ランダム化がKVキャッシュを強化し、学習がクエリ負荷を均衡させる:統合的視点
大規模言語モデル(LLM)の推論を加速するKVキャッシュにおいて、従来のLRU方式が動的なクエリ到着に対して脆弱であるという課題に対し、キャッシュ追い出しとクエリルーティングを統合的に扱う初の数学的モデルを提案し、理論的限界を打破した。
TL;DR(結論)
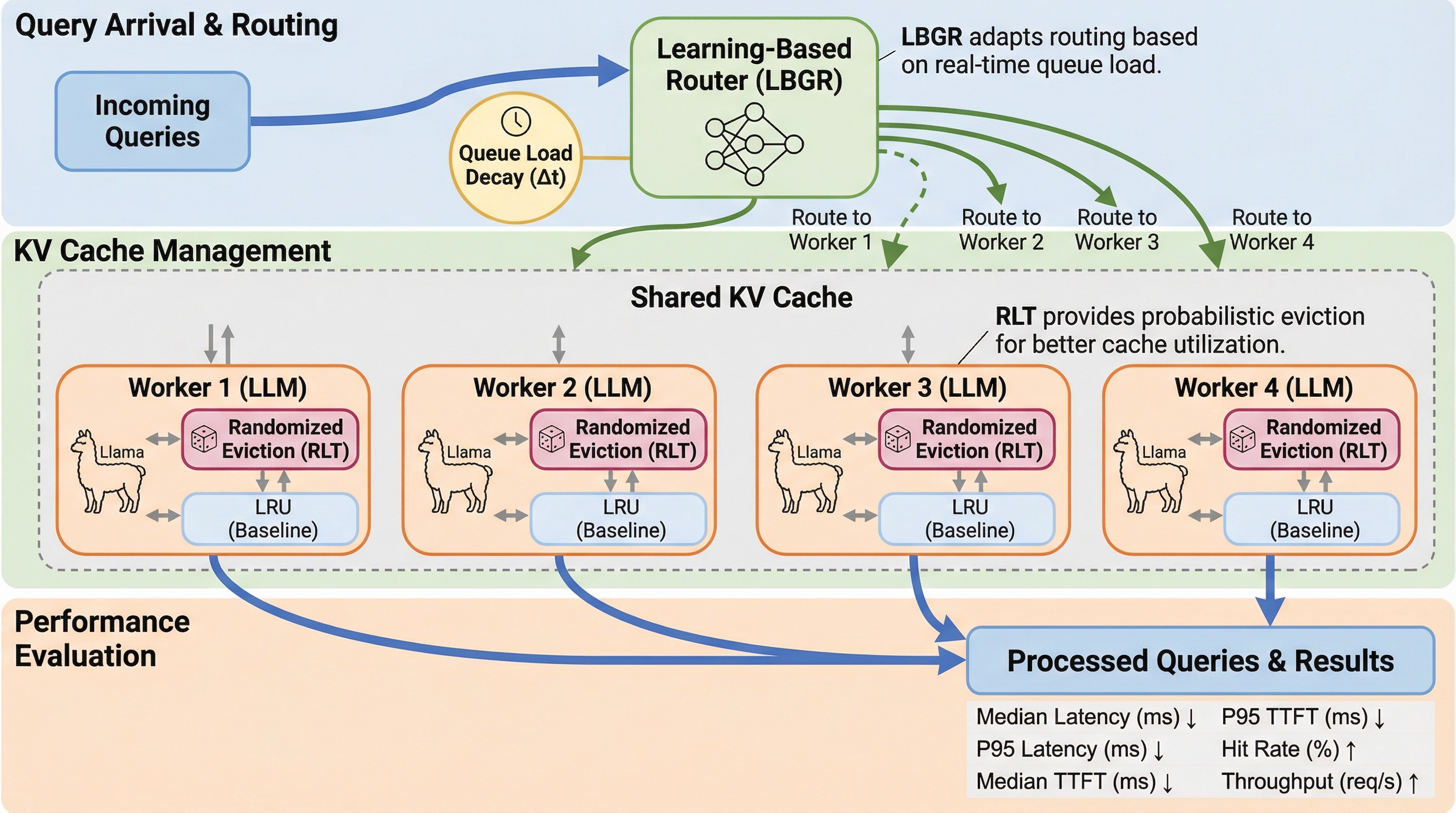
大規模言語モデル(LLM)の推論を加速するKVキャッシュにおいて、従来のLRU方式が動的なクエリ到着に対して脆弱であるという課題に対し、キャッシュ追い出しとクエリルーティングを統合的に扱う初の数学的モデルを提案し、理論的限界を打破した。 ランダム化を取り入れた追い出しアルゴリズム「RLT」と、オンライン学習を用いて遅延を予測しクエリを割り当てる「LBGR」を開発し、理論的にLRUを大幅に上回る競争比を達成するとともに、動的なワークロード下でのシステムの堅牢性と効率性を劇的に向上させた。 実験の結果、既存の最先端手法と比較してキャッシュヒット率を最大6.92倍に高め、推論遅延を11.96倍、初トークン放出時間を14.06倍削減し、スループットを77.4%向上させるという、実用上の極めて顕著な性能改善を実証することに成功した。
なぜこの問題か
大規模言語モデル(LLM)のサービス需要が世界的に急増する中で、推論時の計算オーバーヘッドをいかに削減するかは、システムの持続可能性を左右する極めて重要な課題となっている。KVキャッシュは、過去のクエリで処理されたトークンのキーと値のペアをメモリ上に保存し、再利用することで計算コストを大幅に軽減する基盤技術であるが、メモリ容量には物理的な限界がある。そのため、限られたメモリ空間からどのデータを削除するかを決定する「追い出しポリシー」が、システム全体の効率を左右する決定的な要因となる。現在、多くの商用システムでは「最も古く利用されたもの」を優先的に削除するLRU(Least Recently Used)方式が採用されているが、これは特定のアクセスパターンや動的に変化するクエリの到着順序に対して非常に脆弱である。特に、複数のLLMワーカーを並列に運用する環境では、各ワーカーの負荷を均等にする「負荷分散」と、キャッシュの再利用率を最大化する「キャッシュ親和性」が本質的に対立するという難題に直面する。…
核心:何を提案したのか
本研究では、KVキャッシュを考慮した負荷分散問題を定式化する、世界初の統合的な数学モデルを提案した。このモデルは、各クエリの処理時間を「サービス時間」と「待ち時間」に明確に分解し、サービス時間をキャッシュの状態の関数として定義することで、システム全体の最大処理時間(メイクスパン)を最小化することを目指している。理論的な分析を通じて、既存のLRUベースの追い出しポリシーが最悪の場合にキャッシュサイズに比例する競争比しか持たないという致命的な限界を明らかにした。この理論的洞察に基づき、二つの主要なアルゴリズム、すなわち「RLT(Randomized Leaf Token eviction)」と「LBGR(Learning-Based Greedy Routing)」を導入した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related