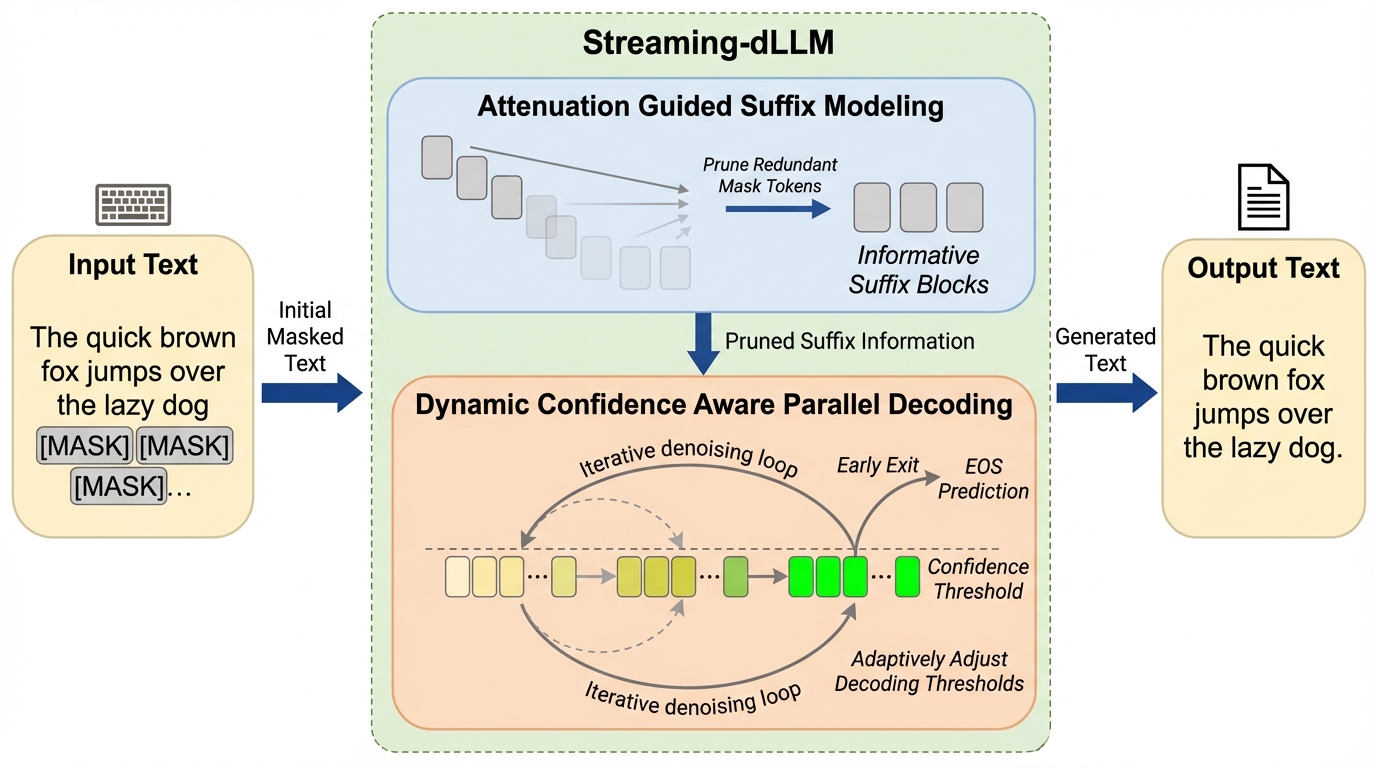
Streaming-dLLM:サフィックス剪定と動的デコーディングによる拡散LLMの加速
拡散大規模言語モデル(dLLM)は並列デコーディングと双方向アテンションにより高い一貫性を持つが、自己回帰型モデルと比較して推論速度が大幅に遅いという課題がある。 本研究が提案するStreaming-dLLMは、空間的な冗長性を排除する「減衰誘導サフィックスモデリング」と、時間的な非効率性を改善する「動的信頼度認識並列デコーディング」を導入した学習不要のフレームワークである。 検証の結果、生成品質を維持したまま最大68.2倍の推論加速を達成し、既存の手法を大幅に上回るスループットと競争力のある精度を両立することに成功した。