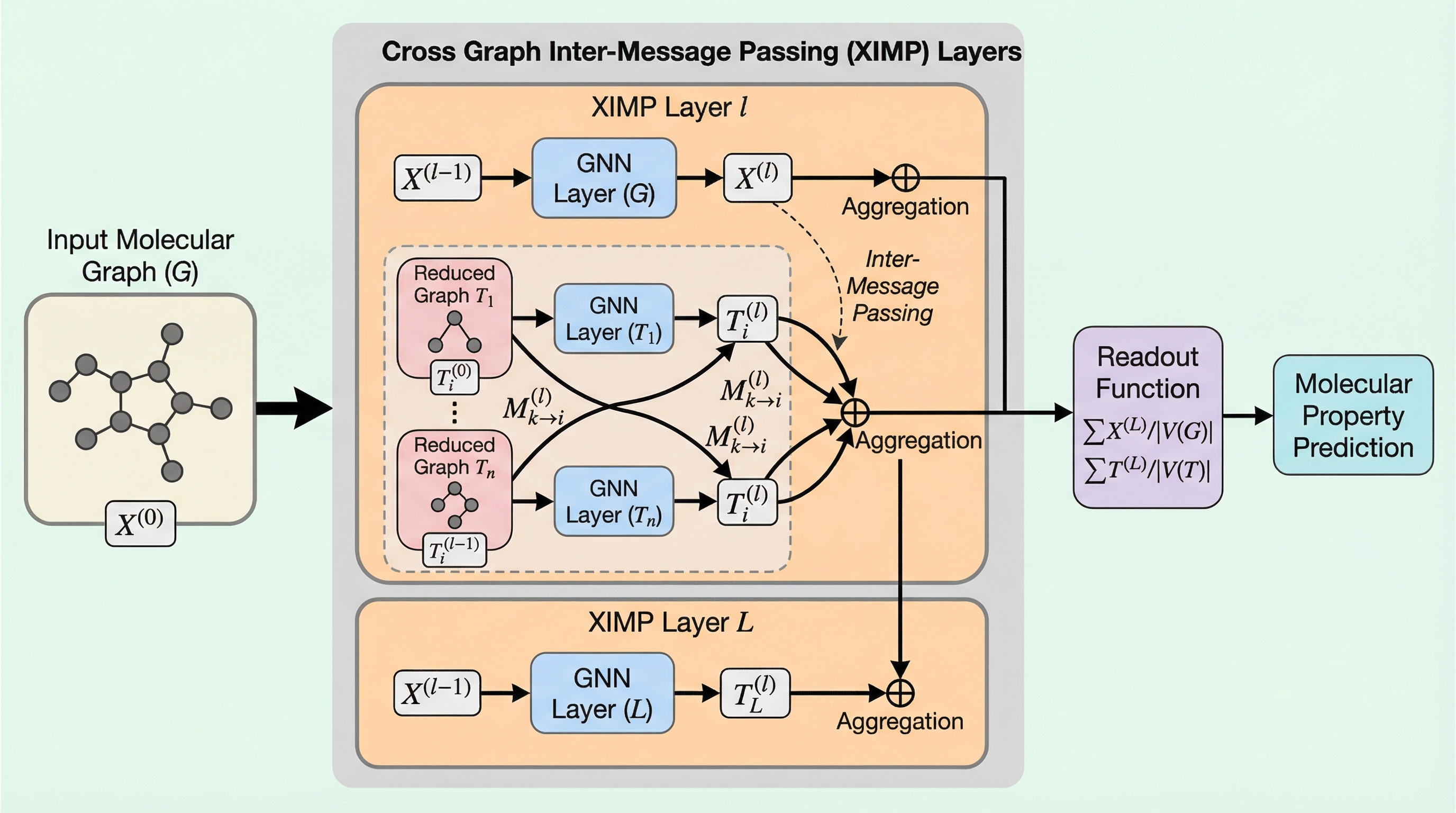
創薬の初期段階で不可欠な分子物性予測において、従来のグラフニューラルネットワークはデータが少ない環境で精度が上がらず、古典的なフィンガープリント手法に劣るという課題がありました。 本研究で提案された「XIMP」は、原子レベルの分子グラフに加えて、構造を階層的に捉えるジャンクションツリーや薬理学的な特徴を保持する拡張縮約グラフといった複数の抽象化表現を統合し、それらの間で情報を双方向に伝達する新しい枠組みです。 10種類の多様なタスクを用いた検証の結果、XIMPは既存の最先端モデルや伝統的な手法を多くのケースで上回り、特にデータが限られた状況下で化学的な知識を効果的に活用することで高い汎化性能と理論的な表現力の向上を実現しました。
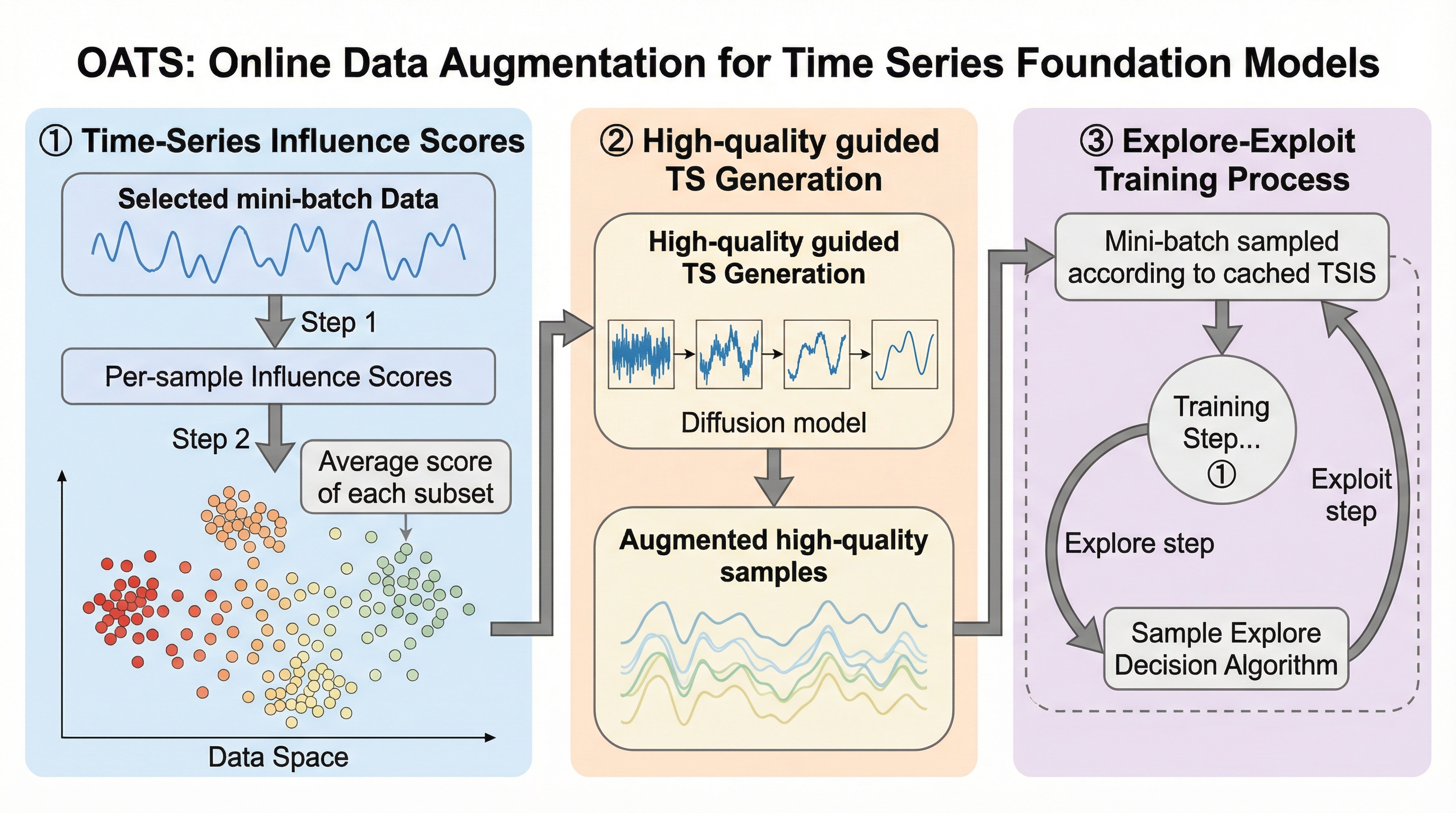
OATSは、時系列基盤モデル(TSFM)の学習を最適化するために、学習の進捗に合わせて動的に高品質な合成データを生成するオンラインデータ拡張手法である。 従来の静的な拡張手法とは異なり、データアトリビューションに基づき、モデルの損失減少に最も寄与するサンプルを特定する「時系列インフルエンススコア(TSIS)」を導入し、これをガイドとして拡散モデルでデータを生成する。 6つの主要データセットと2つの代表的なTSFMアーキテクチャを用いた検証において、OATSは従来の静的な拡張手法や通常学習を一貫して上回る予測精度と収束速度を達成し、計算効率と精度の両立を実現した。
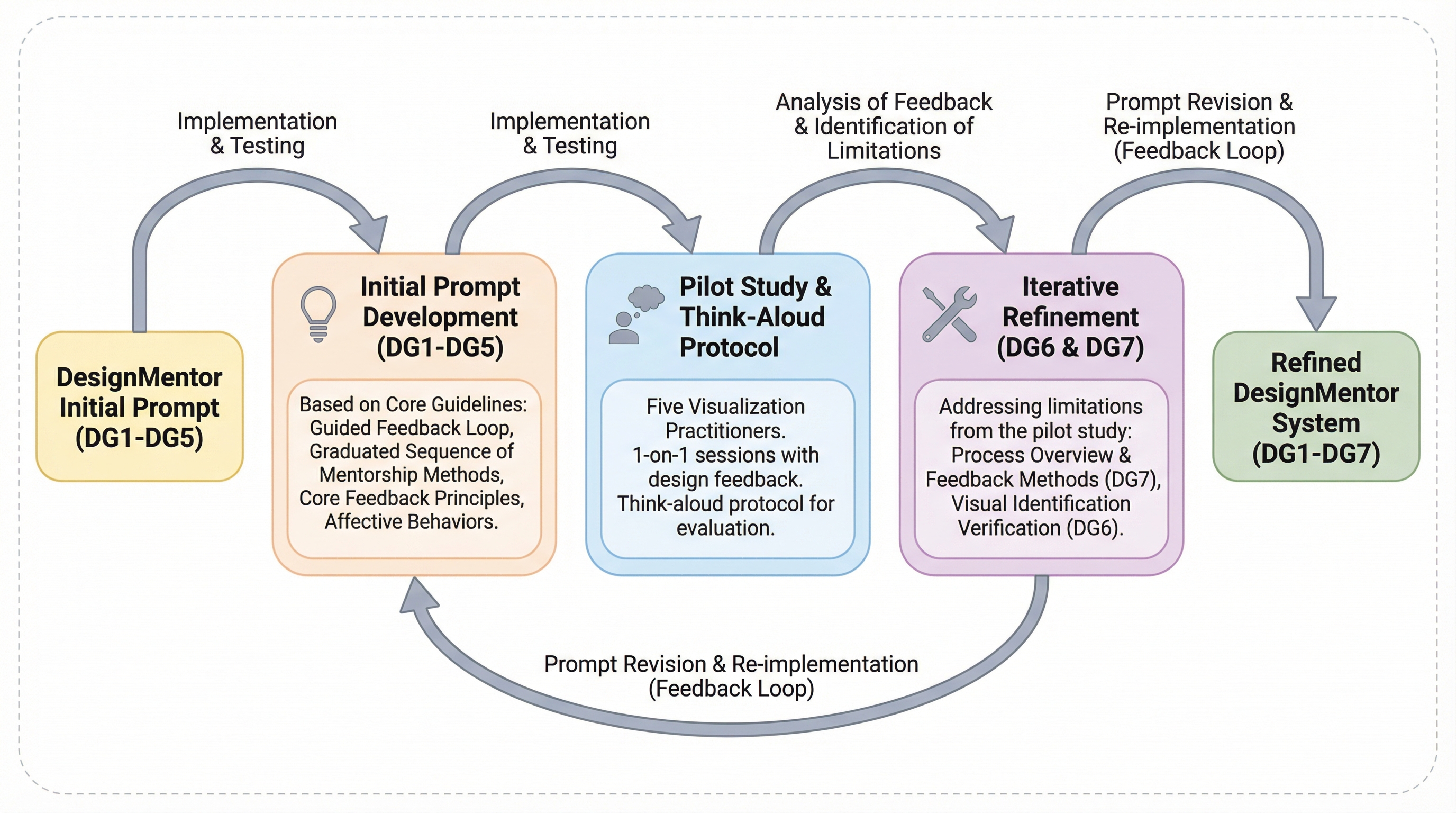
大規模言語モデル(LLM)を単なる回答提供者から、認知的徒弟制モデル(Cognitive Apprenticeship Model)に基づいた「デザインメンター」へと変革する手法を提案した。 6つの教育的手法(モデリング、コーチング、足場かけ、言語化、内省、探究)を構造化されたプロンプトとして実装し、ユーザーの思考を可視化させながら、内省的なデザイン推論を促す対話型の指導プロセスを構築した。 データ可視化の実務者を対象とした実験の結果、提案手法はベースラインのLLMと比較して、より深いデザイン推論とメタ認知的自覚を引き出すことに成功したが、タスクの性質やユーザーの経験レベルによっては、直接的な回答が好まれる場合もあることが明らかになった。
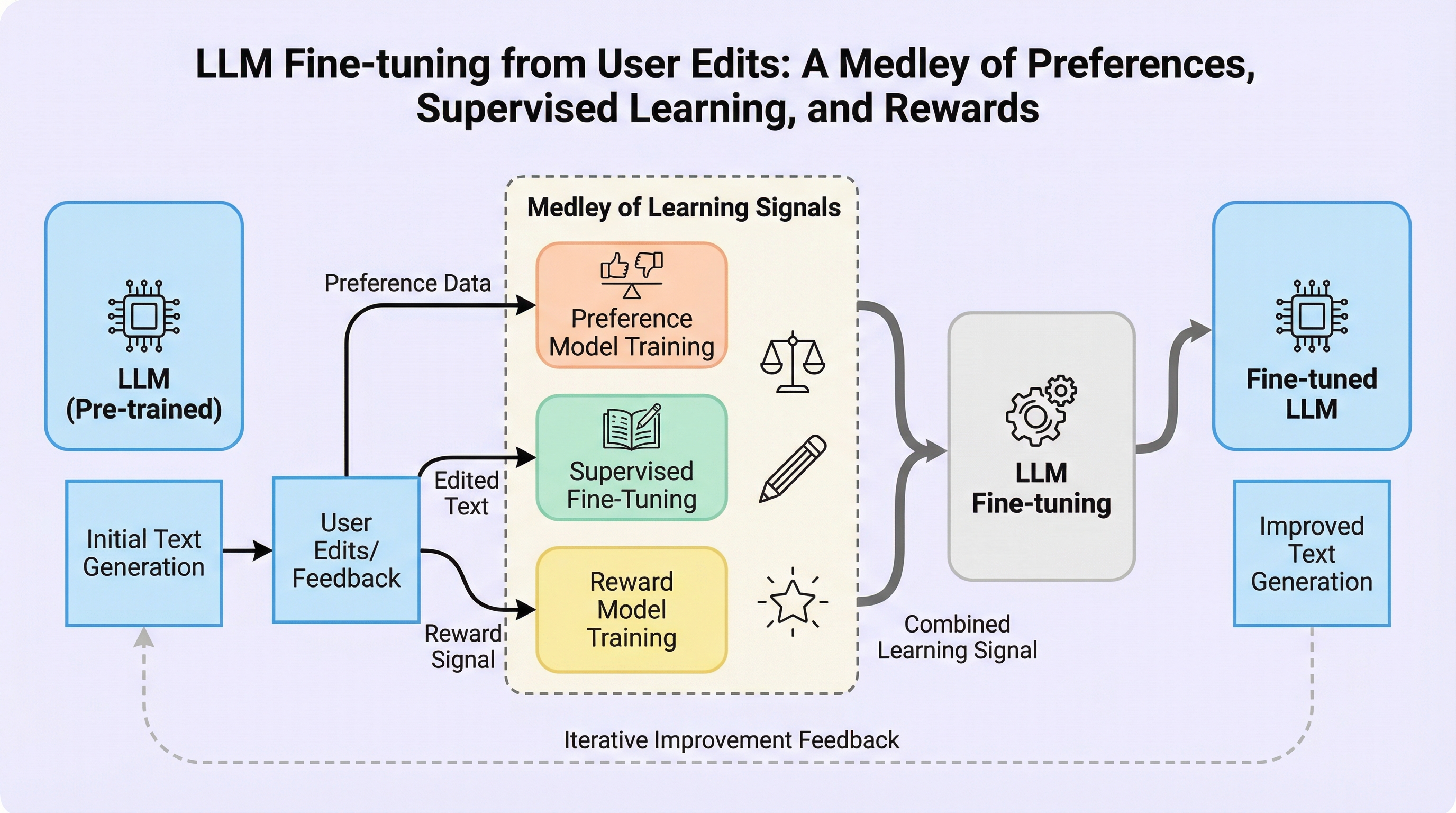
大規模言語モデル(LLM)のデプロイ後に得られる「ユーザーによる応答の編集」を、教師あり学習、選好学習、強化学習という3つの異なるフィードバック源として統合的に活用する新しい学習枠組みを提案しています。