OATS:時系列基盤モデルのためのオンラインデータ拡張
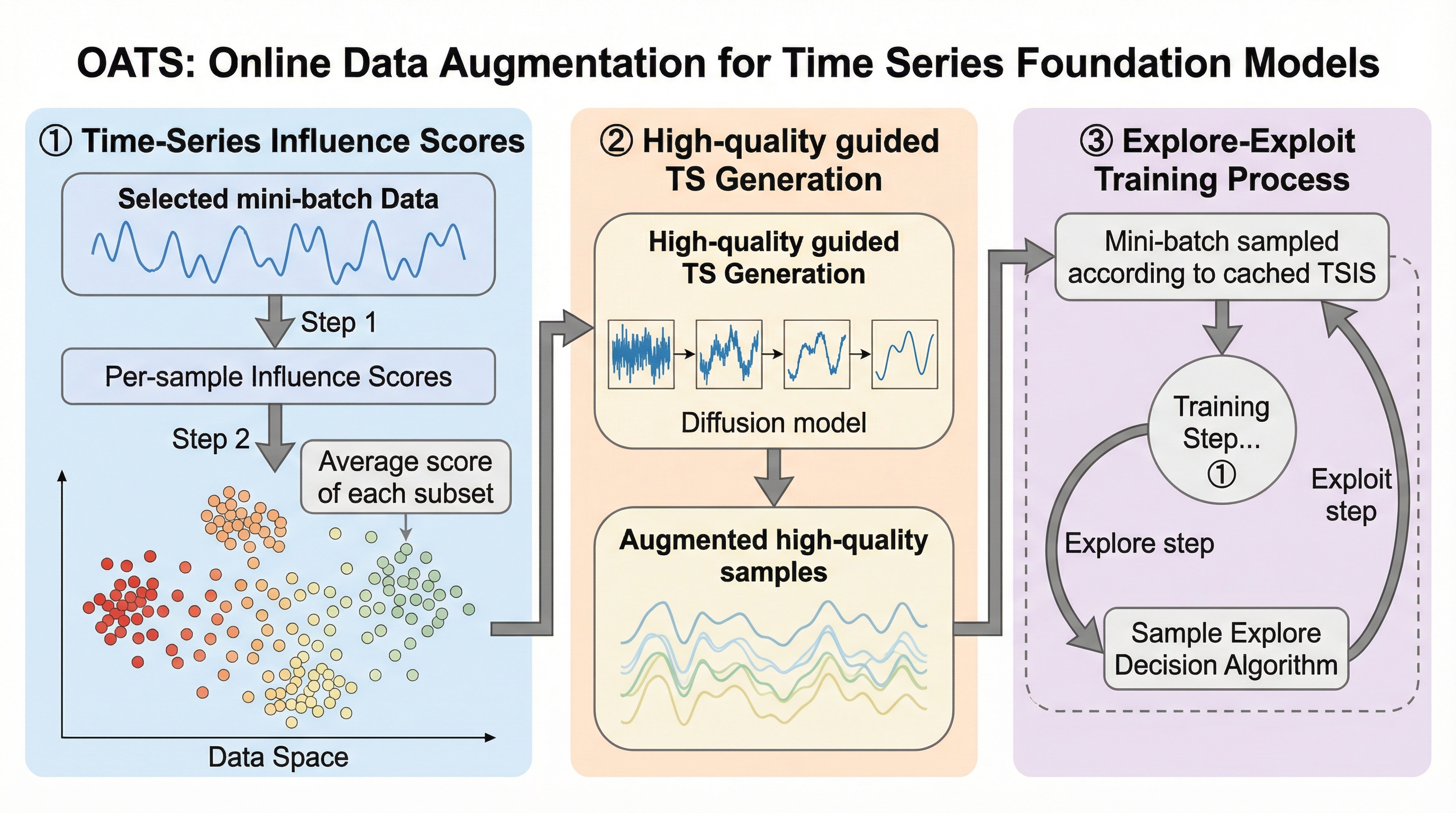
OATSは、時系列基盤モデル(TSFM)の学習を最適化するために、学習の進捗に合わせて動的に高品質な合成データを生成するオンラインデータ拡張手法である。 従来の静的な拡張手法とは異なり、データアトリビューションに基づき、モデルの損失減少に最も寄与するサンプルを特定する「時系列インフルエンススコア(TSIS)」を導入し、これをガイドとして拡散モデルでデータを生成する。 6つの主要データセットと2つの代表的なTSFMアーキテクチャを用いた検証において、OATSは従来の静的な拡張手法や通常学習を一貫して上回る予測精度と収束速度を達成し、計算効率と精度の両立を実現した。
TL;DR(結論)
OATSは、時系列基盤モデル(TSFM)の学習を最適化するために、学習の進捗に合わせて動的に高品質な合成データを生成するオンラインデータ拡張手法である。 従来の静的な拡張手法とは異なり、データアトリビューションに基づき、モデルの損失減少に最も寄与するサンプルを特定する「時系列インフルエンススコア(TSIS)」を導入し、これをガイドとして拡散モデルでデータを生成する。 6つの主要データセットと2つの代表的なTSFMアーキテクチャを用いた検証において、OATSは従来の静的な拡張手法や通常学習を一貫して上回る予測精度と収束速度を達成し、計算効率と精度の両立を実現した。
なぜこの問題か
時系列基盤モデル(TSFM)の発展は、金融、医療、気候科学、産業モニタリングなど多岐にわたる分野で重要な役割を果たしている。これらのモデルの成功は、大規模かつ高品質なデータセットの可用性に強く依存しているが、現実の時系列データには多くの課題が存在する。具体的には、欠損値の存在、不均一なサンプリングレート、ドメイン分布の不均衡、データの重複といった問題があり、これらが自然言語処理のような他の領域と比較して、信頼性の高い大規模データセットを構築することを困難にしている。このデータ不足や質の低さを補うために、合成データを用いたデータ拡張が広く採用されてきた。 しかし、既存の時系列データ拡張手法の多くは、ヒューリスティックなルールや静的なパラダイムに基づいている。例えば、正弦波の合成や既存データの単純な変換(ジッタリングやミキシングなど)は、モデルの学習プロセスとは無関係に設計されており、特定のタスクでは有効でも他のタスクでは効果が薄い、あるいは悪影響を及ぼす可能性がある。さらに、近年の研究では、同じデータサンプルであっても学習の段階によってその重要度やモデルへの貢献度が変化することが示されている。…
核心:何を提案したのか
本論文では、時系列基盤モデルのための新しいオンラインデータ拡張戦略である「OATS(Online Data Augmentation for Time Series Foundation Models)」を提案している。OATSの核心的なアイデアは、学習の各ステップにおいて、その時点のモデルにとって最も価値の高いサンプルを特定し、それらをガイド信号(プロンプト)として高品質な合成データを動的に生成することにある。このアプローチは、従来の静的なデータ拡張の枠組みを大幅に拡張し、学習プロセスの情報を積極的に取り入れる新しいパラダイムを提示している。 具体的には、データアトリビューションの手法を用いて、個々の学習データがモデルの出力や損失関数に与える影響を定量的に評価する。これにより、経験則やヒューリスティックなルールに頼ることなく、原理的な方法で時系列データの質を定義し、評価することが可能になった。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related