有向スキルグラフと選択的適応によるアクションRPGにおける転移可能なスキルの学習
本研究では、複雑なアクションRPG『Dark Souls III』の戦闘を「カメラ操作」「ターゲットロック」「移動」「回避」「回復・攻撃判断」という5つの再利用可能なスキルに分解し、それらを有向スキルグラフとして構造化することで、従来の単一ネットワーク手法を圧倒する学習効率と環境適応能力を実現しました。
TL;DR(結論)
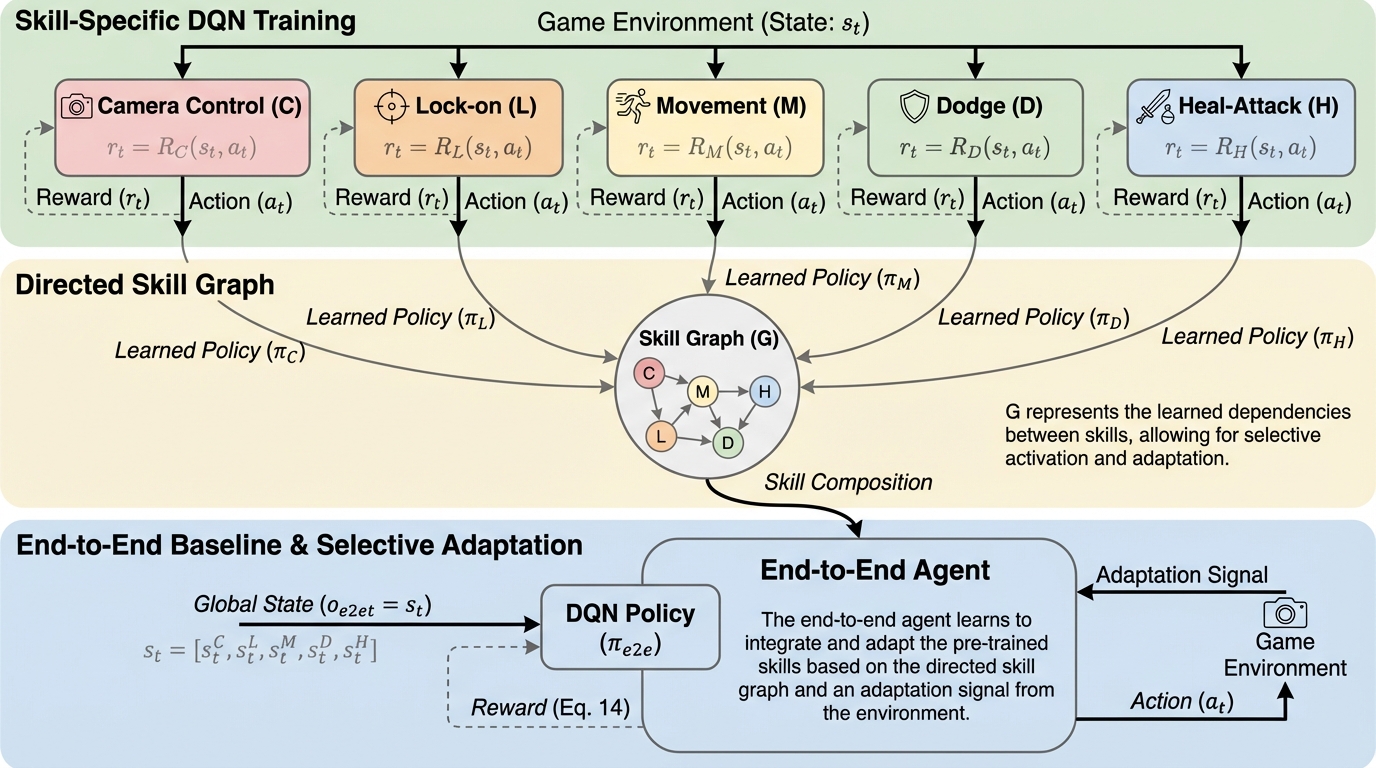
本研究では、複雑なアクションRPG『Dark Souls III』の戦闘を「カメラ操作」「ターゲットロック」「移動」「回避」「回復・攻撃判断」という5つの再利用可能なスキルに分解し、それらを有向スキルグラフとして構造化することで、従来の単一ネットワーク手法を圧倒する学習効率と環境適応能力を実現しました。 階層的なカリキュラム学習を採用し、上流の基礎スキルを固定したまま下流の専門スキルを訓練することで、ボスの形態変化(フェーズ移行)のような環境の変化に対しても、全ての機能を再学習することなく特定のモジュールのみを選択的に微調整するだけで迅速に性能を回復させることに成功しています。 実験の結果、提案手法は統合型エージェントが全く学習できなかった条件下で44%の勝率を記録し、さらに環境変化後の微調整によって勝率を52%まで向上させるなど、複雑なリアルタイム環境における継続的な学習とスキルの転移において、モジュール化と構造化された依存関係が極めて有効であることを実証しました。
なぜこの問題か
生涯学習(Lifelong Learning)を行うエージェントにとって、過去に習得した知識や行動を破壊的に上書きしたり、新しい環境に直面するたびにゼロから再学習したりすることなく、時間の経過とともに能力を拡張していくことは人工知能研究における長年の重要課題です。しかし、現代のビデオゲーム、特にアクションRPGのような複雑なリアルタイム制御が要求される領域では、この目標の達成は非常に困難です。アクションRPGは、ミリ秒単位のタイトな反応ループ、画面外の情報を考慮する必要がある部分的な観測性、そして行動の結果が報酬として現れるまでに時間がかかる長期的な報酬割り当ての問題を含んでいます。さらに、敵の動きに合わせて位置を調整しながら攻撃や防御を選択するという、互いに密接に結合した複数のサブ問題を同時に解かなければなりません。 従来の深層強化学習では、単一の巨大なニューラルネットワーク(モノリシックなポリシー)を用いて、入力から出力までをエンドツーエンドで学習させる手法が一般的でした。しかし、このような手法はサンプル効率が極めて悪く、タスクや環境がわずかに変化しただけで性能が劇的に低下するという脆弱性を持っています。…
核心:何を提案したのか
本論文の核心的な提案は、戦闘制御を有向スキルグラフ(Directed Skill Graph)として表現し、その構成要素を階層的なカリキュラムに沿って訓練するモジュール型エージェントの構築です。このエージェントは、複雑な戦闘行動を「カメラ操作(C)」、「ターゲットロック(L)」、「移動・位置取り(M)」、「回避(D)」、「回復・攻撃の意思決定(H)」という5つの独立した、かつ再利用可能なスキルモジュールに分解します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related