大規模言語モデルのための有望なトークンを用いた強化学習
大規模言語モデル(LLM)の強化学習において、5万語を超える膨大な語彙全体を最適化対象とせず、モデルの事前知識に基づき論理的に妥当な「有望なトークン」だけに絞り込んで学習を行う新フレームワーク「RLPT」が提案されました。
TL;DR(結論)
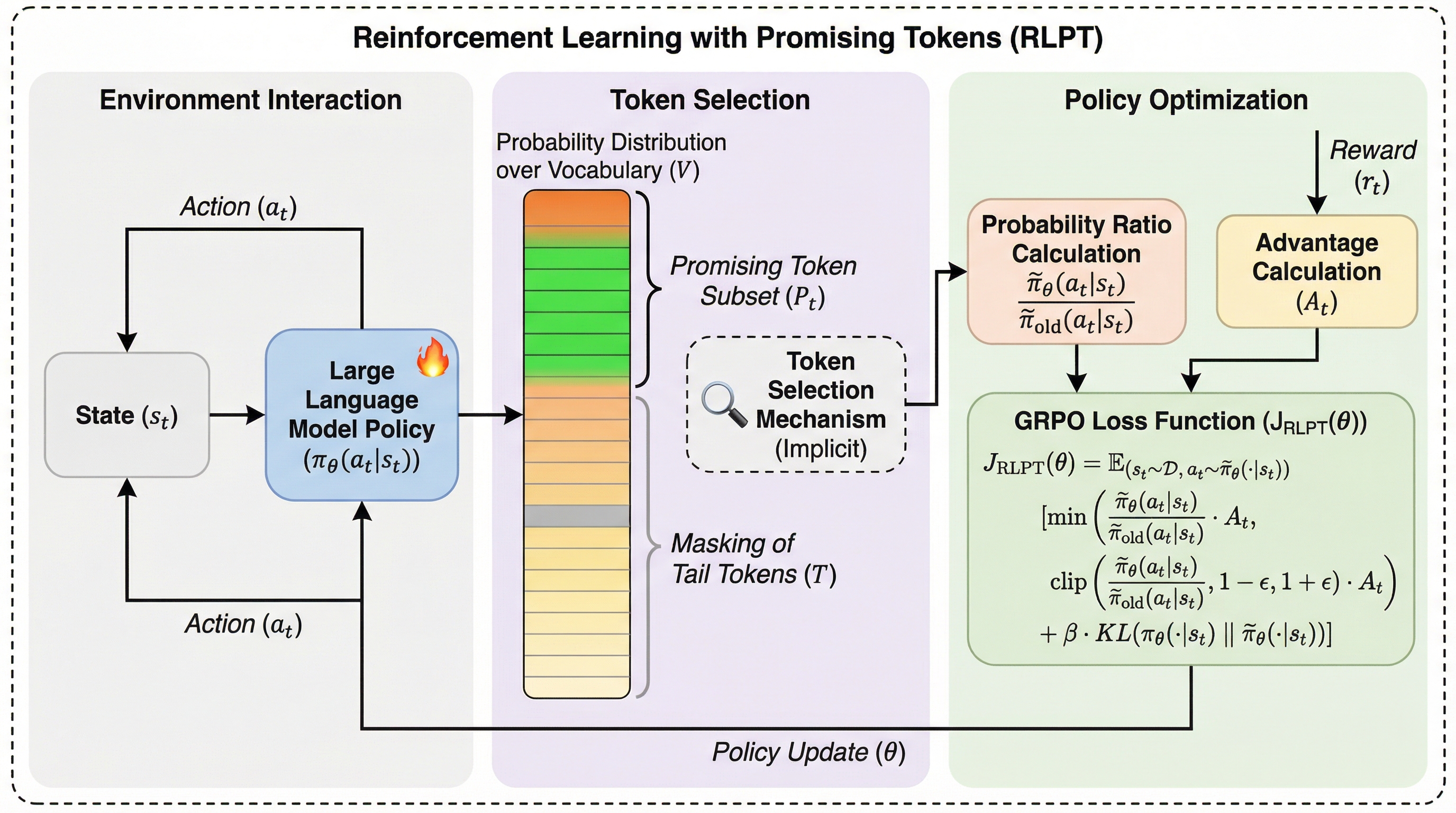
大規模言語モデル(LLM)の強化学習において、5万語を超える膨大な語彙全体を最適化対象とせず、モデルの事前知識に基づき論理的に妥当な「有望なトークン」だけに絞り込んで学習を行う新フレームワーク「RLPT」が提案されました。 この手法は、推論時のサンプリングと学習時の勾配計算の両方で動的なマスク処理を適用することで、文脈に関係のない不要なトークンによるノイズを排除し、学習の安定性とサンプル効率を大幅に向上させることに成功しています。 数学、コーディング、通信分野の推論タスクを用いた検証の結果、RLPTは標準的な強化学習アルゴリズム(GRPOやDAPO)を上回る精度を達成し、特に複雑な論理的思考を必要とする問題において高い効果を発揮することが確認されました。
なぜこの問題か
大規模言語モデルを人間の意図や特定の論理規則に適合させるため、強化学習(RL)は非常に重要な役割を果たしています。しかし、従来の強化学習アルゴリズムをそのままLLMに適用することには、特有の大きな課題が存在します。それは、アクション空間(選択肢)の次元数が極めて高いという点です。例えば、Atariのゲームやロボット制御といった従来の強化学習タスクでは、アクション空間は比較的コンパクトに設計されています。これに対し、LLMのアクション空間は語彙数そのものであり、通常は5万トークンを超えます。この膨大な選択肢の中には、現在の文脈とは全く無関係なトークンが大量に含まれており、これらが学習プロセスにおいて「ノイズ」として機能してしまいます。 これまでの研究では、推論(ロールアウト)段階において、上位K個のトークンのみを抽出するTop-kサンプリングや、累積確率に基づくニュークリアス・サンプリングなどの手法を用いて、生成されるテキストの整合性を保つ工夫がなされてきました。…
核心:何を提案したのか
本研究では、戦略的な意思決定とトークン生成を分離することでアクション空間の問題を緩和するフレームワーク「Reinforcement Learning with Promising Tokens(RLPT)」を提案しています。この手法の核心は、事前学習済みのベースモデルが持つ「意味的な事前知識(セマンティック・プライア)」を活用して、各ステップで動的に「有望なトークン(Promising Tokens)」のセットを特定することにあります。有望なトークンとは、現在の文脈において構文的に正しく、かつ意味的に妥当である可能性が高い候補を指します。 RLPTは、これらの有望なトークン以外の無関係なトークンを「マスク(遮断)」することによって、ポリシーの最適化をこの洗練されたサブセットのみに限定します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related