スカラ報酬からポテンシャルの傾向へ:モデルベース強化学習のためのポテンシャル景観の形成
モデルベース強化学習(MBRL)はサンプル効率に優れるが、報酬が稀にしか得られない「疎な報酬」環境では、報酬モデルが平坦になり計画を導くための有益な勾配が消失するという深刻なボトルネックに直面する。
TL;DR(結論)
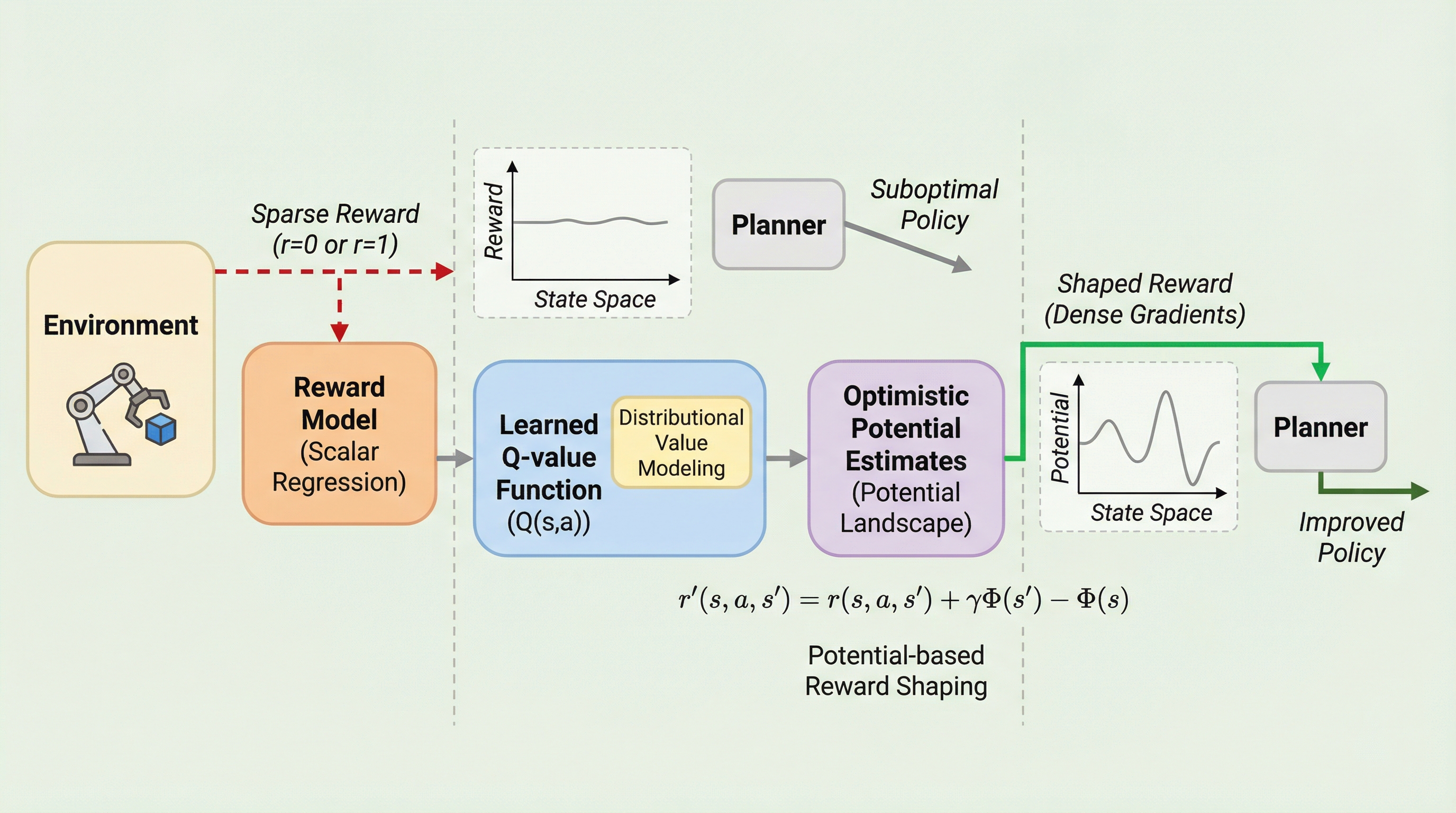
モデルベース強化学習(MBRL)はサンプル効率に優れるが、報酬が稀にしか得られない「疎な報酬」環境では、報酬モデルが平坦になり計画を導くための有益な勾配が消失するという深刻なボトルネックに直面する。 本研究が提案するSLOPEは、報酬モデルの役割を単なるスカラ値の予測から「ポテンシャル景観」の構築へと転換し、楽観的な分布回帰(QCE損失)を用いて高信頼な上限値を推定することで、探索を強力に促す密な誘導信号を生成する。 30以上のタスクを用いた広範な検証の結果、SLOPEは既存の主要な手法を一貫して上回り、最適なポリシーの不変性を理論的に保証したまま、完全に疎な報酬設定においても学習効率と成功率を大幅に向上させることに成功した。
なぜこの問題か
モデルベース強化学習(MBRL)は、学習された環境ダイナミクスと報酬モデルを利用して将来の軌跡をシミュレーションし、ポリシーを評価することで高いサンプル効率を実現する手法である。しかし、この手法の成功は、計画のためのきめ細かなフィードバックを提供する「密な報酬信号」の存在に大きく依存している。現実世界の環境では、タスクの成功か失敗かを示すバイナリ信号のような「疎な(稀薄な)報酬」が一般的であり、これがMBRLの適用を制限する大きな要因となっている。稀薄な報酬設定におけるMBRLの報酬モデル開発には、主に2つの大きな課題が存在する。 第一の課題は、極端なデータの不均衡による報酬学習の失敗である。報酬が疎な設定では、収集される軌跡の大部分が報酬ゼロとなる。成功サンプルの不足により、報酬モデルが意味のある成功パターンを抽出することが困難になり、モデルが多数派である「報酬ゼロ」のクラスに崩壊してしまう現象が発生する。第二の課題は、グラウンドトゥルース(正解)の報酬が計画において効果を発揮しないことである。既存の多くのMBRLアプローチは、正解のスカラ報酬を正確に回帰することに焦点を当てている。…
核心:何を提案したのか
本研究では、疎な報酬環境におけるMBRLを強化するために設計された、ポテンシャルに基づく報酬形成(PBRS)手法である「SLOPE(Shaping Landscapes with Optimistic Potential Estimates)」を提案している。SLOPEの核心的なアイデアは、報酬モデルの役割を「スカラ値の予測」から「内部的なポテンシャル景観の構築」へとシフトさせることにある。具体的には、エージェントが学習したQ値関数を状態空間上のポテンシャル曲面として扱う。このメカニズムにより、元々は勾配がなく平坦であった報酬構造が、密な情報を持つ景観へと変換される。これにより、エージェントは推定されたポテンシャルが高い状態を探索するように促され、ロールアウト中に方向性のある報酬信号を受け取ることが可能になる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related