幾何学的推論器:長文脈推論のための多様体情報を活用した潜在的予見探索
大規模言語モデルの推論能力を向上させるための推論時計算量の拡張において、従来の強化学習やサンプリング手法は膨大な学習コストやメモリ消費、推論経路の重複といった深刻な課題を抱えていましたが、本研究が提案する「TGR(The Geometric Reasoner)」は、追加学習を一切必要とせず、推論過程をチャンク単位に分割してメモリ消費を抑えつつ、潜在空間での多様体情報を活用した「潜在的予見探索」を行う革新的なフレームワークです。 具体的には、推論を短いチャンクに分割し、各境界で潜在アンカーを抽出・サンプリングして、予見スコア、軌跡の滑らかさを表す凹凸ペナルティ、多様性を促す一様性正則化からなる幾何学的スコアで最適な経路を選択し、低ランクの残差注入によってモデルを制御することで、KVキャッシュのメモリ消費を文脈長に対して線形に保ちながら、長大で論理的一貫性のある多様な推論を効率的に生成することに成功しました。 Qwen3-8Bを用いた数学やコード生成の難解なベンチマークでの検証では、Pass@k曲線の曲線下面積(AUC)を最大13ポイント向上させ、計算負荷をわずか1.1倍から1.3倍程度に抑えつつ、既存の強化学習ベースの手法(GRPOやSimKO)を凌駕する高い網羅性と予算効率を実証しており、モデルの重みを更新することなく推論時の工夫のみで高度な探索を実現できる実用性の高い手法であることを示しました。
TL;DR(結論)
大規模言語モデルの推論能力を向上させるための推論時計算量の拡張において、従来の強化学習やサンプリング手法は膨大な学習コストやメモリ消費、推論経路の重複といった深刻な課題を抱えていましたが、本研究が提案する「TGR(The Geometric Reasoner)」は、追加学習を一切必要とせず、推論過程をチャンク単位に分割してメモリ消費を抑えつつ、潜在空間での多様体情報を活用した「潜在的予見探索」を行う革新的なフレームワークです。 具体的には、推論を短いチャンクに分割し、各境界で潜在アンカーを抽出・サンプリングして、予見スコア、軌跡の滑らかさを表す凹凸ペナルティ、多様性を促す一様性正則化からなる幾何学的スコアで最適な経路を選択し、低ランクの残差注入によってモデルを制御することで、KVキャッシュのメモリ消費を文脈長に対して線形に保ちながら、長大で論理的一貫性のある多様な推論を効率的に生成することに成功しました。 Qwen3-8Bを用いた数学やコード生成の難解なベンチマークでの検証では、Pass@k曲線の曲線下面積(AUC)を最大13ポイント向上させ、計算負荷をわずか1.1倍から1.3倍程度に抑えつつ、既存の強化学習ベースの手法(GRPOやSimKO)を凌駕する高い網羅性と予算効率を実証しており、モデルの重みを更新することなく推論時の工夫のみで高度な探索を実現できる実用性の高い手法であることを示しました。
なぜこの問題か
大規模言語モデル(LLM)において、思考連鎖(Chain-of-Thought)を長く展開し、推論時の計算量を増やすことは、モデルの潜在的な能力を引き出すための極めて有効な手段として注目されています。しかし、長大な推論過程を探索しようとすると、トランスフォーマーモデル特有の注意機構(Attention)の計算複雑性が入力長の二次関数的に増大するという根本的な問題に直面します。これに伴い、キー・バリュー(KV)キャッシュのメモリ占有量も膨大になり、実用的なリソースの範囲内で長い推論経路を効率的に探索することは技術的に非常に困難でした。既存のアプローチとしては、強化学習(RL)や選好最適化を用いて長期的な制御能力をモデルの重みに直接学習させる手法がありますが、これらは膨大な計算リソースと時間を要するだけでなく、生成される推論のバリエーションが特定のパターンに偏る「モード崩壊」を引き起こすリスクがあり、推論の多様性が失われやすいという欠点があります。…
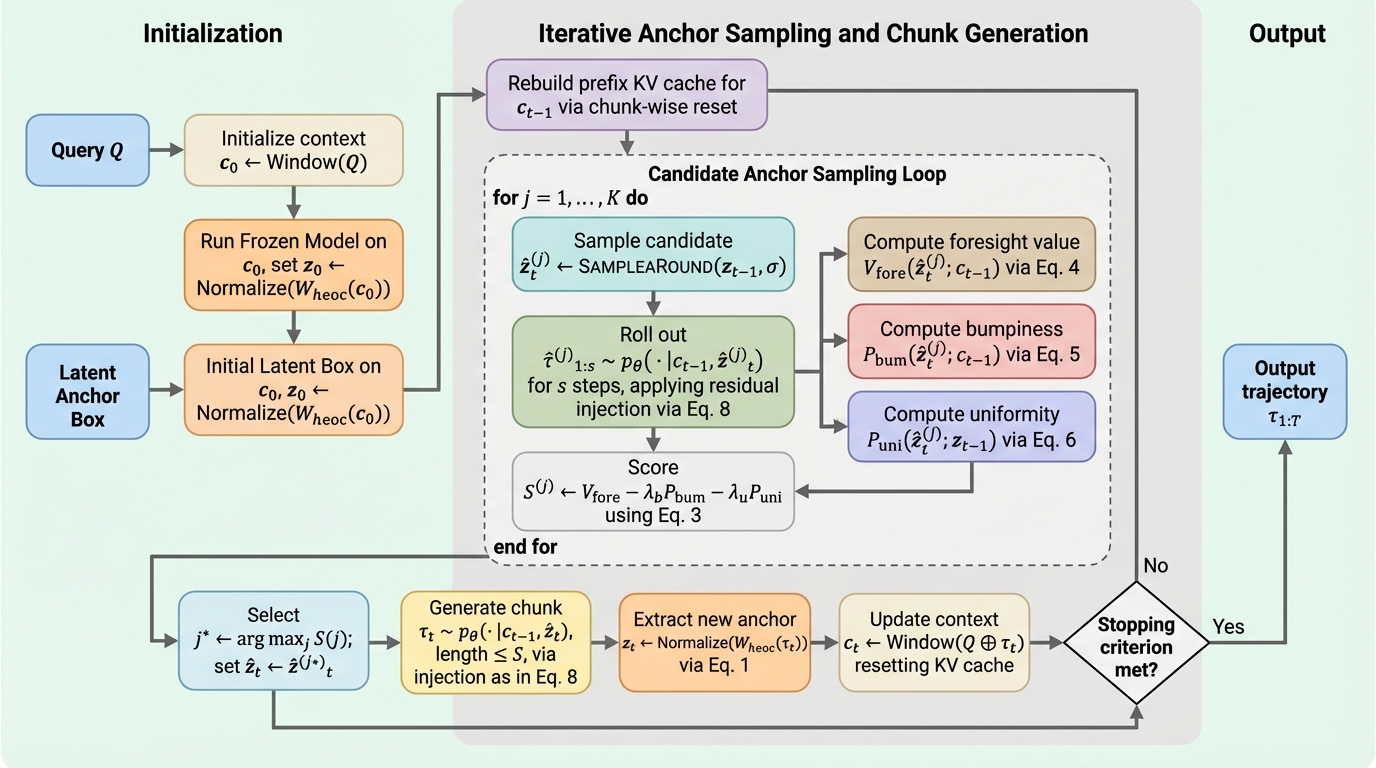
核心:何を提案したのか
本研究では、モデルのパラメータ更新を一切必要とせず、推論時に潜在空間(Latent Space)での高度な探索を可能にする幾何学的推論器「The Geometric Reasoner(TGR)」を提案しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related