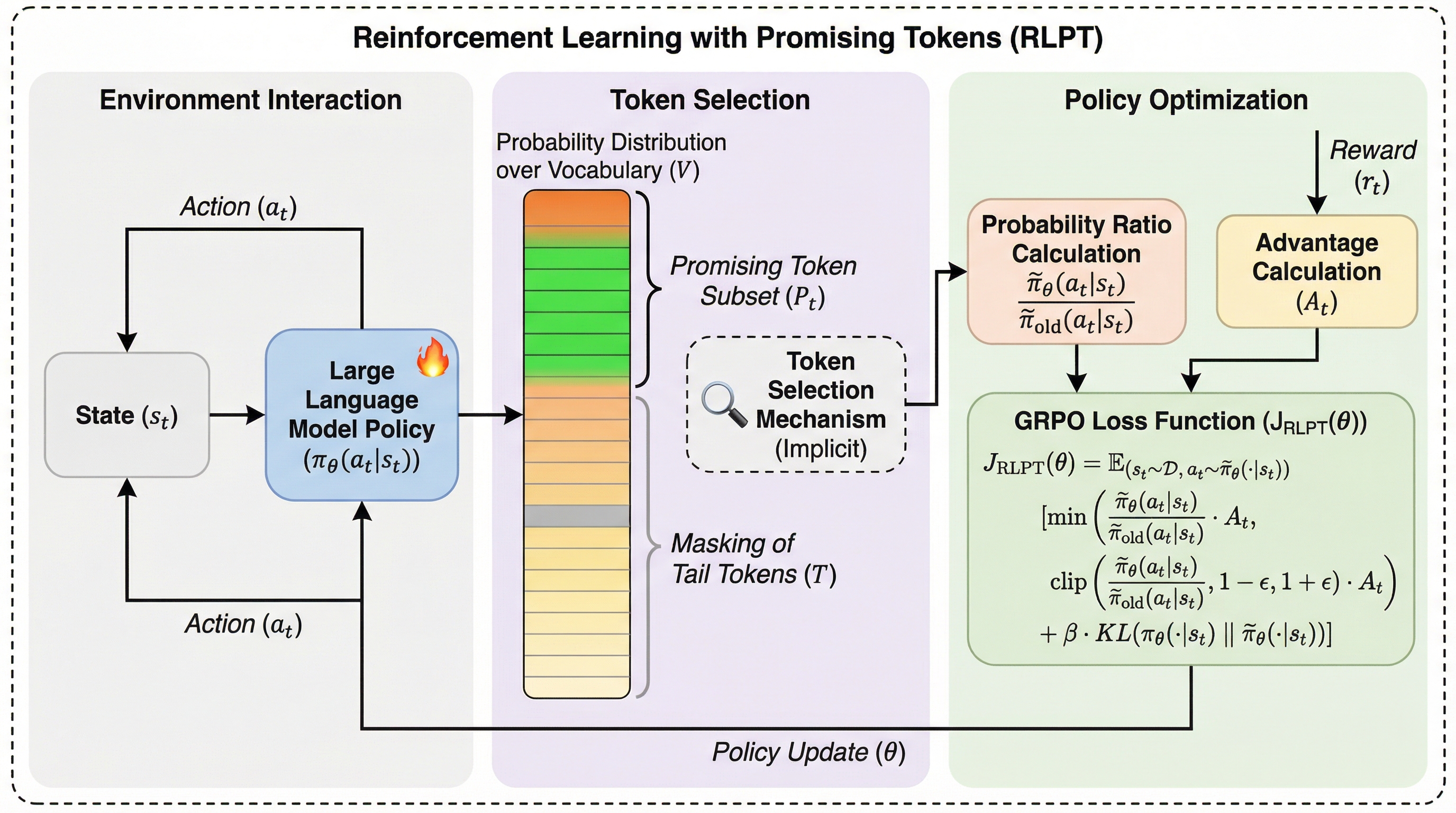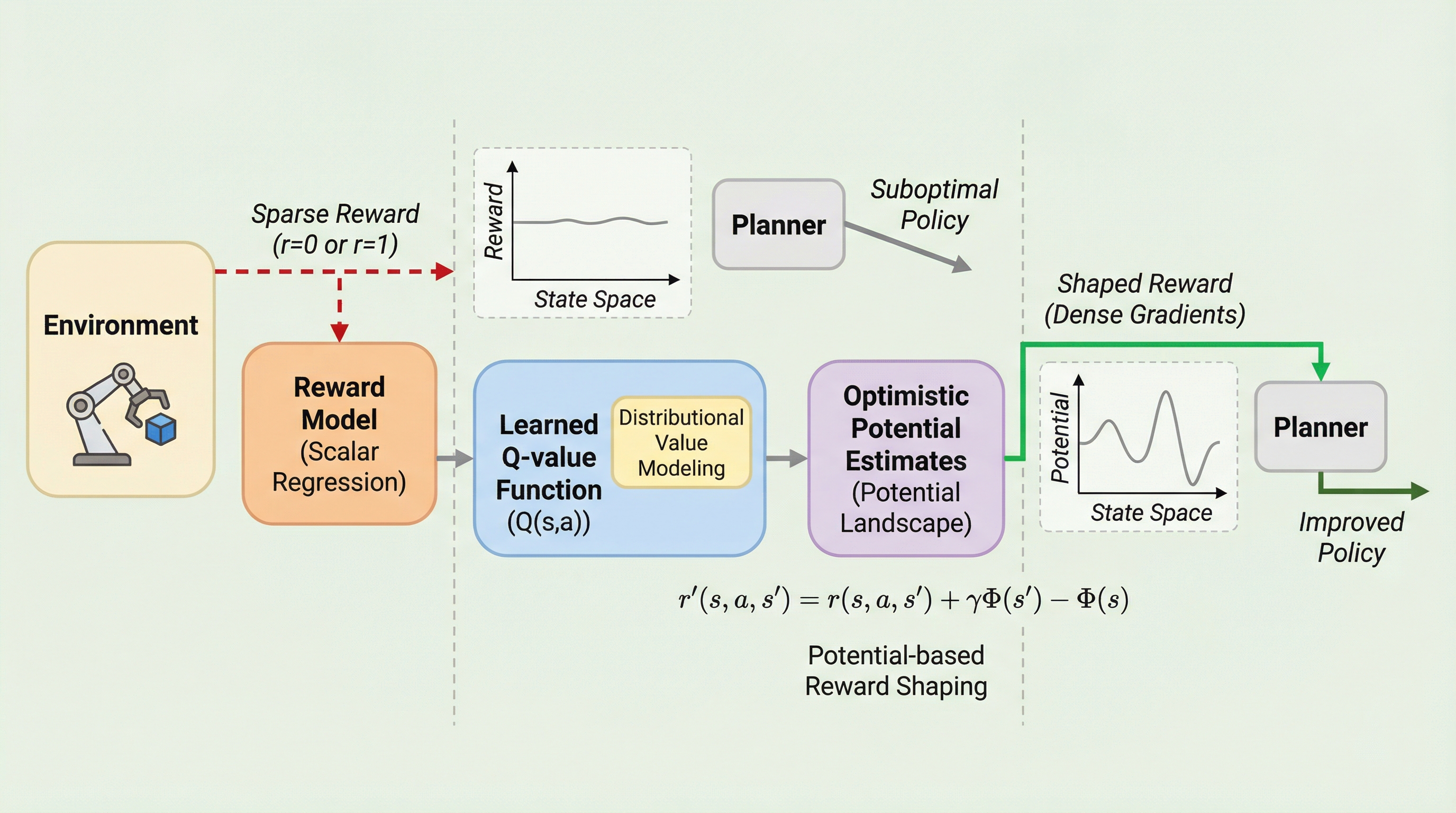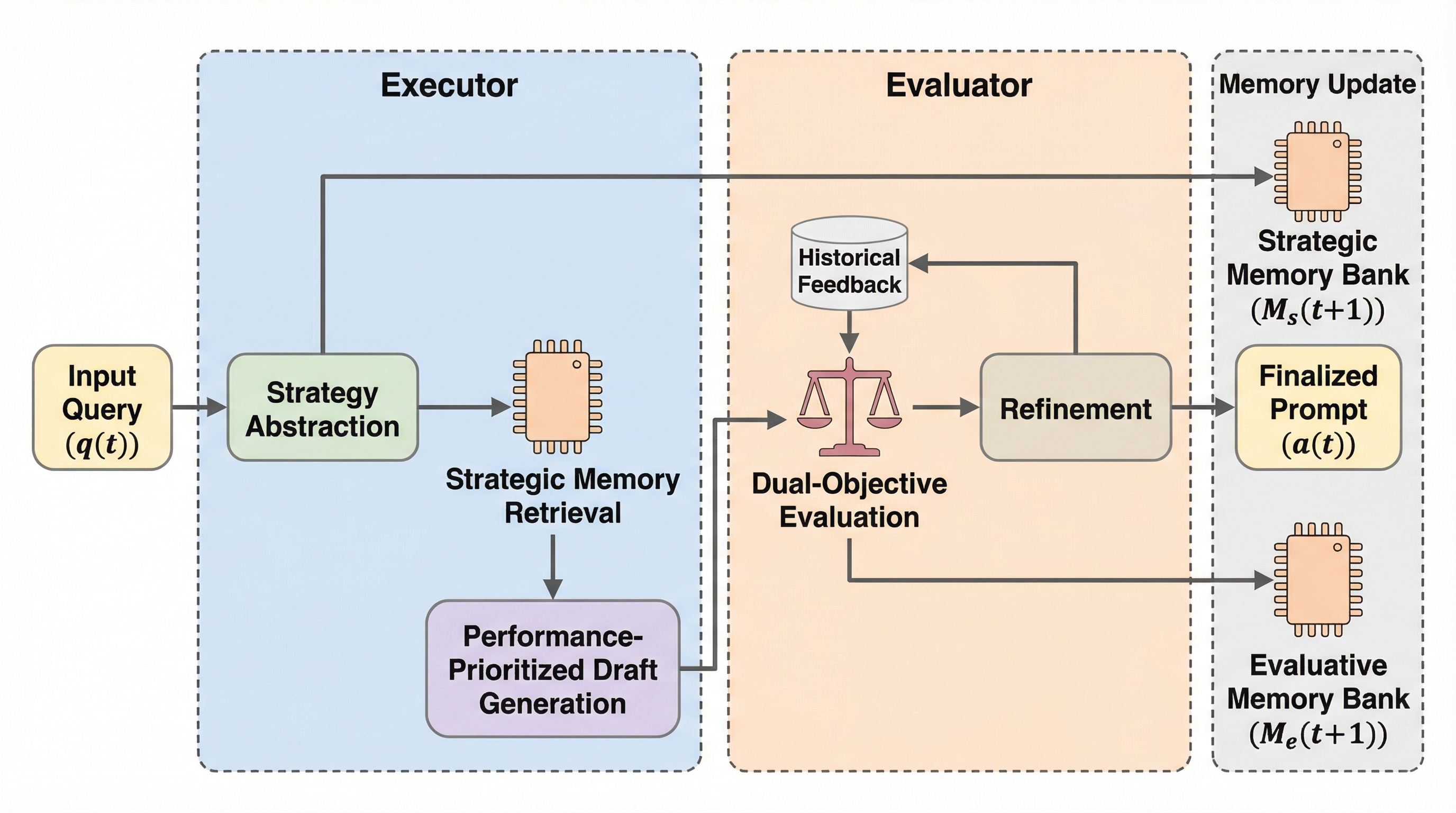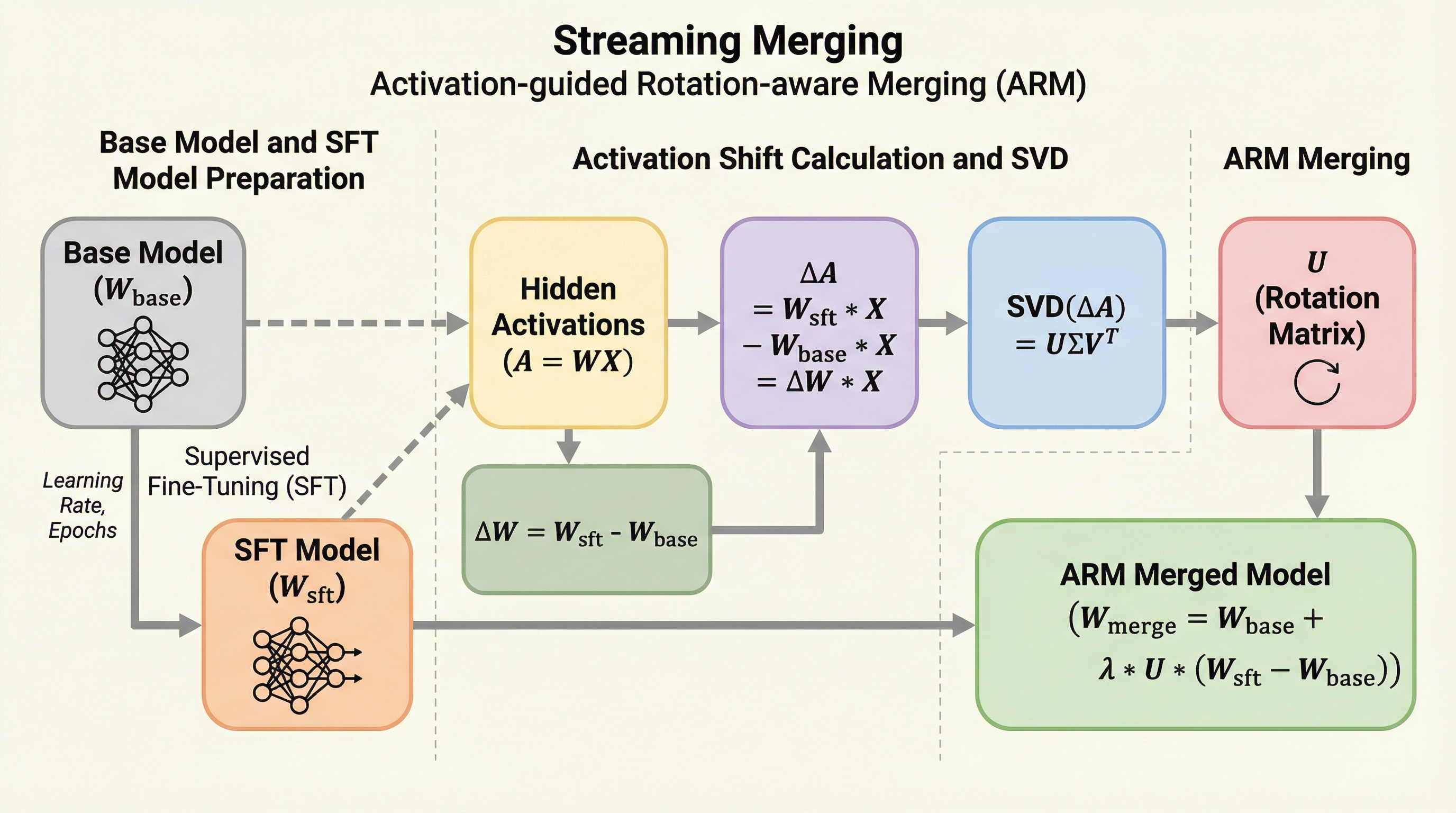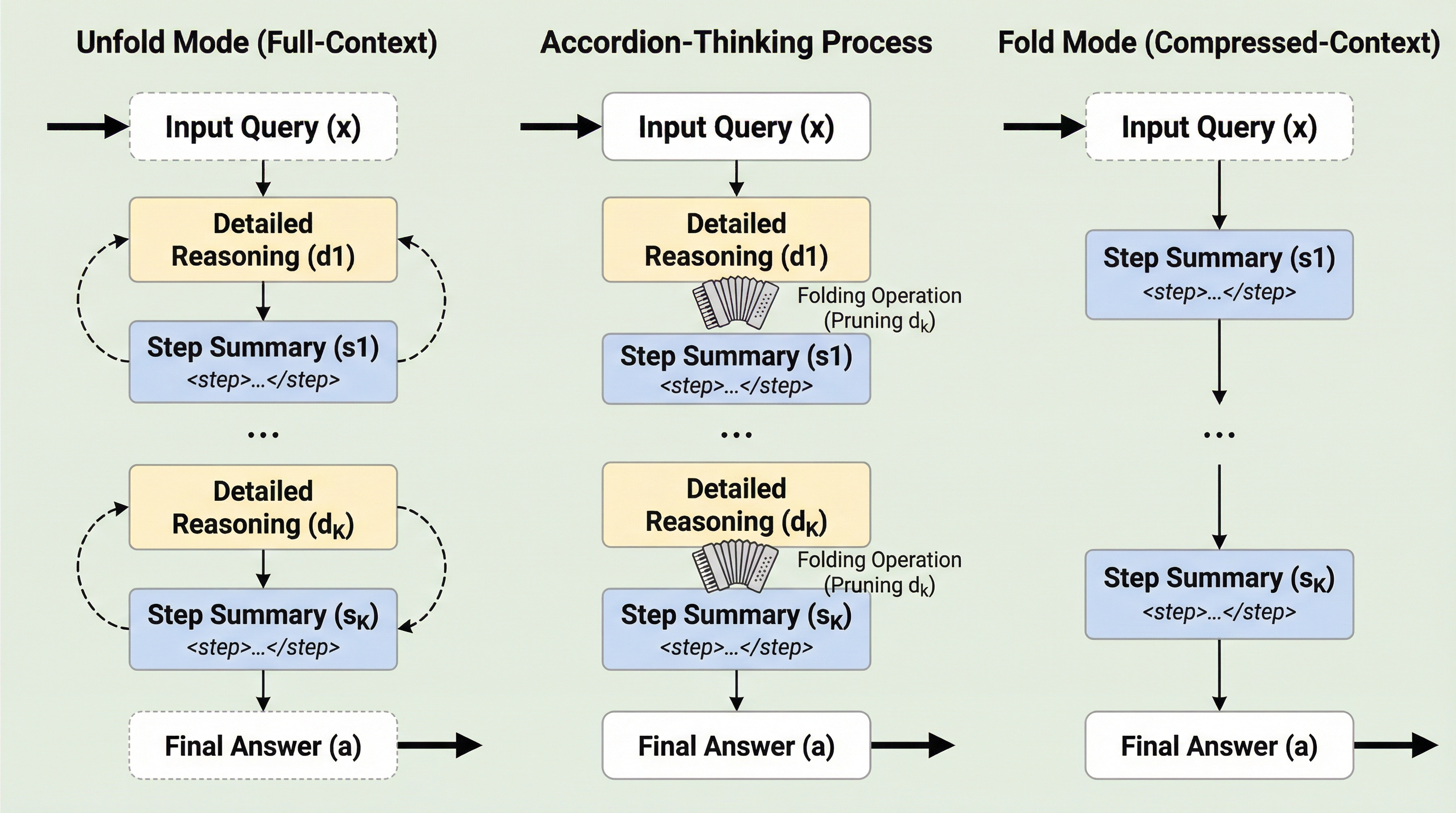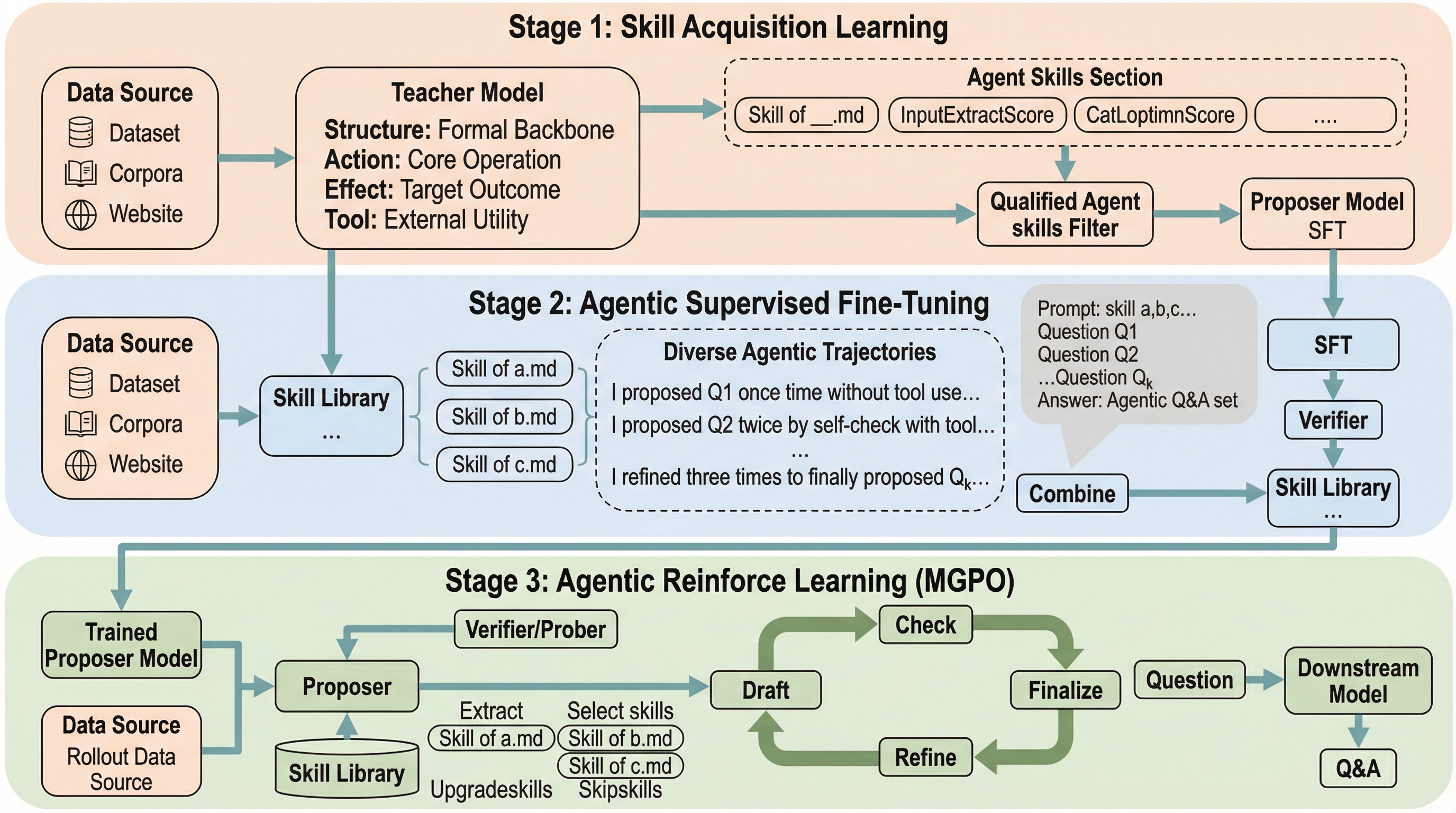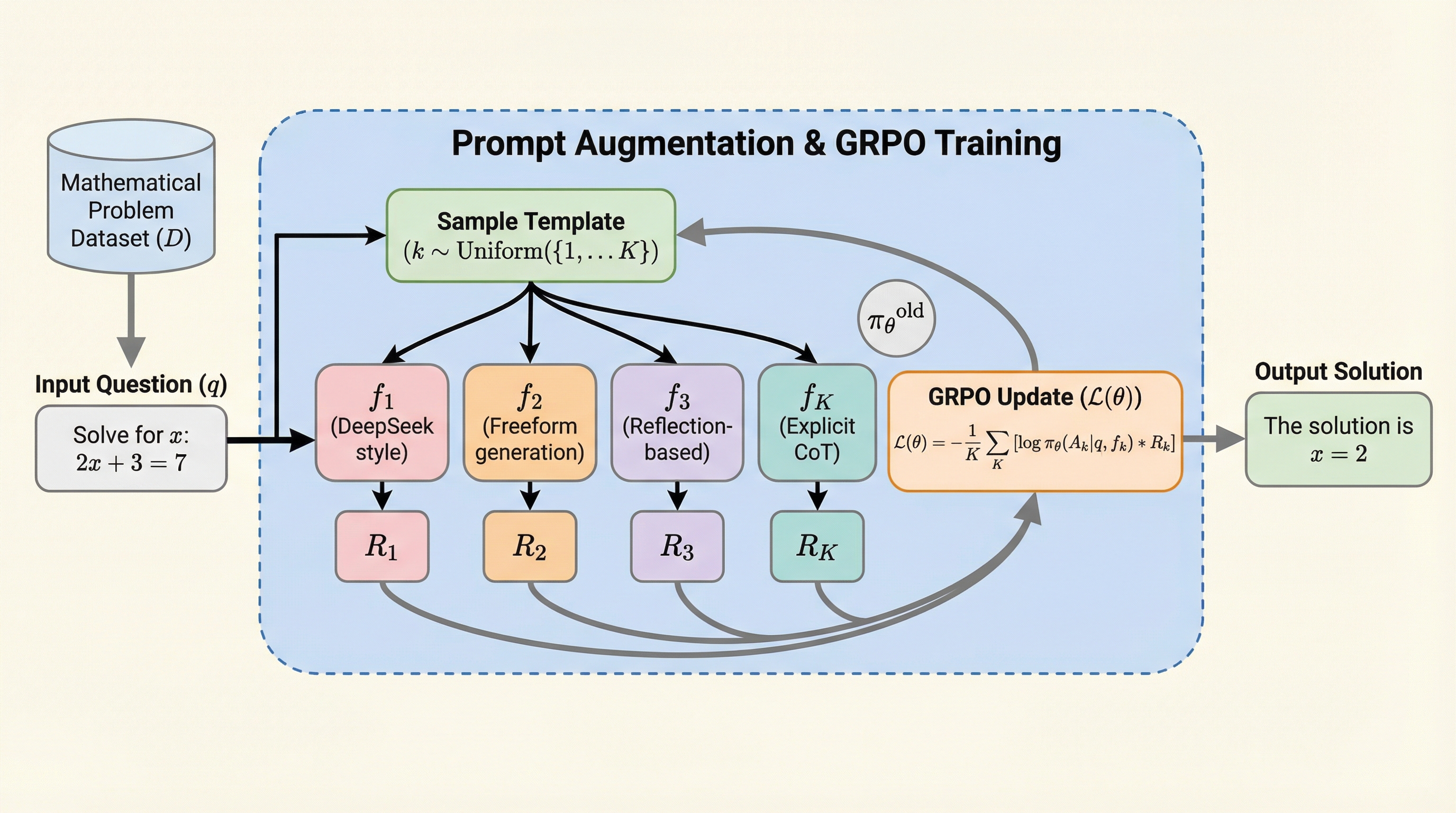
プロンプト拡張は数学的推論におけるGRPOトレーニングをスケールアップさせる
大規模言語モデルの数学的推論能力を向上させる強化学習において、従来はエントロピー崩壊による不安定性が原因で、学習が5〜20エポック程度の短期間に制限されるという課題がありました。本研究が提案する「プロンプト拡張」は、複数の推論テンプレートとフォーマット報酬を組み合わせることで、単一の学習実行内で多様な推論の振る舞いを引き出し、エントロピー崩壊を抑制することに成功しました。この手法により、Qwen2.5-Math-1.5Bモデルにおいて最大50エポックの安定した長期学習が可能となり、主要な数学ベンチマークで従来手法を上回る最高水準の精度を達成しました。具体的には、多様なテンプレートを用いることで低エントロピー状態でも学習を継続できる安定性を確保し、計算コストを抑えつつモデルの推論能力を最大限に引き出す新しいトレーニングパラダイムを提示しています。