プロンプト拡張は数学的推論におけるGRPOトレーニングをスケールアップさせる
大規模言語モデルの数学的推論能力を向上させる強化学習において、従来はエントロピー崩壊による不安定性が原因で、学習が5〜20エポック程度の短期間に制限されるという課題がありました。本研究が提案する「プロンプト拡張」は、複数の推論テンプレートとフォーマット報酬を組み合わせることで、単一の学習実行内で多様な推論の振る舞いを引き出し、エントロピー崩壊を抑制することに成功しました。この手法により、Qwen2.5-Math-1.5Bモデルにおいて最大50エポックの安定した長期学習が可能となり、主要な数学ベンチマークで従来手法を上回る最高水準の精度を達成しました。具体的には、多様なテンプレートを用いることで低エントロピー状態でも学習を継続できる安定性を確保し、計算コストを抑えつつモデルの推論能力を最大限に引き出す新しいトレーニングパラダイムを提示しています。
TL;DR(結論)
大規模言語モデルの数学的推論能力を向上させる強化学習において、従来はエントロピー崩壊による不安定性が原因で、学習が5〜20エポック程度の短期間に制限されるという課題がありました。本研究が提案する「プロンプト拡張」は、複数の推論テンプレートとフォーマット報酬を組み合わせることで、単一の学習実行内で多様な推論の振る舞いを引き出し、エントロピー崩壊を抑制することに成功しました。この手法により、Qwen2.5-Math-1.5Bモデルにおいて最大50エポックの安定した長期学習が可能となり、主要な数学ベンチマークで従来手法を上回る最高水準の精度を達成しました。具体的には、多様なテンプレートを用いることで低エントロピー状態でも学習を継続できる安定性を確保し、計算コストを抑えつつモデルの推論能力を最大限に引き出す新しいトレーニングパラダイムを提示しています。
なぜこの問題か
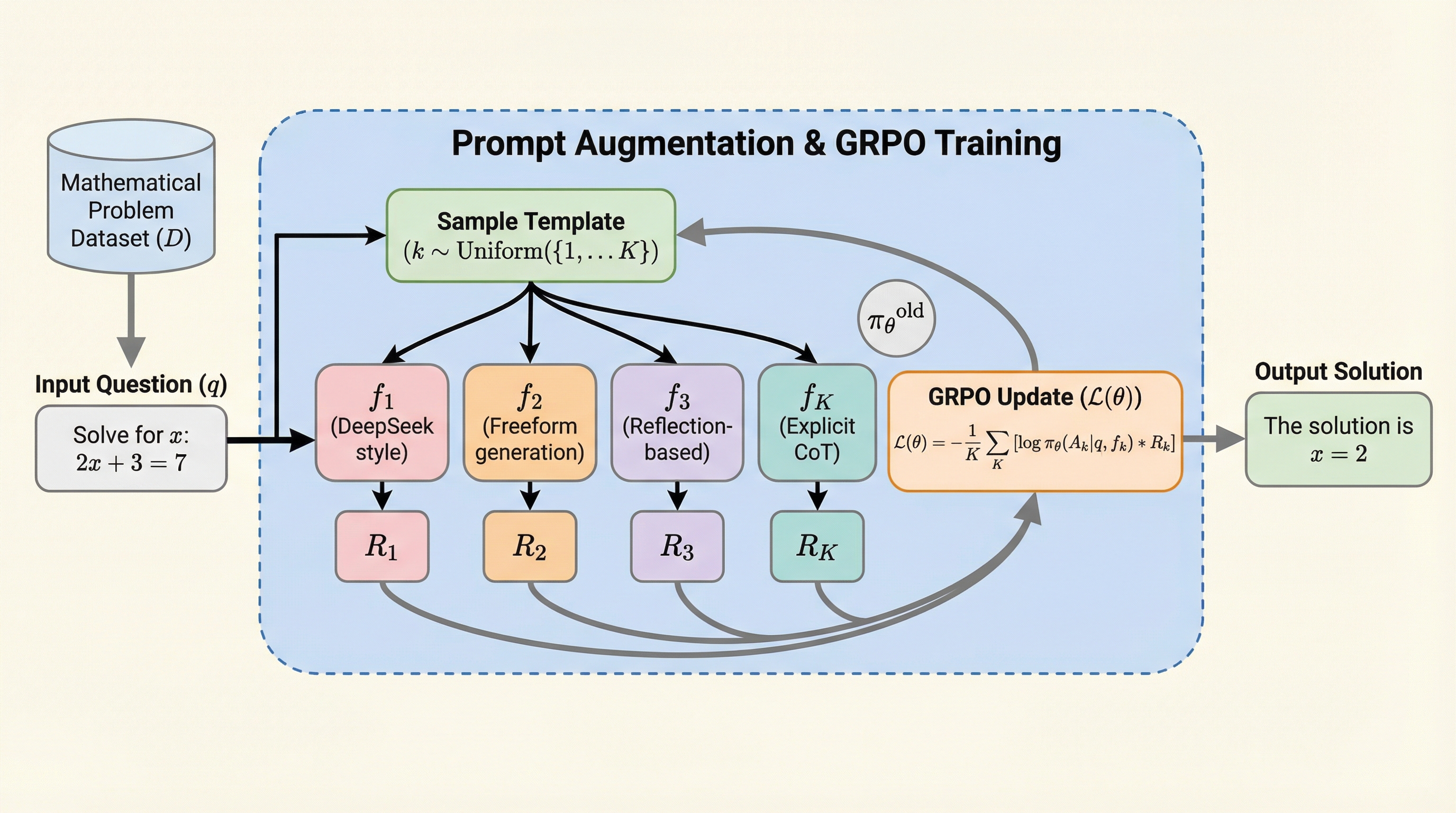
大規模言語モデル(LLM)の数学的推論能力を向上させる手法として、グループ相対方策最適化(GRPO)などの強化学習アルゴリズムが注目を集めています。しかし、これまでの研究では、強化学習の事後トレーニング中に「エントロピー崩壊」と呼ばれる深刻な現象が頻繁に観察されてきました。これは、学習が進むにつれて方策のエントロピーが単調に減少し、モデルの出力が特定のパターンに固定されてしまう現象を指します。エントロピーが低下すると、モデルは多様な推論経路を探索できなくなり、最終的には学習の不安定化や崩壊を招くことになります。この不安定性のために、既存の多くの手法では学習期間を5エポックから20エポック程度の非常に短い範囲に制限せざるを得ませんでした。例えば、先行研究のDAPOは9.9エポック、Dr. GRPOは6.0エポック、SEED-GRPOは5.4〜13.9エポックといった具合に、長期的な探索と方策の改善が妨げられてきたのが現状です。また、従来の学習の多くは単一の固定された推論プロンプトやテンプレートに依存しており、これが特定の推論スタイルへの過学習を引き起こし、推論の多様性を損なわせているという課題もありました。…
核心:何を提案したのか
本研究では、LLMの数学的推論のための強化学習におけるシンプルかつ効果的な手法として「プロンプト拡張(Prompt Augmentation)」を提案しました。この手法の核心は、単一の学習実行の中で、モデルに対して多様なテンプレートやフォーマットを用いて推論の軌跡を生成させることにあります。具体的には、タグを用いた推論と回答の分離、自由形式の生成、明示的な思考連鎖(Chain-of-Thought)プロンプト、そして自己反省(Reflection)ベースのフォーマットなど、複数の推論スタイルを混合して学習を行います。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related