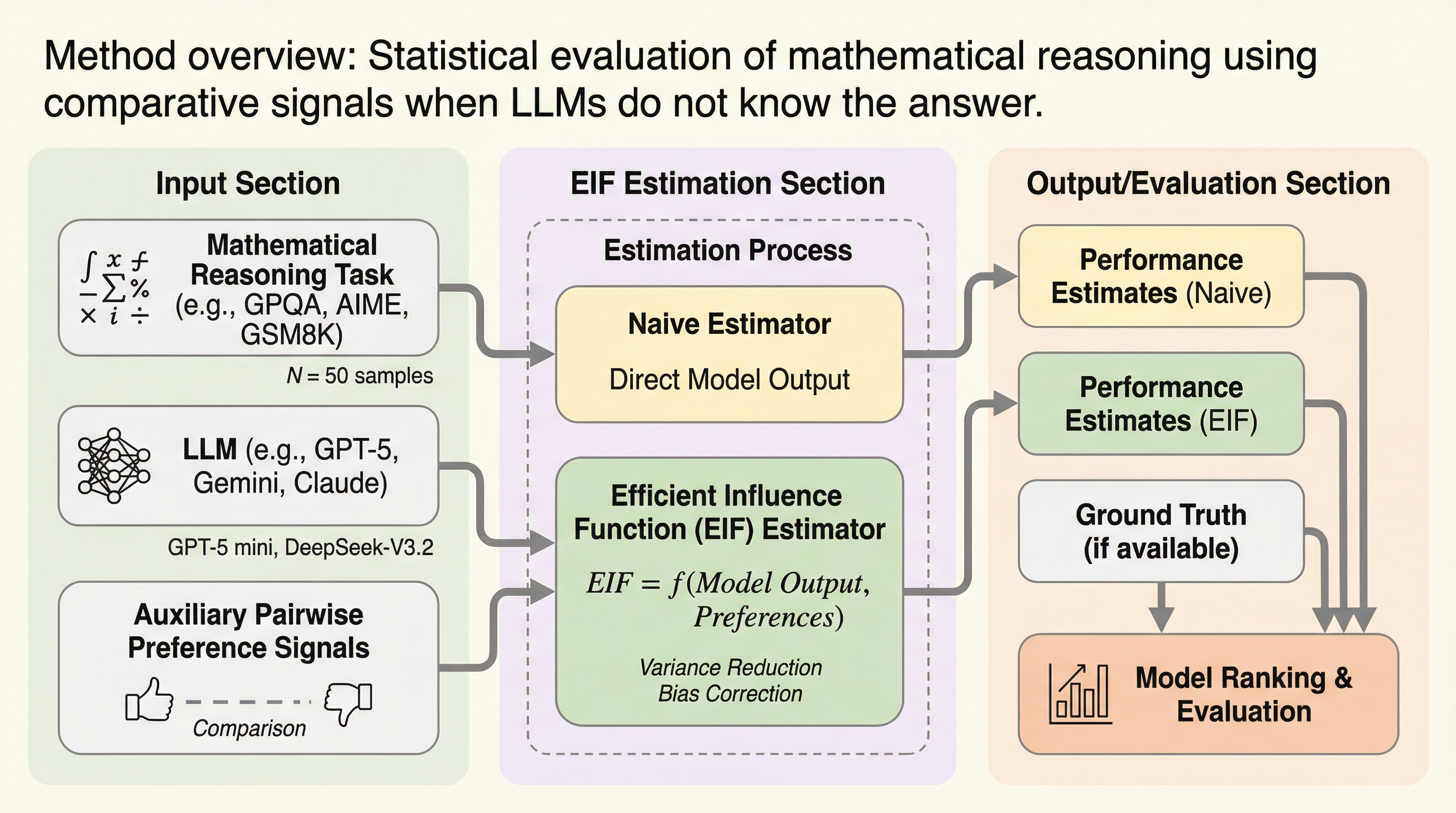
LLMが答えを知らない場合の評価:比較信号を用いた数学的推論の統計的評価
大規模言語モデル(LLM)の数学的推論能力の評価において、ベンチマークのサイズ制限とモデルの確率的な変動が原因で、評価結果の分散が大きくなりランキングが不安定になる「再現性の危機」を解決するための統計的枠組みを提案した。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデル(LLM)の数学的推論能力の評価において、ベンチマークのサイズ制限とモデルの確率的な変動が原因で、評価結果の分散が大きくなりランキングが不安定になる「再現性の危機」を解決するための統計的枠組みを提案した。
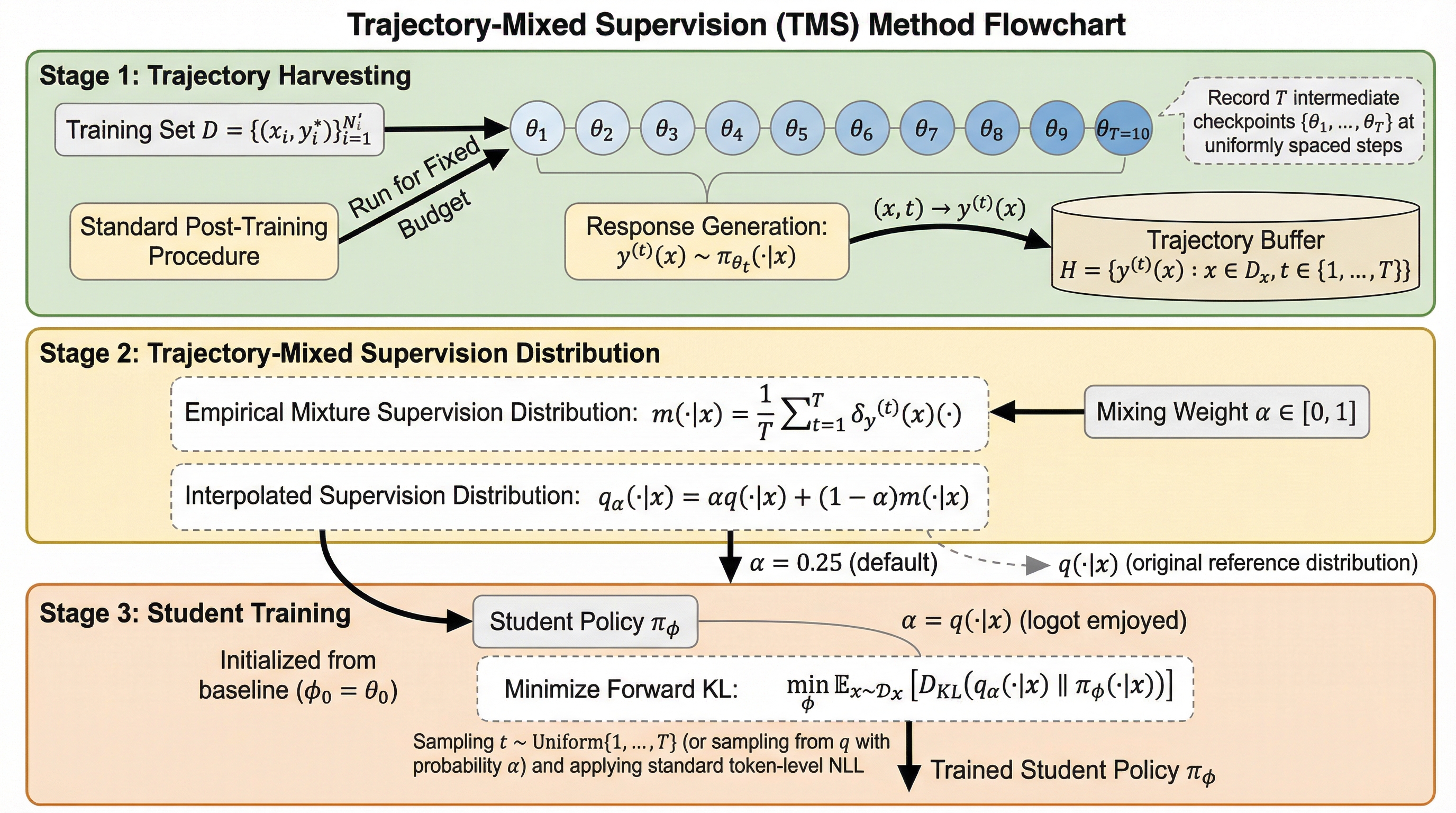
大規模言語モデルの微調整(SFT)において、モデルの進化と固定されたラベルの乖離が原因で発生する「教師の不一致」と、それによる能力の喪失(忘却)という課題を解決するための新しい枠組みであるTMSを提案した。
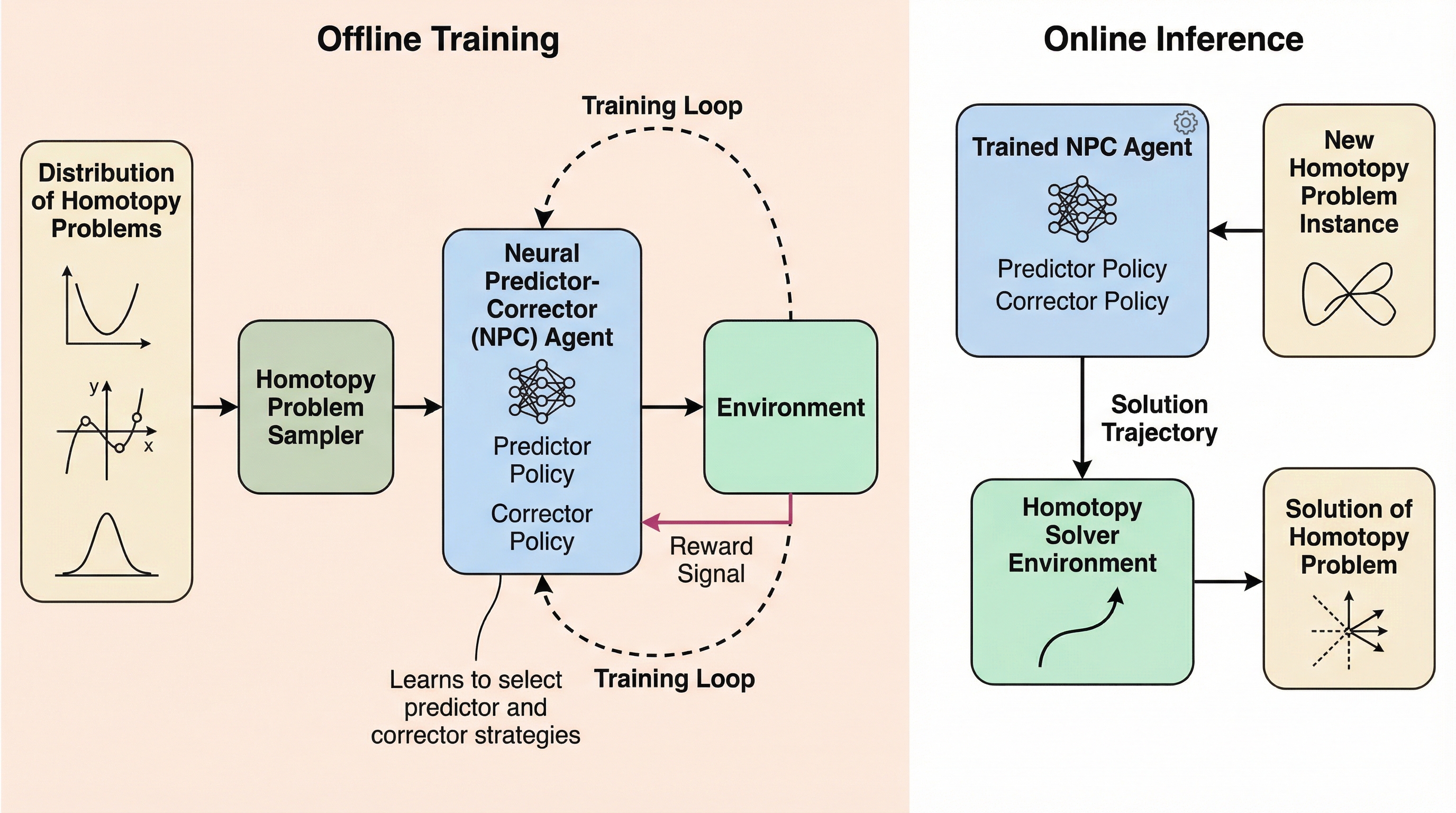
ホモトピー法は、単純な問題の解を複雑なターゲット問題へと連続的に変形させながら追跡する強力な枠組みであるが、従来のソルバーはステップサイズや反復終了条件を人間が設計した固定的なルールに依存しており、効率性と汎用性に限界があった。
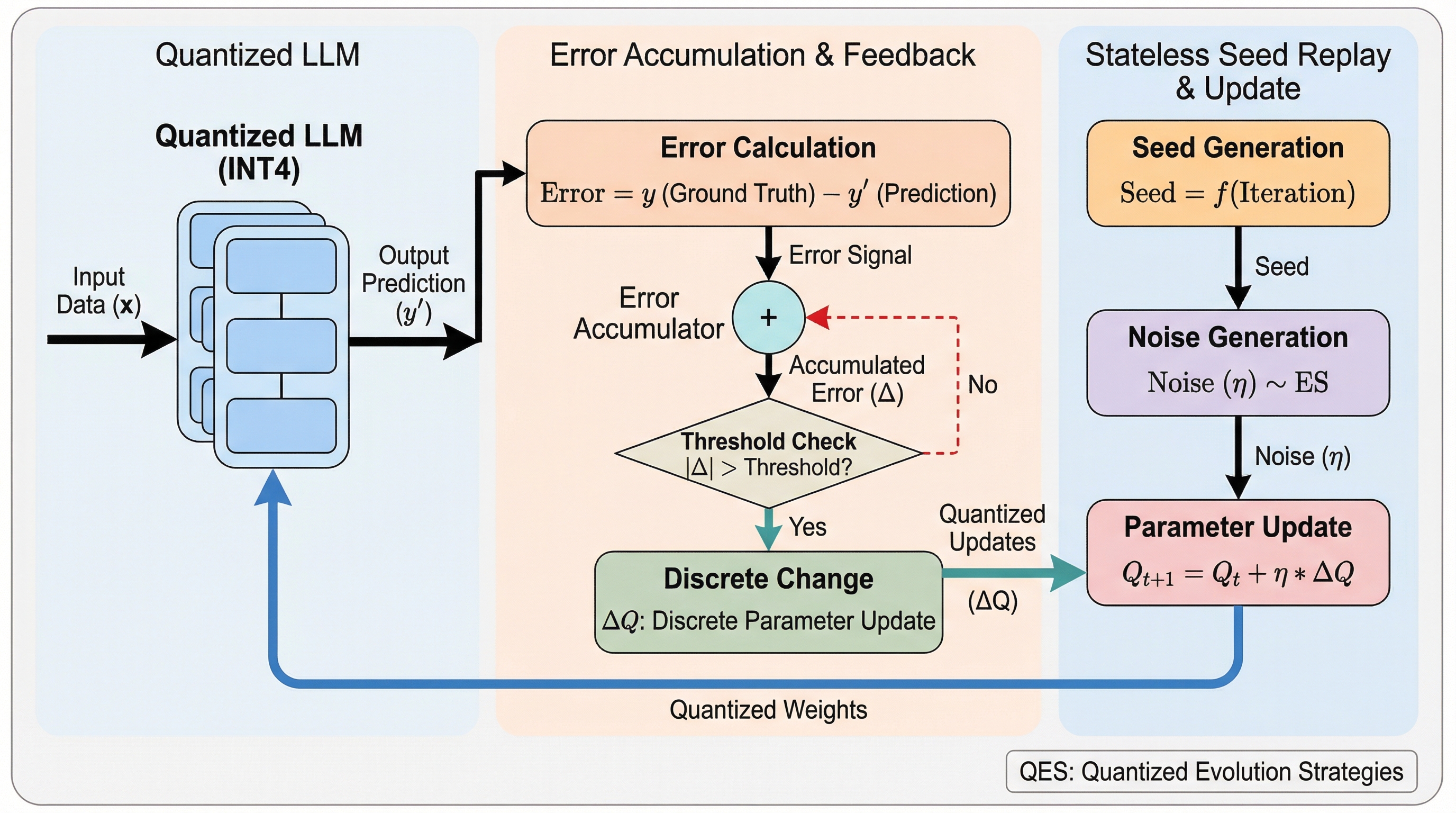
大規模言語モデル(LLM)のメモリ消費を抑えるポストトレーニング量子化(PTQ)モデルは、離散的かつ非微分的な性質から微調整が困難でしたが、本研究は信号処理のデルタ・シグマ変調に着想を得た「量子化進化戦略(QES)」を提案し、全パラメータの直接更新を可能にしました。
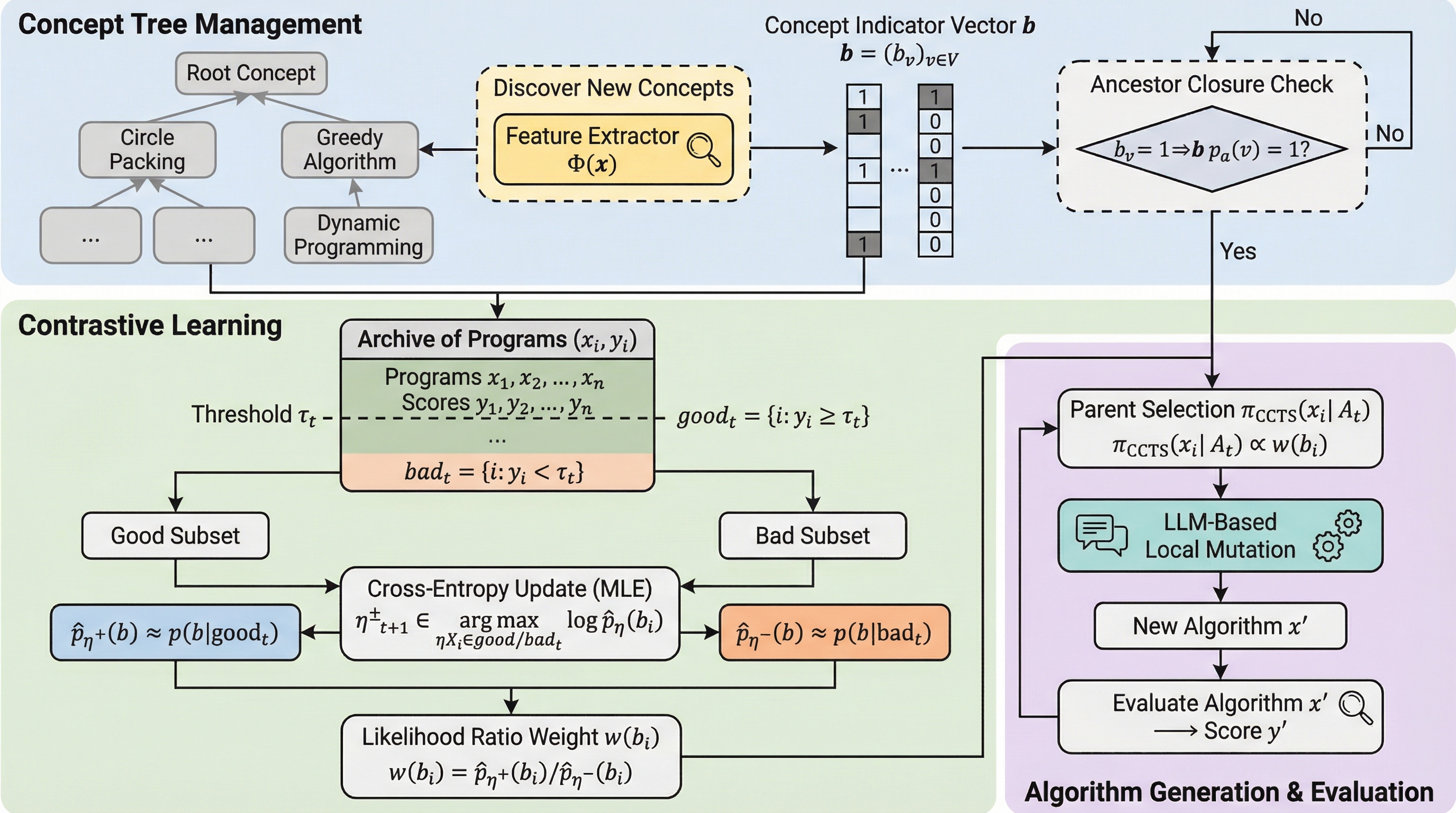
大規模言語モデル(LLM)を用いたアルゴリズム発見は、プログラム空間における反復的な最適化プロセスであるが、プログラム空間自体の構造が脆弱であるため、効率的な探索が困難であった。本研究では、生成されたプログラムから階層的な意味的概念を抽出し、高性能な解と低性能な解を対照的にモデル化することで親プログラムの選択を導く「対照的概念ツリー探索(CCTS)」を提案した。実験の結果、CCTSは組合せ数学の問題において従来手法を上回る探索効率を示し、特に「どの概念を避けるべきか」を学習することが性能向上に大きく寄与していることを明らかにした。
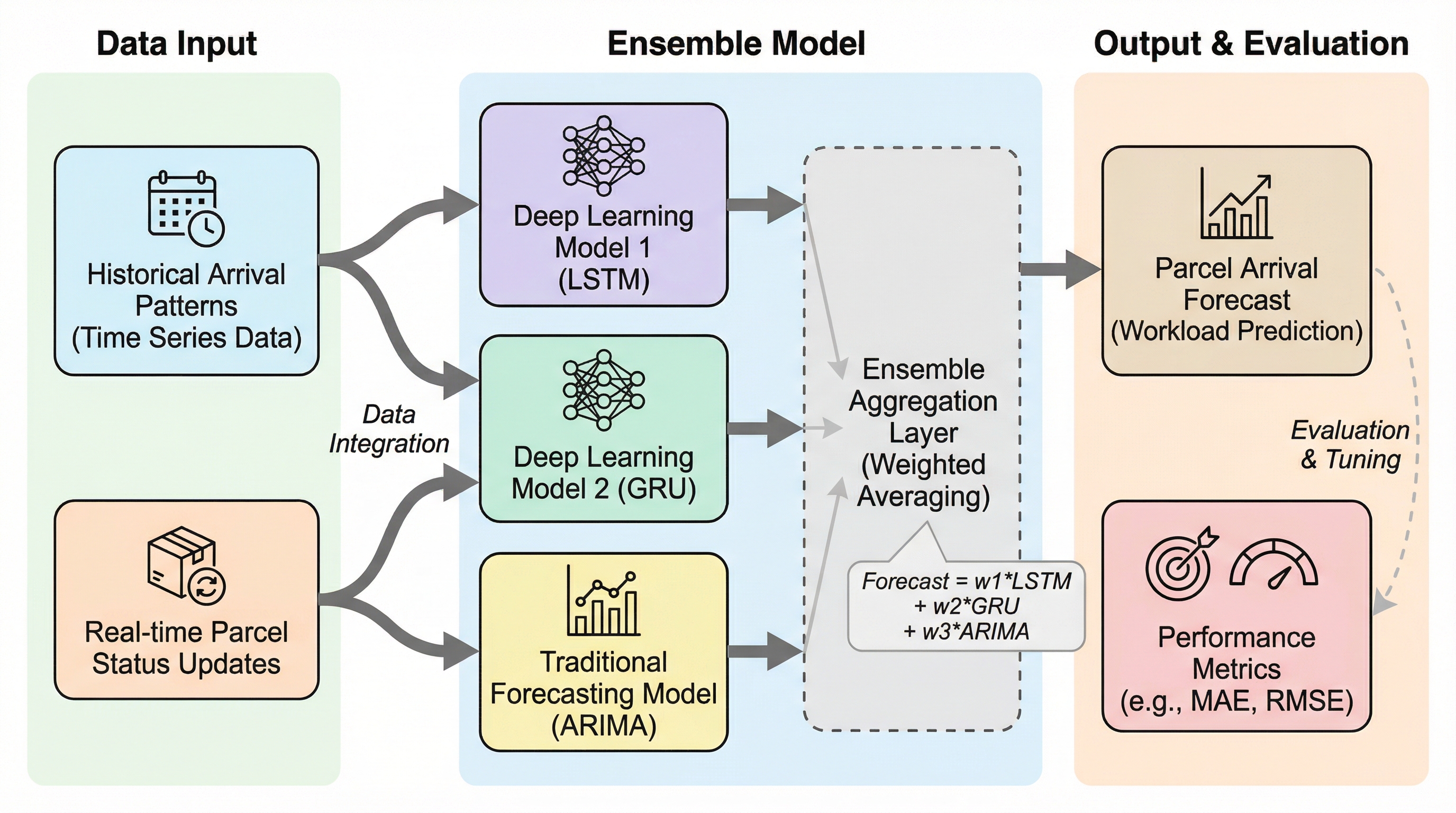
オンラインショッピングの爆発的普及とパンデミックの影響により、物流拠点の負荷を正確に予測し配送遅延を防ぐことが喫緊の課題となっており、本研究は過去のデータに基づく未注文荷物の予測とリアルタイムの追跡情報を活用した注文済み荷物の到着予測を統合する革新的なアンサンブル深層学習フレームワークを提案しました。
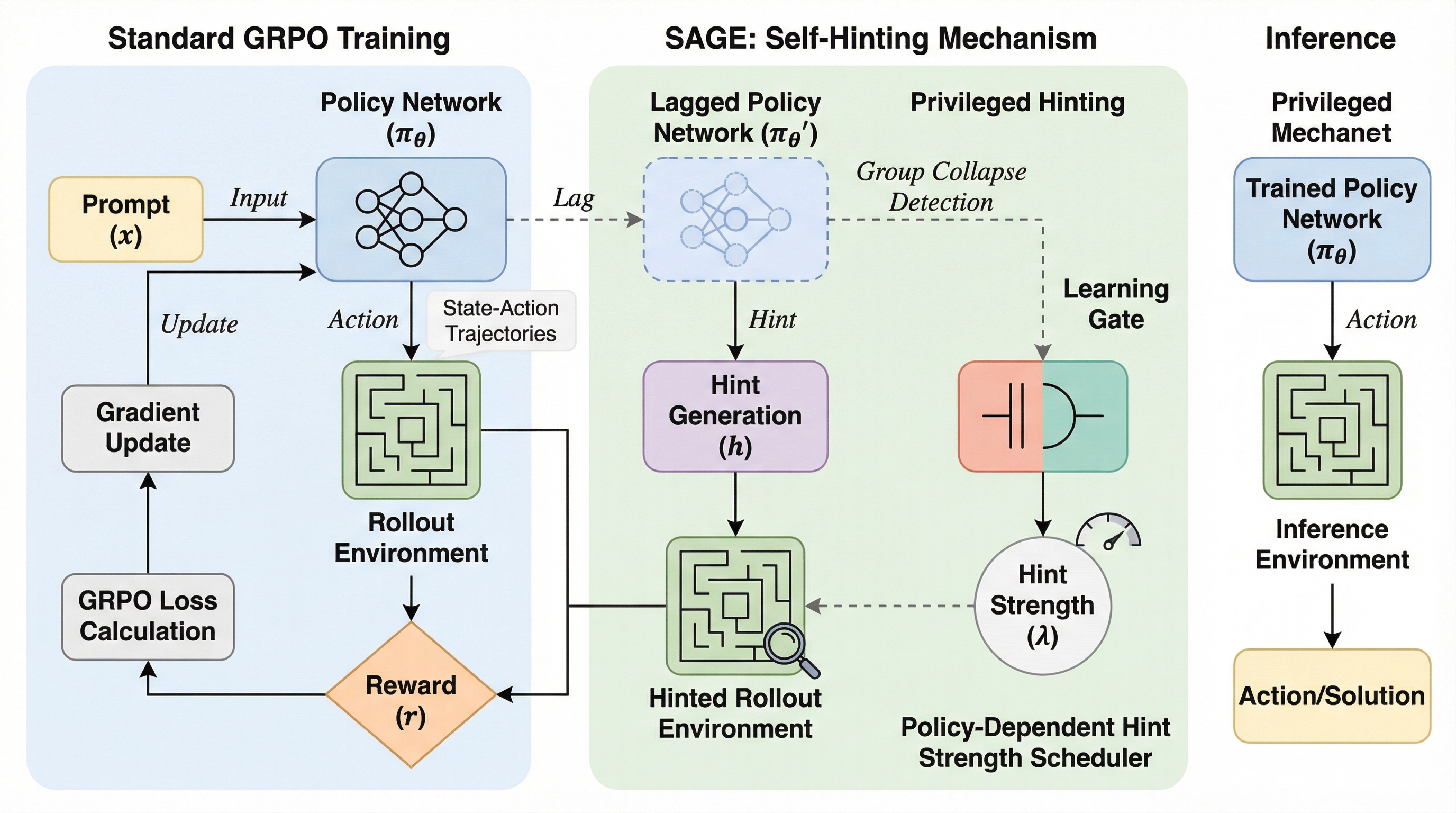
大規模言語モデルの強化学習において、難易度の高い問題で正解が全く得られず学習が停滞する「アドバンテージの崩壊」を解決するため、訓練時のみ「特権的なヒント」を導入する新手法「SAGE」が提案されました。
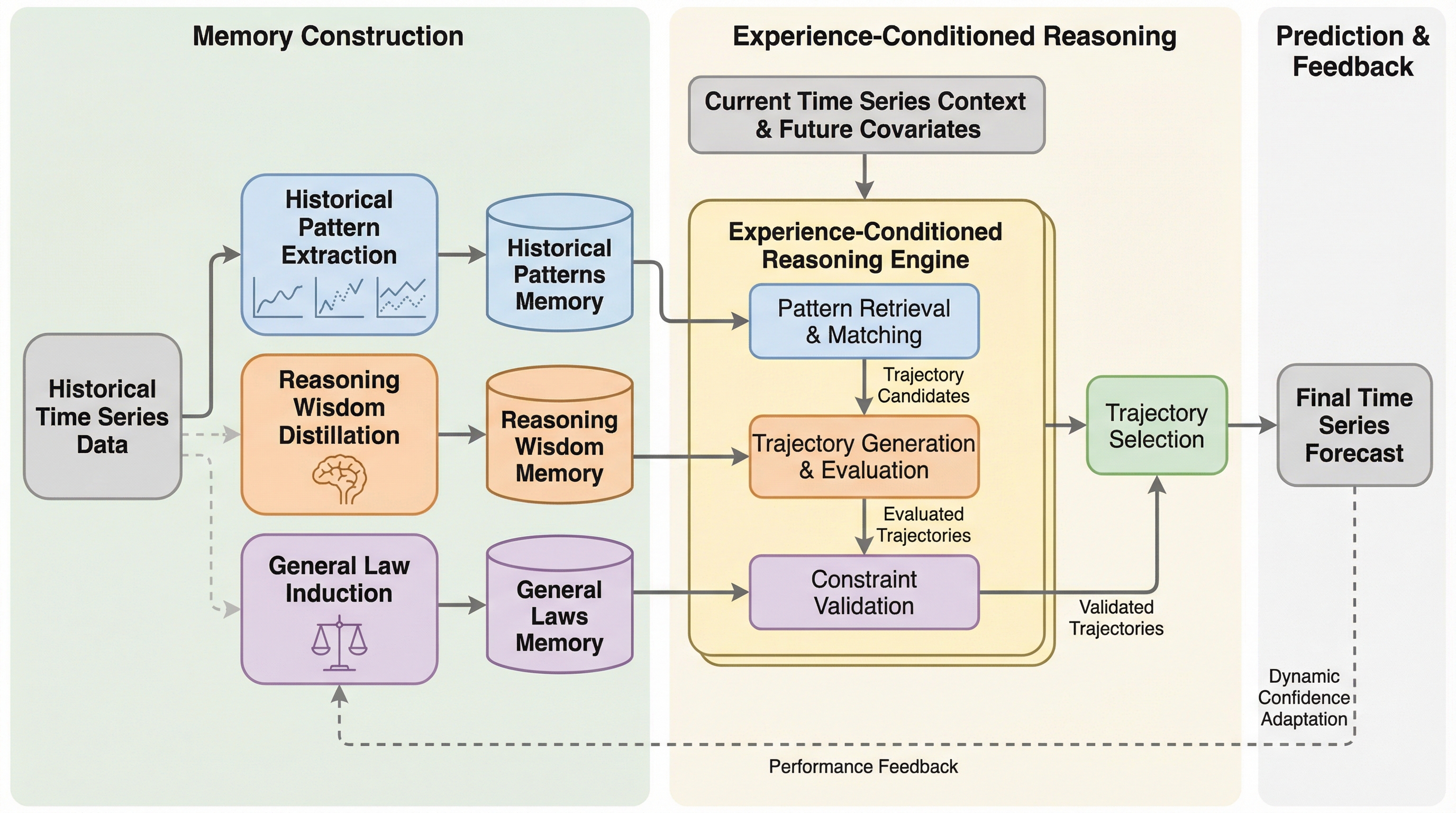
MemCastは、時系列予測を単なる数値回帰ではなく、過去の経験を条件とした推論タスクとして再定義し、大規模言語モデルに階層的な外部メモリを統合した新しいフレームワークである。 学習データから「歴史的パターン」「推論の知恵」「一般法則」の3層からなる構造化されたメモリを構築し、推論時にこれらを動的に参照・反映させることで、モデルの重みを再学習することなく高い精度と環境適応力を実現した。 電力価格、エネルギー発電量、河川流量などの多様な実データを用いた検証において、従来の統計手法や最新の深層学習モデルを一貫して上回る性能を示し、運用を通じた継続的な自己進化を可能にしている。
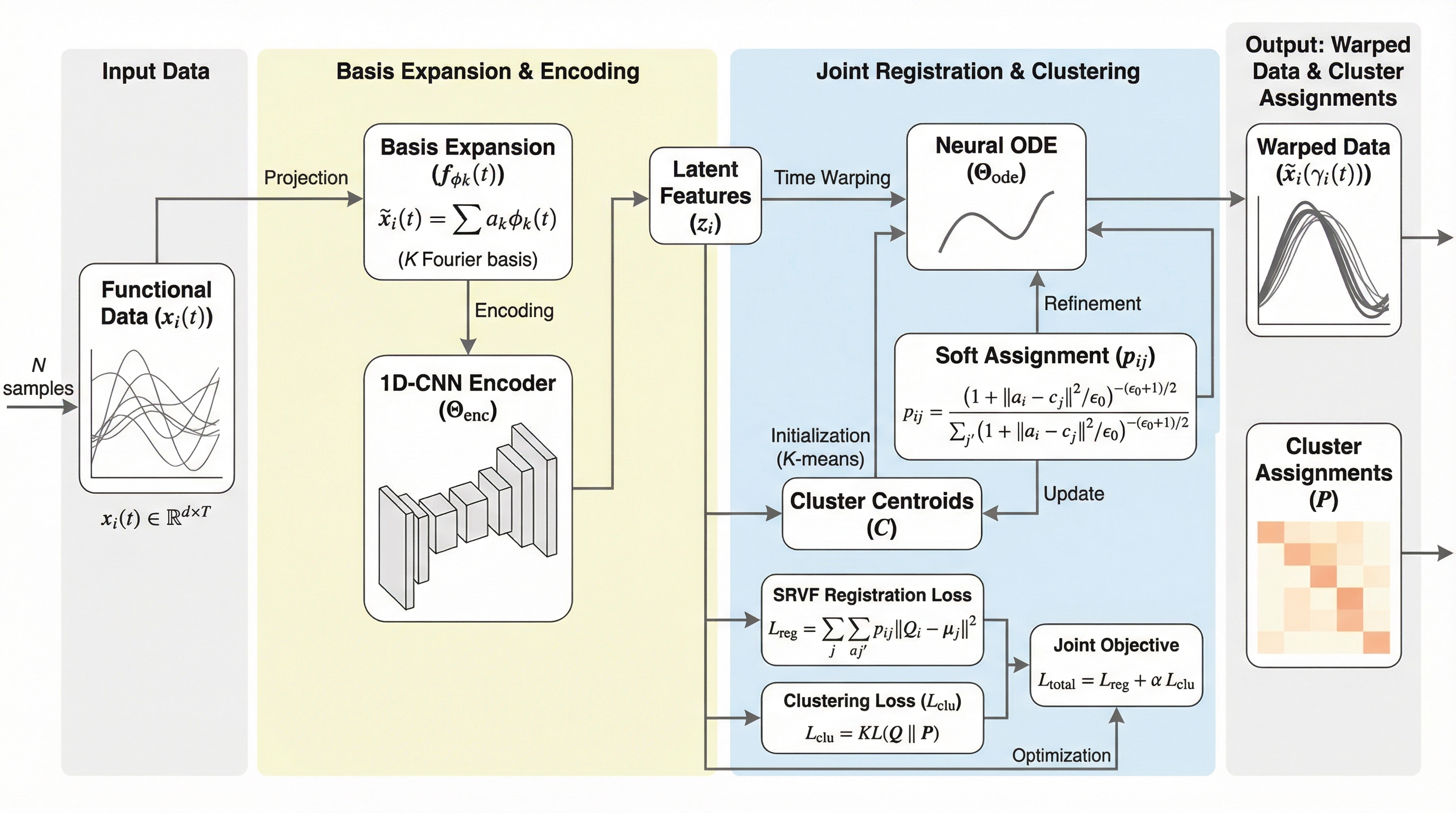
NeuralFLoCは、時間的なずれ(位相変動)を伴う関数データを高精度に分類するために開発された、完全教師なしの深層学習フレームワークである。Neural ODE(神経常微分方程式)を活用して滑らかで逆変換可能な微分同相の時間歪み関数を学習し、スペクトルクラスタリングと統合することで、データの位置合わせとグループ化を同時に最適化する。従来の段階的な手法や制約の強いモデルとは異なり、欠損値やノイズに対する堅牢性を備えつつ、大規模なデータセットに対しても線形時間での計算スケーラビリティを実現している。
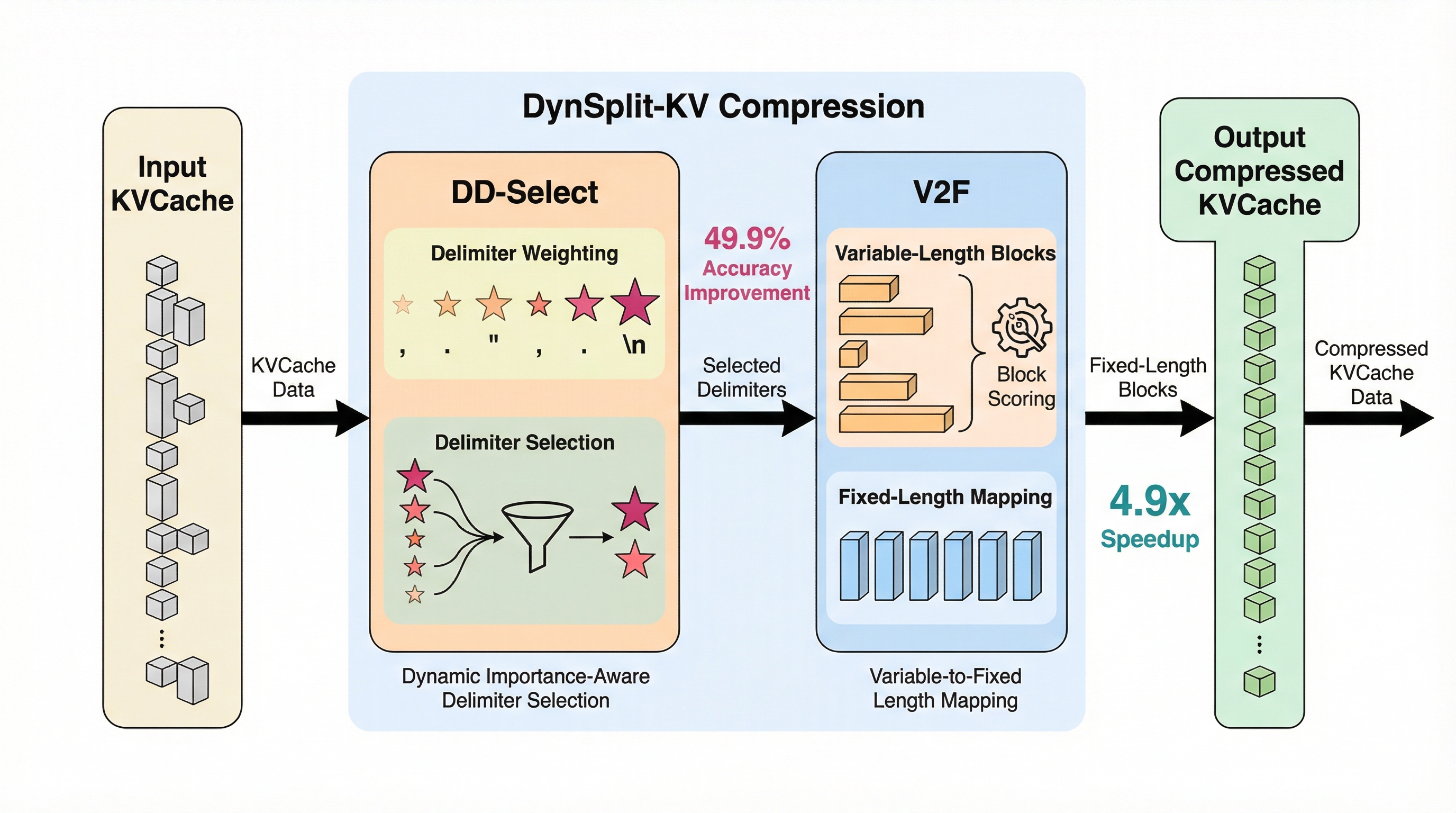
大規模言語モデルの長文推論において、従来の固定長や固定区切り文字によるKVキャッシュ分割は、文脈ごとの意味境界を無視するため最大55.1%もの大幅な精度低下を招くという深刻な課題がありましたが、本研究はこれを解決する動的分割手法を提案しました。