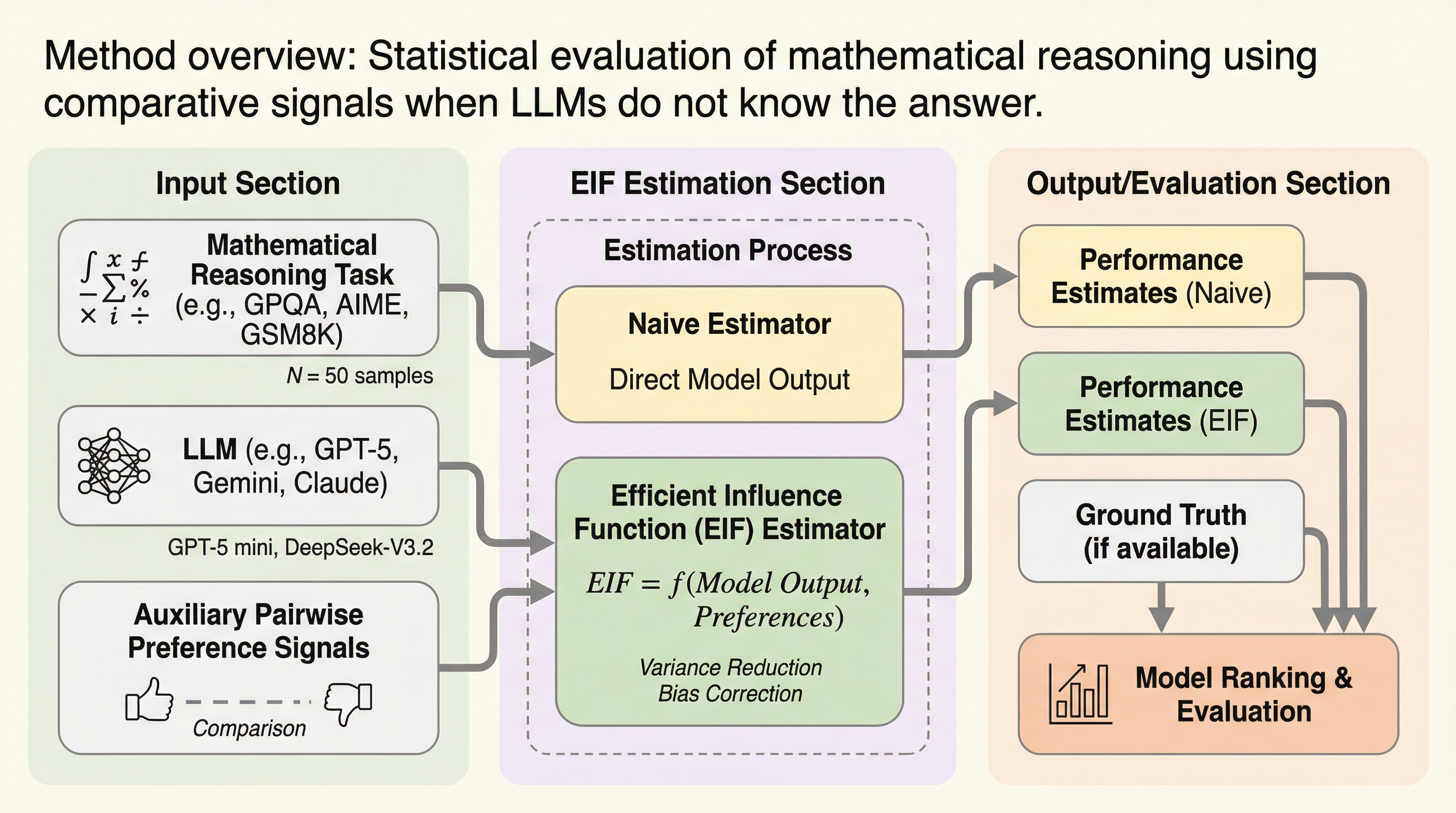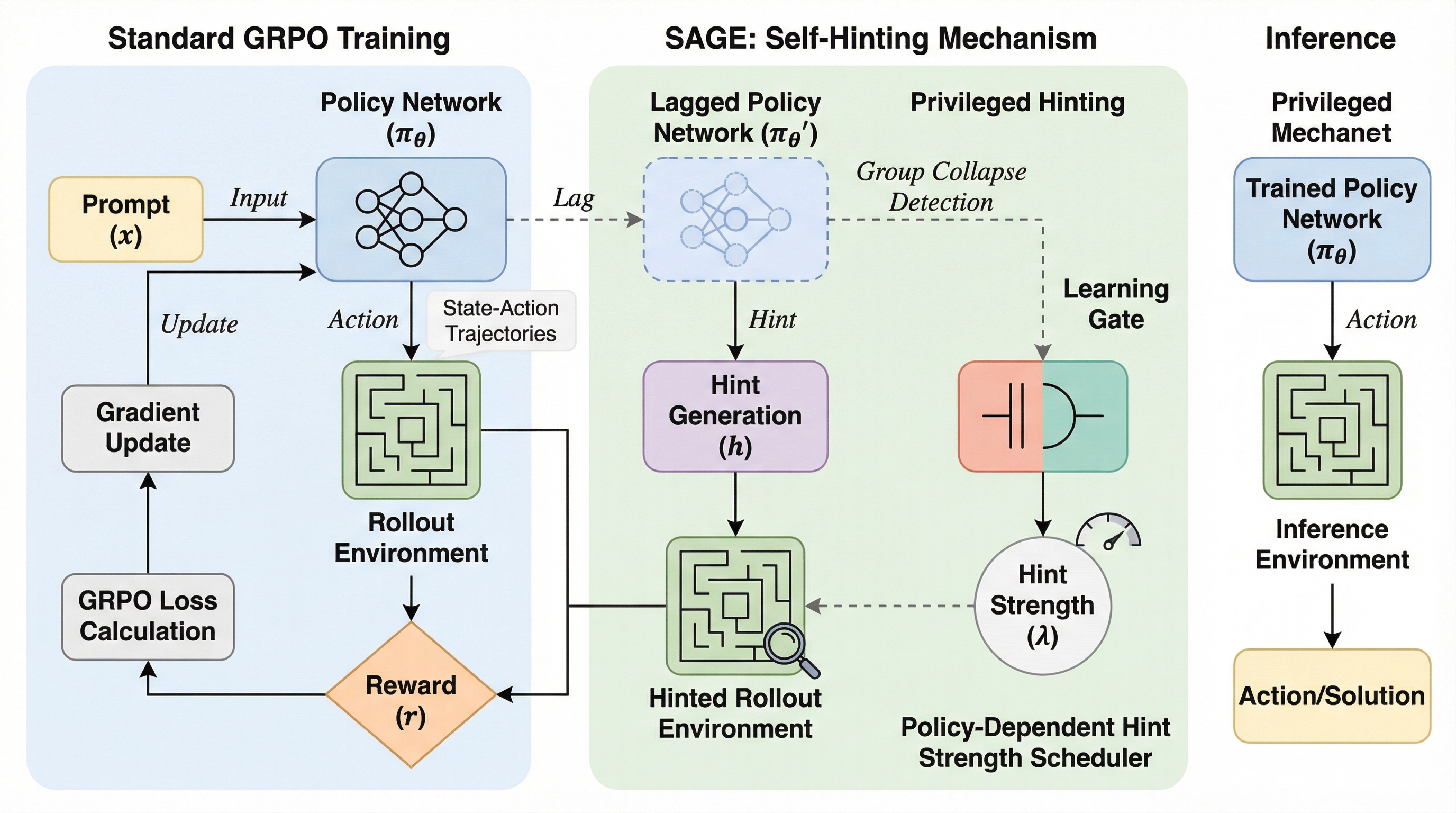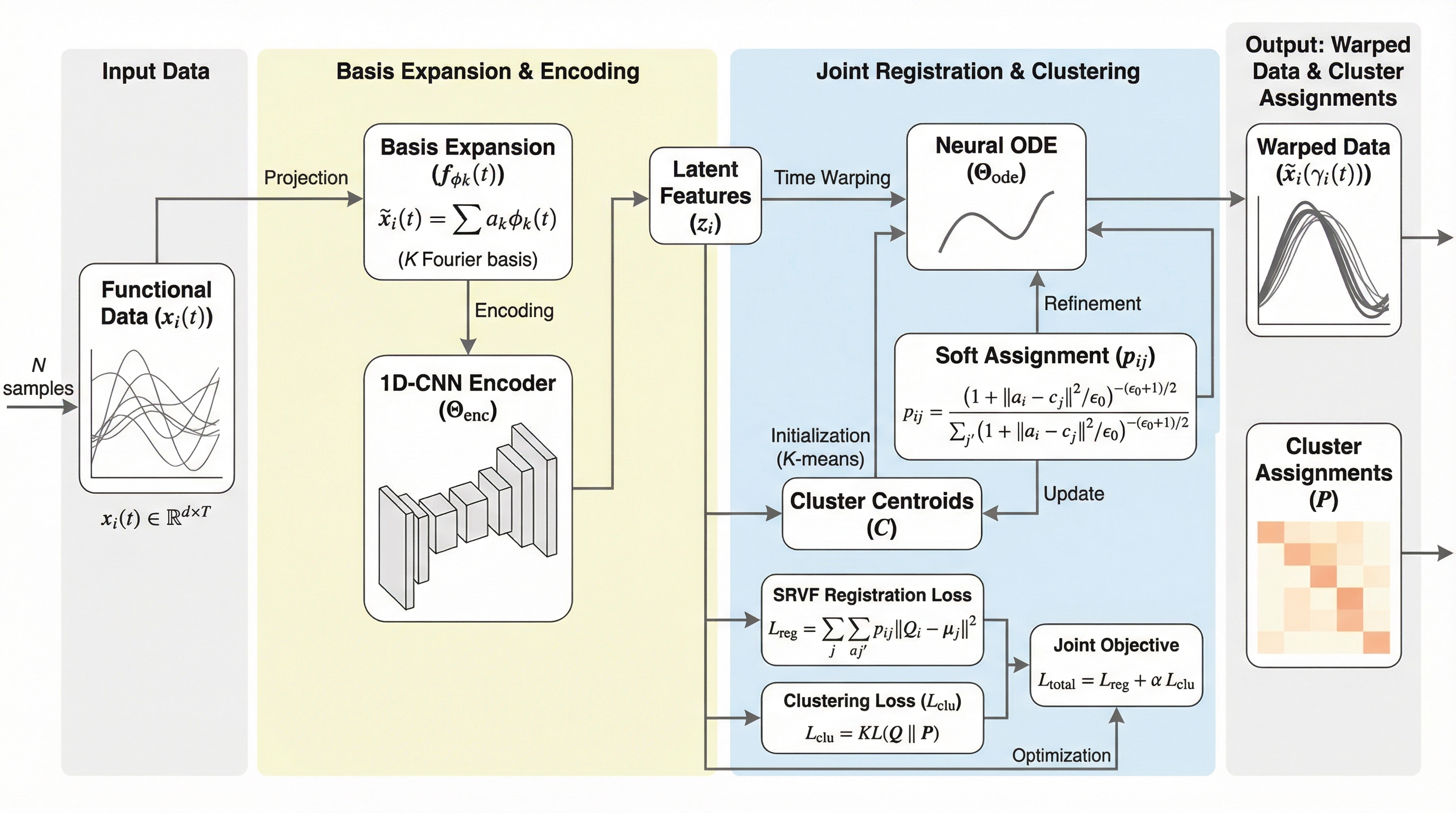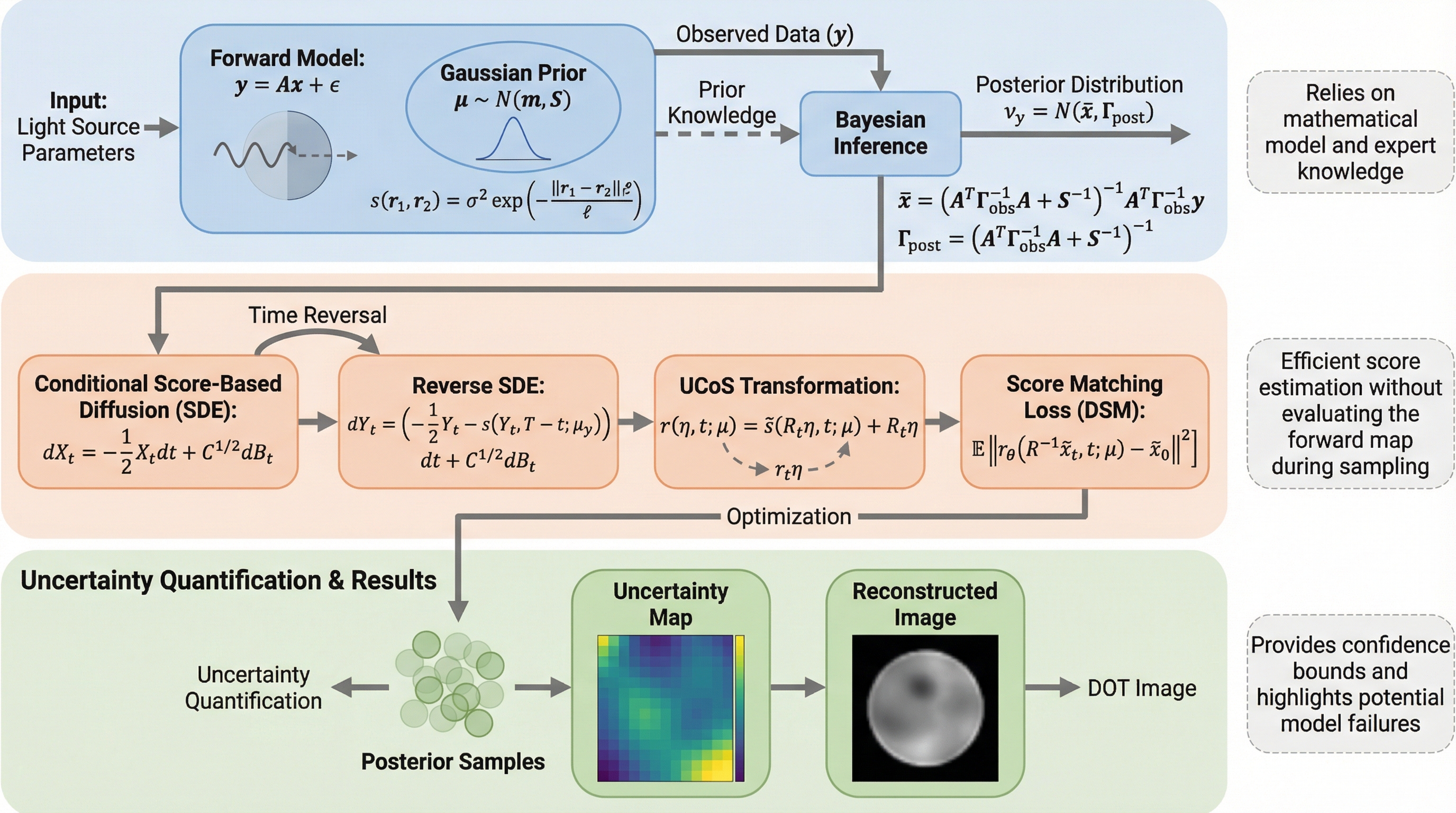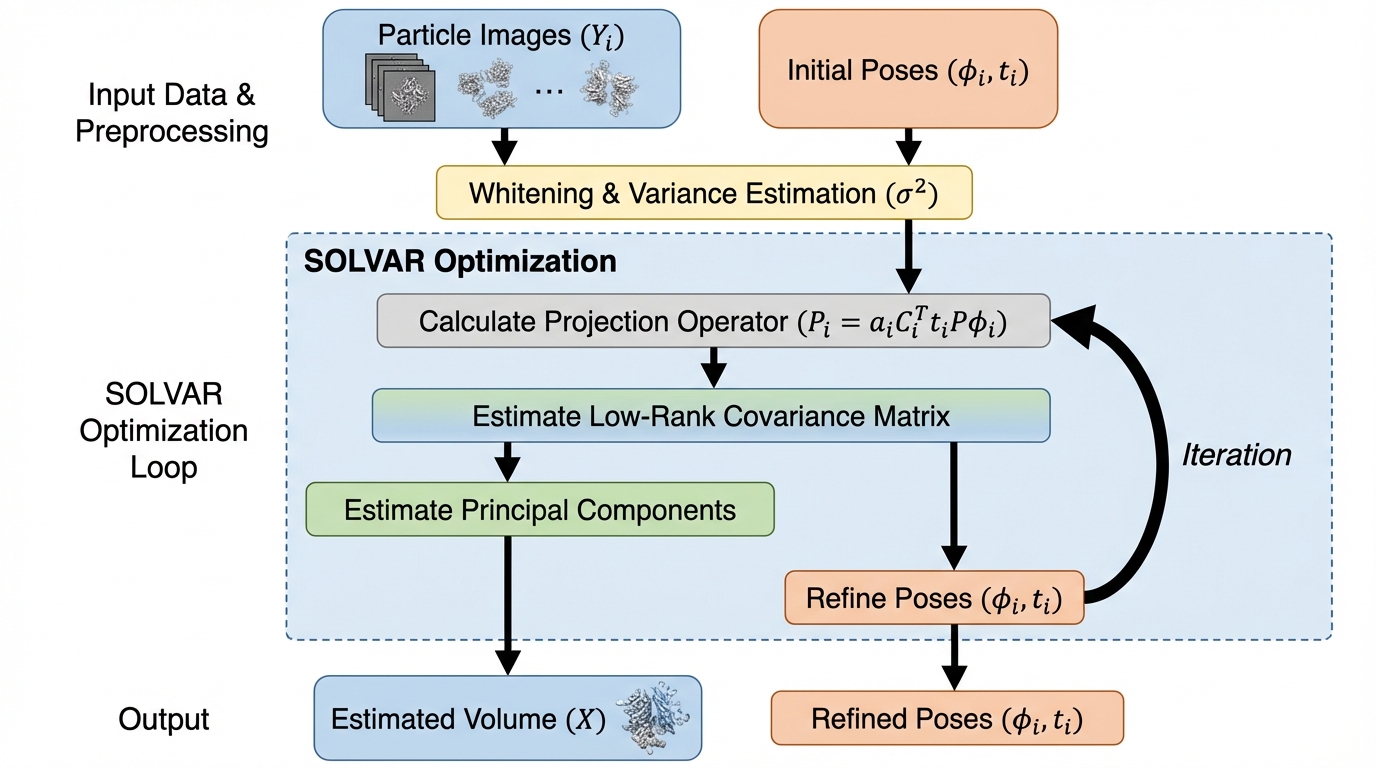
SOLVAR:クライオ電子顕微鏡の共分散ベース連続ヘテロ性解析を、低ランク最適化と姿勢精密化で実用化する
クライオ電子顕微鏡(cryo-EM)で分子が連続的に形を変えるとき、構造変動を共分散で捉える考え方は筋がよい一方、共分散行列が巨大すぎて主成分を実用的に推定しにくいという計算上の壁があります。 / SOLVARは共分散が低ランクという仮定を置き、共分散そのものではなく主成分(固有ベクトルに対応する基底体積)を目的変数にした最適化へ組み替え、確率的勾配法で素早く解く枠組みにしています。 / さらに粒子画像の姿勢(回転・平行移動)を推定途中で更新できるようにし、合成データと実データの実験で主要な変動成分を捉えつつ計算効率も維持し、最近のベンチマークでも複数データセットで高い成績を示したと述べています。