文化的アーカイブとしてのLLM:文化的常識ナレッジグラフの抽出
大規模言語モデル(LLM)が学習データの中に保持している、特定の文化に固有の常識や慣習を「もし〜ならば、次に〜する」という形式の推論チェーンとして体系的に抽出する新しいフレームワーク「CCKG」を開発した。
TL;DR(結論)
大規模言語モデル(LLM)が学習データの中に保持している、特定の文化に固有の常識や慣習を「もし〜ならば、次に〜する」という形式の推論チェーンとして体系的に抽出する新しいフレームワーク「CCKG」を開発した。 中国、インドネシア、日本、イギリス、エジプトの5カ国を対象に、文化的な妥当性や論理的一貫性を現地の母国語話者が評価した結果、非英語圏の文化であっても母国語より英語で抽出した方が高品質な知識が得られるという、モデル内部の文化的な偏りが明らかになった。 抽出された構造的な文化知識を小規模な言語モデルに組み込むことで、文化的な文脈を考慮した高度な推論や物語生成が可能になり、LLMを単なる計算機ではなく「文化のアーカイブ」として活用する有効性と現在の技術的な限界を実証した。
なぜこの問題か
文化と常識的な推論は密接に結びついており、人々が日常の出来事や社会的な慣習、因果関係をどのように解釈するかを決定づける重要な要素である。常識とは、すべての人間にとって共通の普遍的な論理ではなく、それぞれのコミュニティが共有する文化的な経験に基づいている。そのため、ある文化圏で当然とされることが、別の文化圏では全く理解されなかったり、誤解を招いたりすることが少なくない。これまでの大規模言語モデルの研究では、物理的な常識や社会的な推論を文化的に中立なものとして扱う傾向が強かったが、実際には言語や認知のバリエーションが地域ごとに大きく存在している。初期の常識ナレッジベースであるATOMICなどは、日常的な出来事の間の推論をモデル化する重要性を示したが、これらは主に西洋中心的な視点で構築されており、異文化間での汎用性に欠けていた。 LLMはウェブ上の膨大なデータから多様な文化的知識を学習しているが、その知識の多くは明示的に整理されておらず、モデルの内部に構造化されないまま隠れている。このため、モデルがどのような文化的な前提に基づいて回答しているのかを解釈することが難しく、特定の文化に深く根ざした応用も制限されていた。…
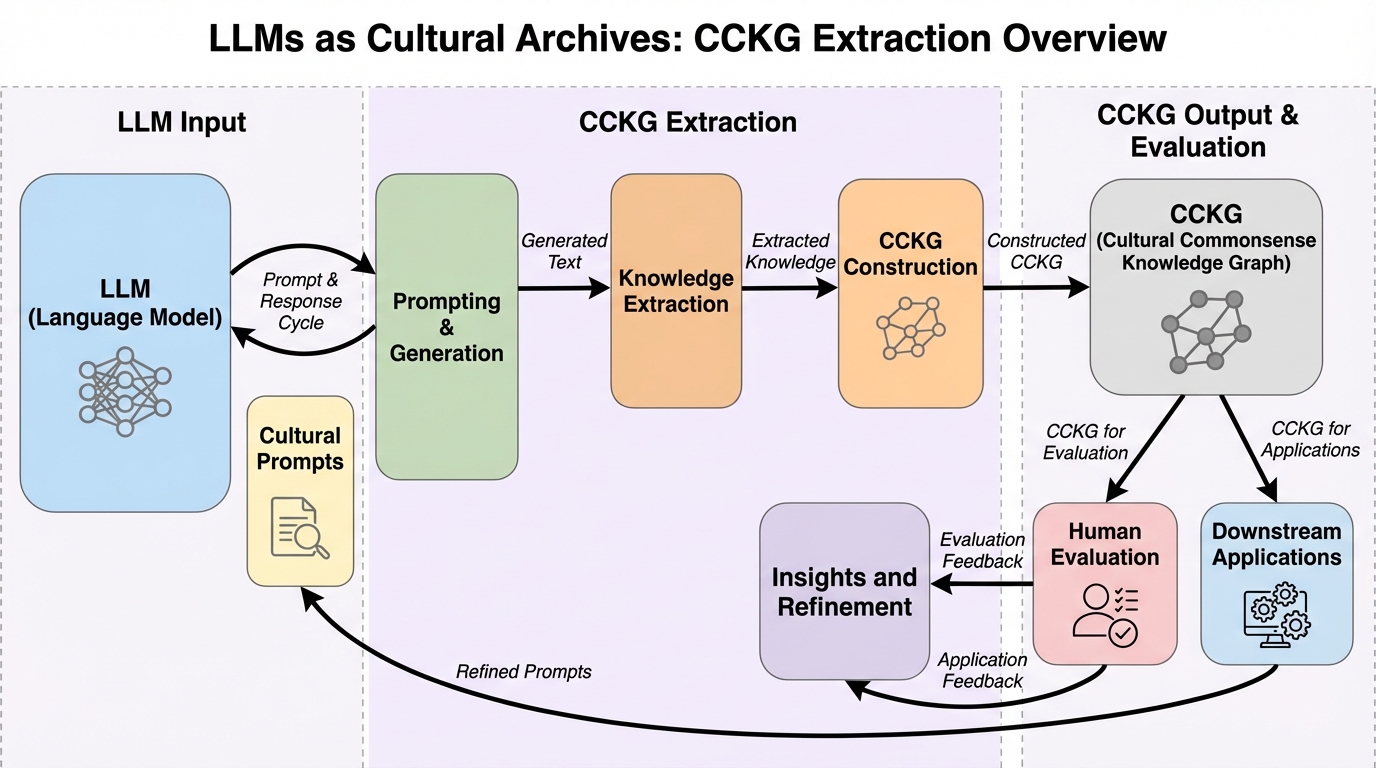
核心:何を提案したのか
本研究では、LLMから多言語かつ文化固有の「if-then」形式の推論知識を抽出するための、反復的なプロンプトベースのフレームワークである「文化的常識ナレッジグラフ(CCKG)」を提案した。このフレームワークは、LLMを膨大な文化情報が蓄積されたアーカイブとして扱い、特定の文化に関連するエンティティ、関係性、および慣習を体系的に引き出し、それらを言語の壁を越えた多段階の推論チェーンとして構成するものである。CCKGは、既存のATOMICスタイルの定式化を拡張し、人間の行動、意図、およびその結果を含む推論の流れをグラフ構造でモデル化する。具体的には、中国、インドネシア、日本、イギリス、エジプトの5カ国を対象とし、それぞれの国の母国語と英語の両方を用いて知識の抽出と構造化を試みた。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related