線形オフポリシー評価におけるカバレッジの統一的視点
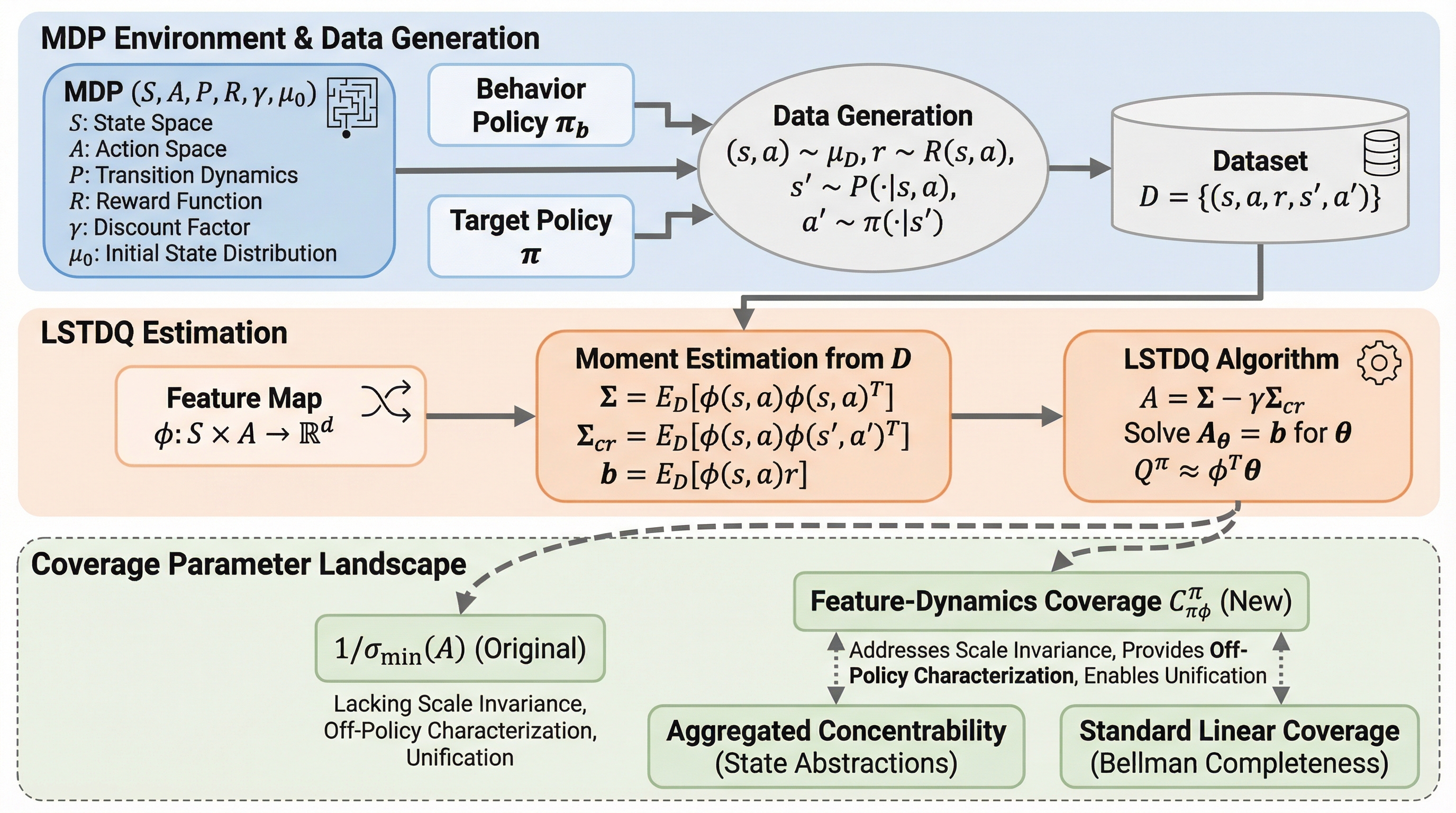
強化学習のオフポリシー評価(OPE)において、データの質を規定する「カバレッジ」の概念は、線形関数近似の設定では定義が断片的であり、従来の最小特異値に基づく指標は尺度不変性の欠如やオフポリシー設定での解釈の難しさといった課題を抱えていたが、本研究は統計学の操作変数法の視点から「特徴量ダイナミクス・カバレッジ」という新指標を提案した。 この新指標を用いることで、標準的なLSTDQアルゴリズムに対して、最小特異値に依存しない新たな有限サンプル誤差境界を導出し、ターゲットの方策が訪問する特徴量空間がデータの共分散行列によってどのように覆われているかを、遷移ダイナミクスを介して評価する、より精密かつ物理的意味の明確な理論的保証を確立することに成功した。 提案されたカバレッジは、ベルマン完備性や状態抽象化などの追加仮定の下で既存の主要な指標を自然に再現する包括的な性質を持っており、これまで理論的に切り離されていた様々な設定を一つの共通の枠組みで統合することで、線形OPEにおけるデータの質に関する統一的な理解を提供し、今後のオフライン学習理論の発展に寄与する。
TL;DR(結論)
強化学習のオフポリシー評価(OPE)において、データの質を規定する「カバレッジ」の概念は、線形関数近似の設定では定義が断片的であり、従来の最小特異値に基づく指標は尺度不変性の欠如やオフポリシー設定での解釈の難しさといった課題を抱えていたが、本研究は統計学の操作変数法の視点から「特徴量ダイナミクス・カバレッジ」という新指標を提案した。 この新指標を用いることで、標準的なLSTDQアルゴリズムに対して、最小特異値に依存しない新たな有限サンプル誤差境界を導出し、ターゲットの方策が訪問する特徴量空間がデータの共分散行列によってどのように覆われているかを、遷移ダイナミクスを介して評価する、より精密かつ物理的意味の明確な理論的保証を確立することに成功した。 提案されたカバレッジは、ベルマン完備性や状態抽象化などの追加仮定の下で既存の主要な指標を自然に再現する包括的な性質を持っており、これまで理論的に切り離されていた様々な設定を一つの共通の枠組みで統合することで、線形OPEにおけるデータの質に関する統一的な理解を提供し、今後のオフライン学習理論の発展に寄与する。
なぜこの問題か
強化学習におけるオフポリシー評価(OPE)は、過去の異なる方策(振る舞い方策)によって収集された固定データセットのみを用いて、未知の新しい方策(ターゲット方策)の性能を推定する技術であり、実世界への応用において極めて重要な役割を果たす。このタスクの成功を左右する核心的な概念が「カバレッジ」である。カバレッジは、収集されたデータがターゲット方策の評価に必要な情報をどの程度含んでいるかを数学的に特徴づけるものであり、データの分布シフトという強化学習の根本的な課題を定量化する役割を担う。しかし、最も基本的かつ広く用いられる設定の一つである「ターゲットの価値関数が与えられた特徴量に対して線形である(線形実現可能性)」という最小限の仮定の下では、このカバレッジの適切な定義についてはこれまで理解が不足しており、議論が断片化していた。 従来、この設定で最も標準的なアルゴリズムとされるLSTDQ(最小二乗時間差学習)の解析では、推定に用いる行列の最小特異値の逆数がカバレッジの役割を果たすと考えられてきた。しかし、この指標には重大な欠点が三つ存在する。第一に、尺度不変性の欠如である。…
核心:何を提案したのか
本研究の最大の貢献は、LSTDQアルゴリズムの有限サンプル解析を通じて、「特徴量ダイナミクス・カバレッジ」と呼ばれる新しいカバレッジパラメータを提案したことである。このパラメータは、統計学における操作変数(Instrumental Variable)法の視点から着想を得て導出されたものであり、従来の最小特異値に基づく指標が抱えていた問題を鮮やかに解決している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related